MANUALIA UNIVERSITATIS STUDIORUM ZAGRABIENSIS
UDŽBENICI SVEUČILIŠTA U ZAGREBU
2
Nakladnik:
Kineziološki fakultet Sveučilišta u Zagrebu
Za nakladnika:
prof. dr. sc. Dinko Vuleta, dekan
Recenzenti:
prof. dr. sc. Nataša Viskić-Štalec, Kineziološki fakultet
Sveučilišta u Zagrebu
prof. dr. sc. Milko Mejovšek, Edukacijsko-rehabilitacijski fakultet
Sveučilišta u Zagrebu
prof. dr. sc. Branko Nikolić, Edukacijsko-rehabilitacijski fakultet
Sveučilišta u Zagrebu
doc. dr. sc. Damir Vukičević, Fakultet Prirodoslovno-
matematičkih znanosti i kineziologije Sveučilišta u Splitu
Redaktura i lektura:
Željka Jaklinović-Fressl, prof., dipl. bibl.
Računalna priprava:
doc. dr. sc. Dražan Dizdar
Oblikovanje naslovnice:
Srećko Sertić
Tisak:
GRAFIČKI ZAVOD HRVATSKE d.o.o.
Naklada:
1000 primjeraka
Zagreb, studeni 2006.
Odobreno kao sveučilišni udžbenik odlukom Senata Sveučilišta u Zagrebu, na prijedlog
Povjerenstva za znanstveno - nastavnu literaturu Sveučilišta u Zagrebu, odlukom br. 02-
3248/4-2005, od 14 studenog 2006.
Sveučilišni udžbenik je objavljen uz novčanu potporu Ministarstva znanosti, obrazovanja i
športa Republike Hrvatske.
Copyright © 2006.
Kineziološki fakultet Sveučilišta u Zagrebu. Sva prava su zaštićena. Niti jedan dio ove knjige ne
može se ponovno tiskati, kopirati ili koristiti u bilo kojem obliku, elektroničkom, mehaničkom ili na bilo koji drugi način
poznat sada ili izumljen u budućnosti, uključujući fotokopiranje i snimanje ili bilo kakvu pohranu informacija, bez
pismene suglasnosti izdavača.
CIP – Katalogizacija u publikaciji
Nacionalna i sveučilišna knjižnica - Zagreb
CIP zapis dostupan u računalnom katalogu Nacionalne I sveučilišne knjižnice u Zagrebu pod brojem
621759
ISBN-10 953-6378-58-2
ISBN-13 978-953-6378-58-6
3
Predgovor
Osnovna je namjena ove knjige da posluži kao udžbenik za predmet
Kvantitativne metode studentima Kineziološkog fakulteta Sveučilišta u
Zagrebu, ali i studentima ostalih fakulteta koji u svom studijskom programu
imaju metode opisane u ovoj knjizi.
Poticaj u pisanju bila mi je činjenica da za predmet Kvantitativne metode
do sada na Kineziološkom fakultetu nije napisan sveobuhvatan udžbenik pa
je ona i odredila njegov opseg i sadržaj. U pisanju sam nastojao (vodeći
računa da je većina studenata Kineziološkog fakulteta nesklona matematici)
nastavno gradivo predstaviti na razumljiv i prihvatljiv način prilagođavajući
razinu izlaganja mogućnostima i potrebama potencijalnih korisnika.
Knjiga se sastoji od četiri poglavlja. U prvome su poglavlju obrađeni
osnovni elementi matrične algebre koji su potrebni za lakši opis, objašnjenje
i razumijevanje pojedinih dijelova gradiva, osobito multivarijatnih metoda.
U drugom poglavlju opisani su osnovni statistički pojmovi, metode i
postupci za uređivanje i grafičko prikazivanje podataka, potom deskriptivni
parametri, teoretske distribucije, KS-test za testiranje normaliteta
distribucije, standardizacija podataka, procjena aritmetičke sredine
populacije, t-test, univarijatna analiza varijance i korelacijska analiza.
Osnove multivarijatnih metoda (regresijska analiza, komponentni model
faktorske analize, kanonička analiza i diskriminacijska analiza) opisane su u
trećem pogalavlju.
Četvrto poglavlje posvećeno je osnovama kineziometrije u okviru
kojega su opisani osnovni kineziometrijski pojmovi, konstrukcija mjernih
instrumenata
i
metrijske
karakteristike
(pouzdanost,
objektivnost,
homogenost, osjetljivosti i valjanost).
Koristim priliku osobito se zahvaliti svojoj profesorici prof. dr. sc. Nataši
Viskić-Štalec i najbližim suradnicima mr. sc. Darku Katoviću, doc. dr. sc.
Goranu Markoviću, Željku Pedišiću, prof., i Toši Maršiću, prof., koji su mi
iznimno pomogli savjetima, sugestijama i potporom. Zahvaljujem i
recezentima na korisnim primjedbama i sugestijama koje su pomogle u
otklanjanju propusta koje nisam uočio. Lekturom i korekturom znatan
doprinos kvaliteti teksta dala je Željka Jaklinović-Fressl, prof., na čemu joj
iskazujem zahvalnost. Duboku zahvalnost dugujem svojoj obitelji na
razumijevanju i potpori.
Iskreno se nadam da će knjiga pomoći studentima diplomskog i
poslijediplomskog sveučilišnog studija kineziologije u svladavanju osnova
kvantitativnih metoda za analizu podataka te im tako poslužiti kao
“odskočna daska” za postizanje više razine metodološke naobrazbe, a time i
kvalitete znanstveno-istraživačkoga rada na području kineziologije.
Zagreb, ljeto 2006.
Autor

5
Sadržaj
Predgovor
Uvod
................................................................................................................ ...........................9
1.
Elementi matrične algebre
.................................................................................................11
1.1.
Pojam i vrste matrica
................................................................................................12
1.1.1. Pojam vektora i matrica........................................................................12
1.1.2. Vrste matrica..........................................................................................14
1.2.
Računske operacije s matricama
..............................................................................16
1.2.1. Zbrajanje i oduzimanje matrica.............................................................16
1.2.2. Množenje matrica...................................................................................17
1.2.3. Množenje matrice skalarom...................................................................19
1.2.4. Hadamarovo množenje matrica.............................................................19
1.2.5. Trag matrice...........................................................................................20
1.2.6. Norma vektora.................................................................................. .....20
1.2.7. Udaljenost između dva vektora.............................................................22
1.2.8. Kut između dva vektra...........................................................................22
1.2.9. Linearna kombinacija vektora...............................................................23
1.2.10. Determinanta matrice..........................................................................24
1.2.11. Inverz matrice......................................................................................27
1.2.12. Pseudoinverz matrice...........................................................................31
1.2.13. Ortonormirane i ortogonalne matrice..................................................31
1.2.14. Rang i linearna zavisnost matrice........................................................32
1.2.15. Rješavanje sustava linearnih jednadžbi u matričnom obliku...............33
1.2.16. Svojstvene vrijednosti i svojstveni vektori..........................................35
1.2.17. Neka obilježja svojstvenih vrijednosti i svojstvenih vektora..............36
2.
Osnovne statističke metode
................................................................................................39
2.1.
Pojam i podjela statističkih metoda
.........................................................................40
2.1.1. Statistika................................................................................................40
2.1.2. Podjela statističkih metoda....................................................................41
2.2.
Osnovni statistički pojmovi
.......................................................................................44
2.2.1. Podatak ..................................................................................................44
2.2.2. Entitet ....................................................................................................45
2.2.3. Populacija i uzorak entiteta....................................................................45
2.2.4. Vrste uzoraka entiteta............................................................................46
2.2.5. Varijabla................................................................................................47
2.2.6. Vrste varijabli........................................................................................48
2.2.7. Populacija i uzorak varijabli..................................................................49
2.2.8. Matrica podataka...................................................................................49
2. 3.
Osnovni postupci za uređivanje i prikazivanje podataka
....................................50
2.3.1. Grupiranje podataka..............................................................................52
2.3.2. Grupiranje i grafičko prikazivanje kvalitativnih podataka....................54
2.3.3. Grupiranje i grafičko prikazivanje kvantitativnih podataka..................56
2.4.
Deskriptivni pokazatelji
............................................................................................63
2.4.1. Mjere centralne tendencije ili središnje mjere.......................................63
2.4.1.1. Aritmetička sredina ili prosječna vrijednost...............................................64
2.4.1.2. Mod ili dominantna vrijednost....................................................................70
2.4.1.3. Medijan ili centralna vreijdnost..................................................................72
2.4.2. Mjere varijabilnosti ili disperzije...........................................................74
2.4.2.1. Totalni raspon ............................................................................................75
2.4.2.2. Interkvartil..................................................................................................76
2.4.2.3. Varijanca i standardna devijacija................................................................77
2.4.2.4. Koeficijent varijabilnosti............................................................................85
2.4.3. Mjere asimetrije distribucije (skewness)...............................................86
2.4.4. Mjere izduženosti distribucije (kurtosis)...............................................88
6
2.5.
Teoretske distribucije
................................................................................................90
2.5.1. Elementarni pojmovi teorije vjerojatnosti.............................................91
2.5.1.1. Pravilo množenja.........................................................................................91
2.5.1.2. Pravilo permutacija.....................................................................................92
2.5.1.3. Pravilo varijacija.........................................................................................95
2.5.1.4. Pravilo kombinacija.....................................................................................97
2.5.1.5. Vjerojatnost.................................................................................................98
2.5.2. Diskretne teoretske distribucije..............................................................99
2.5.2.1. Uniformna distribucija................................................................................99
2.5.2.2. Binomna distribucija.................................................................................100
2.5.2.3. Poissonova distribucija.............................................................................102
2.5.3. Kontinuirane teoretske distribucije......................................................104
2.5.3.1. Normalna distribucija................................................................................104
2.5.3.2. Studentova t-distribucija...........................................................................107
2.5.3.3. Snedecorova F-distribucija.......................................................................109
2.5.3.4.
2
-distribucija............................................................................................110
2.6.
K-S test normaliteta distribucije
............................................................................111
2.7.
Standardizacija podataka (
z - vrijednost
)..............................................................114
2.7.1. Standardizacija varijabli matričnom algebrom....................................120
2.8.
Procjena aritmetičke sredine populacije
...............................................................124
2.9.
t-test
............................................................................................ ..............................135
2.9.1. t-test za nezavisne uzorke....................................................................137
2.9.2. t-test za zavisne uzorke........................................................................145
2.10.
Univarijatna analiza varijance
.............................................................................150
2.11.
Korelacija
...............................................................................................................160
2.11.1. Korelacija kao kosinus kuta dvaju vektora........................................171
2.11.2. Računanje korelacija matričnom algebrom.......................................173
2.11.3. Testiranje značajnosti koeficijenta korelacije....................................177
3.
Multivarijatne metode
......................................................................................................181
3.1.
Regresijska analiza
..................................................................................................182
3.1.1.Jednostavna linearna regresijska analiza..............................................185
3.1.2.Višestruka (multipla) regresijska analiza.............................................199
3.1.3.Testiranje značajnosti regresijskog modela..........................................205
3.1.4.Provjera kvalitete regresijskog modela................................................208
3.1.5.Dekompozicija varijance jednog skupa varijabli drugim skupom.......210
3.2.
Faktorska analiza
....................................................................................................214
3.2.1. Komponentni model fakorske analize.................................................219
3.2.1.1. Kriteriji za odabir značajnog broja faktora...............................................224
3.2.1.2. Kumunaliteti i unikviteti...........................................................................227
3.2.1.3. Rotacije.....................................................................................................228
3.2.1.4. Procjena rezultata entiteta na faktorima....................................................237
3.3.
Kanonička analiza
...................................................................................................238
3.3.1. Testiranje značajnosti kanoničkog modela.........................................244
3.4.
Diskriminacijska analiza
........................................................................................245
3.4.1. Multivarijatna analiza varijance..........................................................246
3.4.2. Diskriminacijska analiza.....................................................................251
3.4.3. Testiranje značajnosti diskriminacijskog modela...............................256
4.
Osnove kineziometrije
.....................................................................................................259
4.1.
Osnovni kineziometrijski pojmovi
........................................................................260
4.1.1. Mjerenje.............................................................................................. 261
4.1.2. Elementi mjerenja...............................................................................262
4.1.2.1. Objekt mjerenja........................................................................................262
4.1.2.2. Predmet mjerenja......................................................................................262
4.1.2.3. Mjerilac.....................................................................................................263
4.1.2.4. Mjerne skale..............................................................................................263
4.2.
Konstrukcija mjernih instrumenata
......................................................................267
4.2.1. Definiranje predmeta mjerenja............................................................267
4.2.2. Odabir odgovarajućeg tipa mjernog instrumenta................................269

9
Uvod
Utvrđivanje zakonitosti po kojima se odvijaju prirodne i društvene
pojave osnovni je cilj znanstvenih istraživanja. Za ostvarenje tog cilja
znanstvenici se koriste odgovarajućim postupcima (znanstvenim
metodama) koji omogućavaju prikupljanje podataka o istraživanom
problemu, njihovu obradu, testiranje odgovarajućih hipoteza te
formuliranje zakonitosti. Skup postupaka pomoću kojih se provode
znanstvena istraživanja, odnosno rješavaju znanstveni problemi, čini
metodologiju
(grč.
methodos
– put, traženje)
znanstvenog istraživanja.
Pritom valja odmah napomenuti da se pod metodologijom ne
podrazumjeva samo skup svih metoda koje se koriste u znanstvenim
istraživanjima, već i njihova logička osnova. Stoga, Milas (2005:14)
definira metodologiju kao „sustav pravila na temelju kojih se provode
istraživački postupci, izgrađuju teorije i obavlja njihova provjera“, a
cilj joj je „opis i analiza temeljnih metoda što se koriste u različitim
znanstvenim disciplinama, upoznavanje s njihovim prednostima i
ograničenjima, pretpostavkama na kojima počivaju i mogućim
ishodima njihove upotrebe“.
Kineziološka metodologija
predstavlja međuzavisni skup disciplina
koje proučavaju principe, sustave i postupke mjerenja, prikupljanja i
obrade podataka i upotrebe elektroničkih računala u rješavanju
tipičnih kinezioloških problema. To su:
kineziometrija
- proučava probleme mjerenja, odnosno, konstrukcije
i evaluacije mjernih instrumenata za procjenu kinezioloških
fenomena
kineziološka statistika
- proučava metode za transformaciju
prikupljenih podataka u oblik koji omogućava jasnije prikazivanje i
interpretaciju te testiranje postavljenih hipoteza
kineziološka informatika
-
proučava mogućnosti primjene
elektroničkih računala za analizu podataka u kineziološkim
istraživanjima te u pojedinim područjima primijenjene kineziologije
(Mraković, 1992).
Navedene se discipline na sveučilišnom diplomskom studiju
Kineziološkog fakulteta Sveučilišta u Zagrebu poučavaju u okviru
predmeta
Kvantitativne metode
. Osnovni je cilj predmeta upoznavanje
studenata s teoretskim osnovama metoda za analizu podataka
(osnovne statističke metode i multivarijatne metode) i teorijom
mjerenja (kineziometrija) te primjenom informatičke tehnologije

Elementi matrične algebre – Pojam i vrste matrica
11
1
Elementi
matrične
algebre
Matrična algebra najpogodnija je za objašnjavanje temeljnih
postupaka multivarijatne analize podataka jer se opsežni računski
postupci jednostavnije i kraće opisuju matričnom algebrom nego
elementarnom (skalarnom) algebrom. Stoga je potrebno usvojiti one
elemente matrične algebre koji su neophodni za razumijevanje
pojedinih dijelova gradiva, osobito onih u kojima se putem složenih
sustava linearnih jednadžbi u multivarijatnim metodama polazni
podaci kondenziraju i transformiraju u oblik koji omogućava jasniji
uvid i interpretaciju istraživanog problema. Pritom valja naglasiti da
su u ovom poglavlju krajnje pojednostavljeno predstavljeni dijelovi
matrične algebre (koji su nepohodni za usvajanje jednog dijela metoda
opisanih u ovoj knjizi) te da je za svladavanje ovog, vrlo zahtjevnog
dijela matematike, potrebno koristiti dodatnu literaturu.
Elementi matrične algebre – Pojam i vrste matrica
12
1.1
Pojam i vrste
matrica
1.1.1. Pojam vektora i matrica
Dio matematike koji se bavi računskim operacijama s matricama
naziva se
matrična algebra
.
Matrica
je skup brojeva smještenih u
n
redaka i
m
stupaca. Matrice se označavaju velikim masno otisnutim
(
bold
) slovima
A, B, C
,
…,
dok se elementi matrice (brojevi koji se
nalaze u matrici) označavaju malim slovima s odgovarajućim
indeksima
a
11
,
a
12
,…
nm
n2
n1
2m
22
21
1m
12
11
a
.
.
a
a
.
.
.
.
.
.
.
.
.
.
a
.
.
a
a
a
.
.
a
a
A
Primjer:
Matrica
A
reda
3
x
4
ima
3
retka i
4
stupca.
Element
a
1m
nalazi se
u
1.
-retku i
m
-stupcu
Oznaka matrice

Elementi matrične algebre – Pojam i vrste matrica
14
1.1.2. Vrste matrica
Kvadratna matrica
Matrica s jednakim brojem redaka i stupaca naziva se
kvadratna
matrica
.
Primjer:
3
4
5
2
4
1
5
3
2
A
Transponirana matrica
Matricu koja je dobivena iz neke matrice
A
zamjenom stupaca recima,
ili redaka stupcima naziva se
transponirana matrica
i označava se kao
A
T
.
Postupak se zove transponiranje matrice.
Primjer:
Matrica
A
je reda
3
x
4
0
1
7
4
6
3
2
3
4
3
1
2
A
a transponirana matrica
A
T
je reda
4
x
3
0
6
4
1
3
3
7
2
1
4
3
2
T
A
Simetrična matrica
Matrica
A
je simetrična ako je jednaka transponiranoj matrici
A
T
.
Dakle, ako je
A
=
A
T
,
matrice su simetrične. Odnosno, ako se elementi matrice
A
označe s
a
ij
, onda za sve elemente simetrične matrice vrijedi da je
Elementi matrične algebre – Pojam i vrste matrica
15
a
ij
= a
ji
,
gdje je
i,j =1,2,…,n.
Primjer:
3
2
5
2
4
1
5
1
2
A
3
2
5
2
4
1
5
1
2
T
A
Dijagonalna matrica
Kvadratna matrica, kojoj su u dijagonali
2
elementi različiti od nule,
dok su svi ostali elementi jednaki nuli, naziva se
dijagonalna matrica
.
Primjer:
7
0
0
0
4
0
0
0
2
D
Skalarna matrica
Skalarna matrica
je posebna vrsta dijagonalne matrice kod koje su
dijagonalni elementi jednaki.
Primjer:
2
0
0
0
2
0
0
0
2
S
Matrica identiteta
Posebna vrsta skalarne matrice je
matrica identiteta
. Matrica identiteta
je skalarna matrica u kojoj su dijagonalni elementi jednaki
1
.
Primjer:
1
0
0
0
1
0
0
0
1
I
2
pritom se uvjek misli na tzv. glavnu dijagonalu (
a
11
, a
22
,..., a
nn
).

Elementi matrične algebre – Računske operacije s matricama
17
1.2.2. Množenje matrica
Matrice se množe tako da se zbrajaju produkti elemenata iz retka prve
matrice i elemenata iz stupca druge matrice uz uvjet da je broj stupaca
prve matrice jednak broju redaka druge matrice. Općenito vrijedi ako
je
42
41
32
31
22
21
12
11
a
a
a
a
a
a
a
a
A
i
23
22
21
13
12
11
b
b
b
b
b
b
B
,
onda je
43
23
42
13
41
42
22
42
12
41
41
21
42
11
41
33
23
32
13
31
32
22
32
12
31
31
21
32
11
31
23
23
22
13
21
22
22
22
12
21
21
21
22
11
21
13
23
12
13
11
12
22
12
12
11
11
21
12
11
11
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
c
b
a
b
a
C
B
A
Dakle, množenjem matrice
A
reda
n
x
m
matricom
B
reda
m
x
k
dobije se
matrica
C
reda
n
x
k
.
Primjer:
Ako je
4
1
4
1
3
1
A
i
0
1
7
4
6
3
2
3
4
3
1
2
B
,
onda je
0
4
6
1
4
4
1
4
3
1
3
4
7
4
2
1
1
4
4
4
3
1
2
4
0
1
6
3
4
1
1
1
3
3
3
1
7
1
2
3
1
1
4
1
3
3
2
1
C
B
A
odnosno
22
19
34
27
22
13
14
15
C
B
A
Množenje bilo koje matrice matricom identiteta ostavlja matricu
nepromijenjenom.
A
A
I
Elementi matrične algebre – Računske operacije s matricama
18
Množenjem nekog vektora
a
nekim transponiranim vektorom
b
T
(pritom vektori moraju imati jednak broj elemenata) uvijek se dobije
kvadratna matrica jednaka redu tih vektora.
Primjer:
Ako je
0
2
3
a
4
3
1
T
b
onda je
0
0
0
8
6
2
12
9
3
T
c
b
a
Množenjem nekog transponiranog vektora
a
T
(vektor retka) nekim
vektorom
b
(vektor stupca) uvijek se dobije skalar. Dakle,
n
1
i
i
i
b
a
b
a
T
Primjer:
Ako je
4
3
1
T
a
, a
0
2
3
b
, onda je
-3
0)
(4
2)
3
(
3)
(1
b
a
T
.
Osim toga, za množenje matrica vrijede sljedeća pravila:
AB
BA
ako je
AB
= 0
, ne mora biti ni
A
= 0
ni
B
= 0
.
(
AB
)
C
=
A
(
BC
)
(
A+B
)
C
=
AC +BC
(
AB
)
T
=
B
T
A
T

Elementi matrične algebre – Računske operacije s matricama
20
Primjer:
3
2
5
2
4
1
5
1
2
A
,
0
1
3
2
5
1
4
1
1
B
,
0
2
15
4
20
1
20
1
2
C
B
A
1.2.5. Trag matrice
Trag matrice
A
predstavlja zbroj elemenata u glavnoj dijagonali te
matrice
33
32
31
23
22
21
13
12
11
a
a
a
a
a
a
a
a
a
A
trag(A) = a
11
+ a
22
+ a
33
Primjer:
3
2
5
2
4
1
5
1
2
A
trag(A)=2+4+3=9
1.2.6. Norma vektora
Duljina ili norma vektora
dobije se operacijom
2
/
1
1
2
2
2
3
2
2
2
1
.......
n
i
i
n
a
a
a
a
a
a
,
odnosno
2
/
1
)
(
a
a
T
a
Elementi matrične algebre – Računske operacije s matricama
21
Vektor čija je duljina jednaka
1
zove se
normirani vektor
. Normirani
vektor dobije se operacijom
normiranja
, odnosno tako da se vektor
podijeli sa svojom duljinom
a
a
a
ˆ
ili
2
/
1
)
(
ˆ
a
a
a
a
T
Svaki se nenulti vektor može transformirati u normirani vektor.
Primjer:
Ako je
5
1
3
4
2
a
onda je norma vektora
a
jednaka
7,42
55
25
1
9
16
4
5
1
3
4
2
a
2
2
2
2
2
a normirani vektor je
0,67
0,13
0,4
0,54
0,27
7,42
1
5
1
3
4
2
a
ˆ
jer je
1
1
0,67
0,13
0,4
0,54
0,27
a
2
2
2
2
2
ˆ

Elementi matrične algebre – Računske operacije s matricama
23
Iz toga slijedi da je skalarni produkt dvaju vektora jednak produktu
njihovih normi i kosinusa kuta njihova kuta
α
cos
b
a
T
b
a
Ako su vektori normirani na
1
, onda je kosinus kuta jednak skalarnom
produktu tih dvaju vektora
α
cos
T
b
a
ˆ
ˆ
Ako je skalarni produkt dvaju vektora jednak nuli,
0
T
b
a
,
onda je
cos
= 0,
što znači da su vektori
a
i
b
ortogonalni (kut između njih je
90
).
Primjer:
Ako je
3
4
2
a
, a
3
5
4
b
onda je
5,39
29
9
16
4
3
4
2
a
2
2
2
7,07
50
9
25
16
3
5
4
b
2
2
2
37
3)
(3
5)
(4
4)
(2
3
5
4
3
4
2
b
a
T
pa je
0,97
38,11
37
7,07
5,39
37
α
cos
1.2.9.
Linearna kombinacija vektora
Linearna kombinacija vektora je vektor koji je nastao zbrajanjem
produkata drugih vektora s pripadajućim skalarima. Ako su
a
j
(
j=1,…,m
) vektori istog reda, a
j
pripadajući skalari, onda je vektor
b
linearna kombinacija vektora
a
j
m
2
1
j
a
a
a
a
b
m
2
1
m
1
j
j
...
Elementi matrične algebre – Računske operacije s matricama
24
Za novi vektor
b
kažemo da je dobiven
jednostavnom linearnom
kombinacijom
ako je nastao zbrajanjem drugih vektora istog reda
a
j
(
j=1,…,m
), a
diferencijalno ponderiranom linearnom kombinacijom
ako je dobiven zbrajanjem produkata drugih vektora istog reda
a
j
(
j=1,…,m
) s odgovarajućim skalarima
j
(ponderima).
Primjer:
Ako su
a
,
b
i
c
vektori istog reda, a
,
,
skalari, novi
vektor
d
nastao je linearnom kombinacijom vektora
a
,
b
i
c
i skalara
,
,
ako je
n
n
n
n
n
n
c
b
a
c
b
a
c
c
b
b
a
a
.
.
.
.
.
.
.
.
.
.
.
.
1
1
1
1
1
1
d
1.2.10. Determinanta matrice
Detereminanta neke kvadratne matrice
A
predstavlja karakterističan
broj te matrice, označava se s
det(A)
, a ima veći broj svojstava od
kojih su neka:
determinantu je moguće izračunati samo iz kvadratnih matrica
determinanta je jednaka nuli ako je bilo koji redak ili stupac jednak
nuli
determinanta je jednaka nuli ako su njezini stupci ili reci linearno
zavisni
determinanta dijagonalne matrice jednaka je produktu dijagonalnih
elemenata te matrice
determinanta produkta matrica jednaka je produktu determinanata tih
matrica
determinanta kvadratne matrice kojoj je neki stupac ili redak
pomnožen s nekim skalarom jednaka je produktu tog skalara i
determinante originalne matrice itd.
Postoji više načina računanja determinanata. Jedan od mogućih načina
određivanja determinante temelji se na
kofaktorima,
odnosno na
zbroju produkata jednog retka ili stupca s pripadajućim kofaktorima.
Kofaktori predstavljaju
minore
nekog elementa matrice
a
ij
kojemu je

Elementi matrične algebre – Računske operacije s matricama
26
Zbrajanjem umnožaka elemenata jednog stupca ili retka s
pripadajućim kofaktorima izračuna se determinanta matrice
A
13
k
a
k
a
k
a
det(A)
13
12
12
11
11
odnosno
32
31
22
21
13
33
31
23
21
12
33
32
23
22
11
a
a
a
a
det
a
a
a
a
a
det
a
a
a
a
a
det
a
det(A)
)
a
a
a
(a
a
)
a
a
a
(a
a
)
a
a
a
(a
a
det(A)
31
2
32
21
13
31
23
33
21
12
32
23
33
22
11
Kod izračunavanja determinanata matrica višeg reda treba najprije
odrediti prve minore i kofaktore, zatim druge itd. Dakle, determinanta
bilo koje matrice može se svesti na determinantu drugog reda.
Primjer 1:
Determinanta matrice
5
1
4
3
A
19
1)
(4
5))
(
(3
det(A)
Primjer 2:
Determinanta matrice
1
1
2
3
2
3
1
2
2
4
2
2
5
4
3
1
A
14
13
12
11
m
5
m
4
m
3
m
1
det(A)
4
10
12
2
5)
(
2
3)
(
4
1
2
2)
3
1
(1
2
2)
2
1
(1
4
1)
2
1
(3
2
1
2
3
1
det
2
1
2
2
1
det
4
1
1
2
3
det
2
1
1
2
2
3
1
2
4
2
det
m
11
Elementi matrične algebre – Računske operacije s matricama
27
4
14
16
2
7)
(
2
4)
(
4
1
2
3)
3
1
(2
2
3)
2
1
(2
4
1)
2
1
(3
2
1
3
3
2
det
2
1
3
2
2
det
4
1
1
2
3
det
2
1
1
3
2
3
2
2
4
2
det
m
12
4
8
6
1
2
4)
(
2
3)
2
3)
1
2
(2
2
3)
2
1
(2
2
2)
2
1
(1
2
2
3
1
2
det
2
1
3
2
2
det
2
1
2
2
1
det
2
1
2
3
2
1
2
2
2
2
det
m
13
2
(
8
4
14
10
1)
(
4
7)
(
2
5)
(
2
3)
1
2
(2
4
3)
3
1
(2
2
3)
2
1
(1
2
1
3
3
2
det
4
1
3
3
2
det
2
1
2
3
1
det
2
1
2
3
3
1
2
4
2
2
det
m
14
32
8
5
4
4
4
3
4
1
m
5
m
4
m
3
m
1
14
13
12
11
det(A)
1.2.11. Inverz matrice
Inverz neke matrice moguć je samo ako je matrica kvadratna i punog
ranga (ima determinantu različitu od nule). Invertiranje matrice u
matričnoj algebri odgovara recipročnoj vrijednosti broja (skalara) u
skalarnoj algebri. Matrica
A
-1
je inverz matrice
A
ako je
I
A
A
A
A
1
1
gdje je
I
matrica identiteta, odnosno matrica koje su dijagonalni
elementi
1
, a izvandijagonalni jednaki
0
. Poznaju li se pojmovi
determinante, minora i kofaktora, može se pokazati postupak
invertiranja matrice. Inverz matrice

Elementi matrične algebre – Računske operacije s matricama
29
2
4
2
2
2
1
2
1
2
2
2
det
m
13
4
5
9
1
5
3
3
3
1
5
3
det
m
21
7
10
3
2
5
3
1
3
2
5
1
det
m
22
5
6
1
2
3
1
1
1
2
3
1
det
m
23
2
10
12
2
5
4
3
4
2
5
3
det
m
31
6
10
4
2
5
4
1
4
2
5
1
det
m
32
4
6
2
2
3
2
1
2
2
3
1
det
m
33
4
6
2
5
7
4
2
2
2
m
m
m
m
m
m
m
m
m
33
32
31
23
22
21
13
12
11
M
minorima se odrede predznaci tako da se elementi matrice minora
m
ij
pomnože s
(-1)
i+j
i dobije matrica kofaktora
4
6
2
5
7
4
2
2
2
K
transponira se matrica kofaktora
Elementi matrične algebre – Računske operacije s matricama
30
4
5
2
-
6
7
2
2
4
-
2
T
K
izračuna se determinanta
2
10
6
2
2)
(
5
2
3
2
1
k
a
k
a
k
a
det(A)
13
13
12
12
11
11
izračuna se inverz
2
2,5
1
3
3,5
1
1
2
1
4
5
2
6
7
2
2
4
2
2
1
detA
1
T
1
-
K
A
Može se provjeriti da je
I
A
A
1
1
0
0
0
1
0
0
0
1
2
2,5
1
3
3,5
1
1
2
1
3
1
2
4
2
2
5
3
1
1
A
A
Matrica kojoj je determinanta
0
nema inverz i naziva se
singularna
matrica
.
Ako matrica ima determinantu različitu od
0
, onda matrica
ima inverz i zove se
nesingularna matrica,
odnosno
regularna
matrica
. Je li neka kvadratna matrica regularna ili singularna, zavisi
od toga jesu li vektori te matrice linearno zavisni ili nisu. Ako se niti
jedan vektor te matrice ne može izračunati kao linearna kombinacija
preostalih vektora, onda je ta matrica regularna. Ako su matrice
A
i
B
regularne, tada i njihov umnožak daje regularnu matricu, odnosno,
vrijedi
(
AB
)
-1
=
B
-1
A
-1
Pored toga, ako je
A
neka regularna matrica, vrijedi
(
A
-1
)
-1
=
A
(
A
T
)
-1
=
(
A
-1
)
T

Elementi matrične algebre – Računske operacije s matricama
32
1.2.14.
Rang i linearna zavisnost matrice
Za neki redak ili stupac kažemo da je linearno zavisan ako se može
izraziti kao linearna kombinacija drugih redaka ili stupaca. Rang
matrice jednak je minimalnom broju redaka ili stupaca u matrici čijom
se linearnom kombinacijom mogu izraziti svi ostali reci ili stupci te
matrice. To vrijedi za ne-nul matricu jer je rang nul-matrice jednak
nuli.
Ako se svaki redak matrice može izraziti linearnom kombinacijom
samo jednog retka, onda je rang te matrice jedan; ako se svaki redak
može izraziti linearnom kombinacijom dvaju redaka, onda je rang
matrice dva itd.
Primjer:
Rang matrice
5
4
13
3
0
3
1
3
7
A
je
2
jer se, primjerice, elementi prvog stupca dobiju kao linearna
kombinacija elemenata drugog i trećeg stupca, odnosno
13
5
2
4
a
2
a
a
3
3
2
0
a
2
a
a
7
1
2
3
a
2
a
a
33
32
31
23
22
21
13
12
11
Elementi matrične algebre – Računske operacije s matricama
33
1.2.15. Rješavanje sustava linearnih jednadžbi u
matričnom obliku
Sustav od
n
jednadžbi sa
n
nepoznanica
n
n
nn
n
n
n
n
n
n
n
n
y
x
a
x
a
x
a
y
x
a
x
a
x
a
y
x
a
x
a
x
a
y
x
a
x
a
x
a
..........
.
.
..........
..........
..........
2
2
1
1
3
3
2
32
1
31
2
2
2
22
1
21
1
1
2
12
1
11
moguće je prikazati u matričnom obliku
A x
=
y
odnosno
n
n
nn
n
n
n
n
y
y
y
x
x
x
a
a
a
a
a
a
a
a
a
.
.
.
.
.
.
.
.
.
2
1
2
1
2
1
2
22
21
1
12
11
gdje je
A
kvadratna matrica reda
n
x
n
s poznatim vrijednostima
x
vektor stupca reda
n
x
1
nepoznatih vrijednosti
y
vektor stupca reda
n
x
1
poznatih vrijednosti.
Sustav linearnih jednadžbi izražen u obliku
A x
=
y
može se rješavati primjenom inverza matrice
A
. Ako se obje strane te
jednadžbe pomnože sa
A
-1
, dobije se
A
-1
A x
=
A
-1
y
Iz toga slijedi da je
x
=
A
-1
y

Elementi matrične algebre – Računske operacije s matricama
35
1.2.16. Svojstvene vrijednosti i svojstveni vektori
Prema Eckart-Yungovoj hipotezi (Eckart i Young, 1936), koju je
dokazao Johnson (1963), svaku realnu matricu
A
moguće je pomnožiti
dvjema ortogonalnim matricama
Y
i
X
tako da se kao rezultat dobije
dijagonalna matrica
koja neće imati negativnih elemenata. Dakle,
vrijedi
Y
T
A X
=
odnosno, da je svaku matricu moguće dekomponirati
A
=
Y
X
T
gdje je
Y
matrica lijevih svojstvenih (karakterističnih) vektora matrice
A
, za
koju vrijedi da je
Y
T
Y
=
Y Y
T
=
I
, dakle vektori matrice
Y
su
ortonormirani
X
matrica desnih svojstvenih (karakterističnih) vektora matrice
A
, za
koju vrijedi da je
X
T
X
=
X X
T
=
I
, dakle vektori matrice
X
su
ortonormirani
dijagonalna matrica svojstvenih (karakterističnih) vrijednosti
matrice
A
.
Osim toga, isti su autori dokazali da je matrica
X
matrica svojstvenih
vektora matrice
A
T
A
,
A
T
A
=
X D X
T
a matrica
Y
matrica svojstvenih vektora matrice
AA
T
,
AA
T
=
Y D Y
T
dok matrica
D
sadrži nenegativne svojstvene vrijednosti matrica
A
T
A
i
A A
T
. Može se dokazati da je
Y
T
A X
=
D
1/2
=
iz čega slijedi da je
Y
=
A X D
-1/2
=
A X
-1
odnosno
X
=
A
T
Y D
-1/2
=
A
T
Y
-1
Ako je matrica
A
kvadratna i ujedno simetrična, onda vrijedi
Elementi matrične algebre – Računske operacije s matricama
36
X
T
A X
=
odnosno
A
=
X
X
T
gdje je
X
matrica svojstvenih vektora za koju vrijedi da je
X
T
X
=
X X
T
=
I
,
dakle vektori matrice
X
su ortonormalni
dijagonalna matrica svojstvenih vrijednosti.
Matrice
X
i
predstavljaju bazičnu strukturu matrice
A
. Matrice
svojstvenih vrijednosti i svojstvenih vektora izračunavaju se
rješavanjem tzv.
karakteristične jednadžbe
(
A
-
I
)
X
=
0
Rješavanje karakteristične jednadžbe vrlo je složen i dugotrajan
matematički postupak. Stoga je pojavom elektroničkih računala za
rješavanje karakteristične jednadžbe, odnosno za utvrđivanje
svojstvenih vrijednosti i svojstvenih vektora, konstruiran veći broj
algoritama pogodnih za izradu računalnih programa. U knjizi Ante
Fulgosija:
Faktorska analiza
, opisano je nekoliko takvih postupaka
(primjerice, Hotellingov iterativni postupak ekstrakcije faktora,
Jacobijeva metoda, Householderov postupak dijagonalizacije…).
1.2.17.
Neka obilježja svojstvenih vrijednosti i
svojstvenih vektora
Ako je matrica
A
kvadratna i ujedno simetrična matrica, onda vrijedi
X
T
A X
=
odnosno
A
=
X
X
T
gdje je
X
matrica svojstvenih vektora za koju vrijedi da je
X
T
X
=
X
X
T
=
I
, a
dijagonalna matrica svojstvenih vrijednosti. Tada vrijedi
trag
(
A
)
=
trag
(
)
dakle,
trag
neke simetrične matrice jednak je sumi njenih svojstvenih
vrijednosti. Osim toga, za svaku kvadratnu matricu
A
reda
n
x
n
vrijedi
da je njena determinanta jednaka produktu njenih svojstvenih
vrijednosti

Elementi matrične algebre – Računske operacije s matricama
38
Osnovne statističke metode – Pojam i podjela statističkih metoda
39
2
Osnovne
statističke
metode

Osnovne statističke metode – Pojam i podjela statističkih metoda
41
Statistika pruža nenadmašna sredstva za pretvaranje kaosa u
savršeni red. (Guilford, 1968: 9).
Statistika je i način proučavanja pojava, pa se govori i o
statističkom
načinu mišljenja
. Guilford (1968) navodi kako je ovladavanje
statističkim metodama i statističkim načinom mišljenja važno u
znanstvenim istraživanjima jer:
omogućava precizan opis (deskripciju) istraživanih pojava
“prisiljava” znanstvenika da bude egzaktan u svojim postupcima i
razmišljanjima
omogućava sažeto izražavanje rezultata istraživanja i njihov
pregledan prikaz
omogućava izvođenje općih zaključaka, odnosno generaliziranje
zaključaka dobivenih na uzorku na populaciju koje je uzorak
reprezentant
omogućava predviđanje istraživane pojave
omogućava utvrđivanje uzročno-posljedičnih odnosa, odnosno
činilaca odgovornih za nastajanje neke pojave.
Stoga možemo zaključiti da je poznavanje statističkih metoda nužan
preduvjet za uspješnu znanstvenu djelatnost jer pomoću njih
transformiramo podatke prikupljene nekim znanstvenim istraživanjem
u oblik koji nam omogućava jasniji uvid i interpretaciju istraživane
pojave te provjeru postavljenih hipoteza.
2.1.2. Podjela statističkih metoda
Znanstvena istraživanja u mnogim znanostima (primjerice,
ekomomije, kineziologije, medicine, psihologije…) temelje se na
velikom broju općih i specifičnih statističkih metoda. Stoga je
klasifikacija statističkih metoda vrlo nezahvalan zadatak. Opće je
prihvaćena podjela statističkih metoda na:
metode deskriptivne statistike -
Statistički postupci grupiranja i
grafičkog prikazivanja podataka te izračunavanja različitih
statističkih pokazatelja kojima se opisuje promatrana pojava (mjere
centralne tendencije ili središnje mjere, mjere varijabilnosti ili
disperzije, mjere asimetrije i zakrivljenosti distribucije…). Pri tome
je važno naglasiti da se zaključci dobiveni u okviru deskriptivne
Osnovne statističke metode – Pojam i podjela statističkih metoda
42
statisitike odnose isključivo na promatranu grupu ispitanika
(uzorak).
metode inferencijalne statistike -
Statistički postupci kojima se na
temelju rezultata dobivenih na uzorku s oslanjanjem na teoriju
vjerojatnosti proširuju zaključci na populaciju koje je uzorak
reprezentant. Dakle, polazeći od podataka prikupljenih na uzorku
(podskupu populacije), donose se vjerojatnosni zaključci o
populaciji.
U ovu skupinu statističkih metoda ubrajaju se
t
-test,
univarijatna analiza varijance, multivarijatna analiza varijance,
postupci za testiranje statističke značajnosti koeficijenta korelacije,
multiple korelacije, kanoničke korelacije, regresijskih koeficijenata
itd.
U ovom će se udžbeniku, uz ovu opću podjelu, statističke metode koje
se najčešće koriste u okviru kineziološke metodologije znanstveno-
istraživačkog rada klasificirati prema nekoliko kriterija:
1) S obzirom na vrstu varijabli, odnosno mjernu skalu (ljestvicu) koja
je primjenjuje u postupku mjerenja, statističke je metode moguće
podijeliti na:
neparametrijske metode
- koriste se za obradu podataka
prikupljenih na kvalitativnim mjernim ljestvicama (v. poglavlje
4.1.2.4, str. 261-264), koji imaju distribucije značajno različite od
normalne (Gaussove distribucije). Kod takvih podataka nije
moguće utvrđivati statističke parametre (aritmetičku sredinu i
standardnu devijaciju) te se stoga i zovu neparametrijske metode.
U tu kategoriju metoda ubrajaju se:
2
-test, Wilcoxonov test,
medijan test, rang korelacija itd.
parametrijske metode
- koriste se za obradu normalno
distribuiranih podataka, prikupljenih na kvantitativnim mjernim
ljestvicama (v. poglavlje 4.1.2.4, str. 261-264), kod kojih je
moguće utvrđivati statističke parametre. U ovu skupinu se
ubrajaju:
t
-test, univarijatna analiza varijance, mutlivarijatna
analiza varijance, regresijska analiza, faktorska analiza itd.
2) Statističke metode moguće je klasificirati i prema broju varijabli
koje se istovremeno analiziraju pa tako prepoznajemo:

Osnovne statističke metode – Osnovni statistički pojmovi
44
2.2
Osnovni
statistički pojmovi
2.2.1. Podatak
Usprkos teškoćama koje se javljaju pri pokušaju jednoznačnog
definiranja pojma statistike, moguće je uočiti da se u svim
definicijama navodi kako se primjenom statističkih metoda nastoji
srediti veća količina prikupljenih
podataka
. Pod pojmom
podatak
ili
informacija
podrazumijeva se određena kvantitativna ili kvalitativna
vrijednost kojom je opisano određeno obilježje nekog objekta, stvari,
osobe, pojave, procesa…,odnosno, entiteta. Pritom je važno naglasiti
da se statistika bavi obradom podataka koji međusobno variraju.
Naime, kada bi svi prikupljeni podaci bili jednaki, onda ne bi bili
predmetom statističke analize, jer bi jedan podatak opisivao i sve
druge podatke. Osim toga, predmet statističke analize nisu ni podaci
koji se izvode po nekoj zadanoj matematičkoj funkciji, primjerice,
logaritamski brojevi i slično, već su to podaci varijabilitet kojih mora
biti izraz prirode pojave koja se istražuje. Tako, primjerice, tjelesna
visina djece istog spola i dobi nije jednaka te se njen varijabilitet ne
može točno definirati matematičkom formulom, već se opisuje
određenim statističkim pokazateljima.
Osnovne statističke metode – Osnovni statistički pojmovi
45
2.2.2. Entitet
Statistika se bavi obradom podataka koji opisuju određena obilježja,
svojstva, karakteristike nekog skupa osoba, objekata, stvari, pojava,
procesa i sl. Svaka jedinka toga skupa naziva se
entitet
i nosi
informacije koje je moguće prikupiti nekim postupkom mjerenja. U
kineziološkim istraživanjima entiteti su najčešće ljudi, ali mogu biti i
sportske ekipe, tehnički elementi, zadaci u igri itd.
2.2.3. Populacija i uzorak entiteta
Skup svih entiteta čija su obilježja predmet statističke analize najčešće
se naziva
populacija entiteta
(
statistički skup, univerzum entiteta
).
Populacija entiteta može biti beskonačan
P = {e
i
; i = 1,2,...}
ili konačan
P = {e
i
; i = 1,2,..,N}
skup entiteta (
e
i
).
Prema Šošiću (2004), beskonačna populacija predstavlja hipotetični
skup s beskonačno mnogo elemenata (entiteta) koji su u svezi s nekim
statističkim (stohastičkim) procesom. Ako se proces ponavlja
beskonačno u istim uvjetima, njegovi su ishodi elementi beskonačne
populacije. Primjerice, ako na isti način i u istim uvjetima beskonačno
bacamo pravilan novčić, tada nije poznato unaprijed što će biti rezultat
bacanja (pismo ili glava), a postupak se teoretski može izvoditi
beskonačno. Dakle, radi se o statističkom procesu čiji su ishodi
elementi beskonačne populacije.
Za razliku od beskonačne populacije, koja ima beskonačan broj
entiteta, konačnu populaciju predstavlja pojmovno, prostorno i
vremenski definiran konačan skup entiteta. Primjerice, "studenti prve
godine Kineziološkog fakulteta Sveučilišta u Zagrebu školske godine
2002/2003". Entiteti koji pripadaju ovako definiranoj populaciji
jednaki su po općim obilježjima, a to su:
pojmovno
- studenti prve godine Kineziološkog fakulteta,
prostorno
- Sveučilišta u Zagrebu,
vremenski
- u školskoj godini 2000/2001.
Dakle,
pojmovno
određenje populacije definira što je entitet i koja su
njegova opća svojstva,
prostorno
određenje određuje geografsko

Osnovne statističke metode – Osnovni statistički pojmovi
47
intervalni uzorak
- formira se tako da se svi entiteti neke populacije
poredaju (npr. po abecednom redu) te da se, nakon slučajnog izbora
prvog entiteta, bira svaki treći, peti, odnosno
n
-ti entitet. Ovaj način
biranja entiteta ima karakteristike jednostavnog slučajnog uzorka
ako su entiteti nesistematski poredani.
stratificirani uzorak
- formira se tako da se populacija podijeli
prema nekim važnim obilježjima (npr. spol, dob i sl.) u
stratume
(slojeve, podpopulacije) iz kojih se slučajnim odabirom biraju
entiteti. Broj entiteta biranih iz svakog
stratuma
mora biti
proporcionalan veličini pojedinog stratuma u populaciji.
grupni uzorak
- formira se tako da se iz neke populacije slučajnim
izborom biraju cijele grupe (npr. ako se istražuje srednjoškolska
populacija u nekoj državi, slučajnim izborom bira se uzorak škole, a
svi učenici škola koje su odabrane čine uzorak entiteta).
2.2.5. Varijabla
Iako entiteti neke populacije imaju međusobno jednaka opća obilježja
(primjerice, studenti su Kineziološkog fakulteta Sveučilišta u Zagrebu
u šk. god. 2000/2001.), oni se razlikuju po drugim obilježjima
(osobinama,
sposobnostima,
znanjima
itd.),
primjerice,
po
morfološkim obilježjima (tjelesna visina, tjelesna težina, raspon ruku,
opseg podlaktice...), motoričkim sposobnostima (rezultatima
postignutim u raznim motoričkim zadacima temeljem kojih se
procjenjuju
npr.
eksplozivna
snaga,
brzina,
koordinacija...),
situacijskoj uspješnosti igrača ili ekipe (broj skokova u obrani, broj
asistencija...) itd. U znanstvenim istraživanjima pod pojmom
varijabla
podrazumijeva se određeno obilježje (svojstvo) koje oblikom ili
stupnjem varira među entitetima, odnosno po kojem entiteti mogu biti
isti ili različiti. To svojstvo mora biti operacionalno definirano,
odnosno svi postupci za njegovo opažanje ili mjerenje moraju biti
precizno opisani.
Napomena:
Spomenuti uzorci, naravno, ne predstavljaju sve vrste uzoraka. Opis i objašnjenje većeg broja
metoda uzorkovanja
(vrsta uzoraka) te njihove prednosti i nedostaci pripadaju područje
planiranja
znanstvenih istraživanja
, pa nadilaze opseg ove knjige. Stoga se zahtjevniji čitatelji upućuju na
knjigu:
G. Milas (2005). Istraživačke metode u psihologiji i drugim društvenim znanostima. (str. 399-446).
Jastrebarsko: Naklada Slap.
ili neku drugu knjigu koja detaljnije i sveobuhvatnije opisuje vrste uzoraka.
Osnovne statističke metode – Osnovni statistički pojmovi
48
2.2.6. Vrste varijabli
Različita obilježja, odnosno varijable (osobine, sposobnosti i sl.)
mogu se pojavljivati u različitim oblicima i stupnjevima. Primjerice:
obilježje
spol
javlja se u dva oblika:
muškarci
i
žene
. Takva se
obilježja nazivaju
alternativnima
. Školske ocjene se u Hrvatskoj
javljaju u
5
različitih oblika (nedovoljan, dovoljan, dobar, vrlo dobar i
odličan). Tjelesna visina vrlo je promjenjiva i može se izraziti
različitim vrijednostima koje ukazuju na stupanj razvijenosti mjerenog
obilježja itd. No usprkos takvoj raznolikosti, moguće je varijable
podijeliti na
kvalitativne
i
kvantitativne
.
Kvalitativne varijable još se nazivaju i
kategorijalnima
, a mogu biti
nominalne
i
ordinalne
(redosljedna). Na isti način razlikuju se i
mjerne ljestvice (v. poglavlje 4.1.2.4, str. 261-264).
Za razliku od kvalitativnih varijabli kojima se izražavaju nenumerička
svojstva entiteta,
kvantitativne varijable
numerički izražavaju stupanj
razvijenosti mjerenog svojstva, a dobivene su mjerenjem nekog
obilježja entiteta
intervalnom
i
omjernom
mjernom ljestvicom (v.
poglavlje 4.1.2.4, str. 261-264).
Osim toga, kvantitativne varijable mogu biti
diskretne
i
kontinuirane
.
Diskretne varijable izražavaju konačan broj vrijednosti mjerenog
svojstva i uvijek su određene cijelim brojem. Dobivaju se postupkom
prebrojavanja (npr. broj sklekova, broj skokova u obrani i napadu...),
dok kontinuirane varijable mogu poprimiti bilo koju numeričku
vrijednost, a dobivaju se mjerenjem (npr. mjerenje vremena, količine,
udaljenosti…).
Osim navedene podjele varijabli s obzirom na mjernu ljestvicu
(metrijska svojstva varijabli), varijable se mogu razlikovati i prema
ulozi u pojedinoj statističkoj metodi. Tako, primjerice, u regresijskoj
analizi razlikujemo
zavisnu (kriterijsku)
i
nezavisne (prediktorske)
varijable.
Zavisne varijable su varijable čije se varijacije objašnjavaju
(prognoziraju) temeljem nezavisnih varijabli, a nezavisne varijable su
varijable na temelju kojih se objašnjavaju varijacije zavisne varijable.
U faktorskoj analizi se na temelju većeg broja međusobno povezanih
manifestnih varijabli
utvrđuje manji broj
latentnih varijabli.
Manifestne varijable dobivaju se mjerenjem, dok latentne varijable

Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
50
2. 3
Osnovni postupci za
uređivanje i
prikazivanje
podataka
Faza prikupljanja podataka najosjetljiviji je dio nekog istraživanja jer
o kvaliteti prikupljenih podataka ovisi vrijednost statističkih
zaključaka o ispitivanoj pojavi. Stoga fazi prikupljanja podataka treba
prethoditi:
precizan opis predmeta istraživanja
određivanje ciljeva i postavljanje hipoteza
definiranje populacije entiteta te načina izbora i veličine uzorka
entiteta
određivanje skupa varijabli i izbor mjernih instrumenata
izrada plana mjerenja.
Samo mjerenje mora biti u skladu sa strogo definiranim pravilima,
odnosno, moraju ga provesti osposobljeni mjerioci mjernim
instrumentima provjerenih metrijskih karakteristika.
Nakon faze prikupljanja, podatke je potrebno pripremiti za
odgovarajuću statističku obradu. S obzirom da se u posljednje vrijeme
statistička obrada obavlja isključivo pomoću specijaliziranih
računalnih programa za statističko-grafičku obradu podataka (
SPSS,
Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
51
STATISTICA
itd.), prikupljene podatke potrebno je pohraniti u
datoteke (
fileove
). Gotovo svi programski proizvodi za statističko-
grafičku obradu podataka zahtijevaju unos podataka u obliku tablice
ili matrice. U prvom se koraku uz, pomoć odgovarajućih programskih
alata, formira tablica čiju veličinu određuje broj entiteta (broj entiteta
određuje broj redaka) i broj varijabli (broj varijabli određuje broj
stupaca). Zatim se, prema potrebi, imenuju varijable (stupci) i entiteti
(reci) te se unose prikupljeni podaci. Primjer tablice s podacima koja
je kreirana u progamskom sustavu
STATISTICA
prikazan je u tablici
2.3-1.
Tablica 2.3-1.
Tablica podataka 20 entiteta opisanih 3 varijablama kreirana je u
programskom sustavu STATISTICA
SPOL POZ OKI
AV
M
B
4
EM
M
B
3
KV
M
B
4
MD
M
B
3
MM
M
K
3
NM
M
K
2
NK
M
K
3
SA
M
K
3
SS
M
C
2
VM
M
C
3
VD
M
C
3
VI
M
C
5
BM
Z
B
3
ML
Z
B
3
GG
Z
B
4
KD
Z
B
3
RM
Z
K
1
NK
Z
K
3
MD
Z
K
5
SJ
Z
K
3
SS
Z
C
4
TD
Z
C
3
VJ
Z
C
2
VS
Z
C
2
Legenda:
POZ
– pozicija u igri;
OKI
– ocjena kvalitete igrača
S obzirom da je unos podataka mukotrpan i vrlo važan dio svakog
istraživanja (jer o točnosti unesenih podataka ovisi i konačna
upotrebljivost rezultata dobivenih statističkom analizom), brzina

Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
53
klase, razreda). Dakle, grupiranje je postupak sažimanja velikog broja
podataka, koji pripadaju osnovnom skupu, u manji broj podskupova.
Broj entiteta koji pripadaju istoj kategoriji (klasi, razredu) naziva se
frekvencija
. Zbroj frekvencija svih grupa jednak je ukupnom broju
entiteta. Ako se entiteti grupiraju po jednom obilježju (primjerice,
spolu), onda se takvo grupiranje naziva
jednodimenzionalno
, a ako se
grupiraju na temelju većeg broja obilježja, onda se naziva
višedimenzionalno
grupiranje.
Tablica 2.3-3 prikazuje jednodimenzionalno grupiranje entiteta.
Grupiranje se izvodi na temelju jedne varijable - uspjeh na ispitu. Od
ukupno 40 studenata koji su pristupili pismenom dijelu ispita, 25 ih
nije položilo ispit, a 15 je položilo.
Tablica 2.3-3.
Primjer jednodimenzionalnog grupiranja prema uspjehu na ispitu
USPJEH NA ISPITU
FREKVENCIJA
NISU POLOŽILI
25
POLOŽILI
15
UKUPNO
40
Tablica 2.3-4 prikazuje dvodimenzionalno grupiranje jer se grupiranje
izvodi po dvije varijable: spol i uspjeh na ispitu. Ispitu je pristupilo 26
studenata i 14 studentica. Od 26 studenata, 16 ih nije položilo ispit, a
10 jest, dok od 14 studentica 9 ih nije položilo, a 5 jest.
Tablica 2.3-4.
Primjer dvodimenzionalnog grupiranja - prema spolu i uspjehu na ispitu
SPOL
NISU POLOŽILI
POLOŽILI
UKUPNO
MUŠKARCI
16
10
26
ŽENE
9
5
14
UKUPNO
25
15
40
Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
54
2.3.2. Grupiranje i grafičko prikazivanje
kvalitativnih podataka
Kvalitativni podaci
grupiraju se tako da se entiteti razvrstaju u
određeni broj kategorija. Primjerice, obilježje uspjeh na ispitu ima dva
oblika (nominalna mjerna skala):
nisu položili
i
položili su
. Grupiranje
se izvodi razvrstavanjem entiteta koji su položili ispit u kategoriju
položili
, a koji nisu u kategoriju
nisu položili
(tablica 2.3-5).
Tablica 2.3-5.
Grupiranje entiteta prema uspjehu na ispitu
(dvije kategorije: nisu položili - položili)
USPJEH NA ISPITU
FREKVENCIJA
%
NISU POLOŽILI
25
62,5
POLOŽILI
15
37,5
UKUPNO
40
100
Entitete je moguće grupirati i prema ocjeni dobivenoj na ispitu
(ordinalna mjerna skala). U tom slučaju postoji pet stupnjevanih
kategorija te ih je potrebno navesti od najniže prema najvišoj ili
obrnuto (tablica 2.3-6).
Tablica 2.3-6.
Grupiranje entiteta prema uspjehu na ispitu
(pet kategorija: nedovoljan, dovoljan, dobar, vrlo dobar, odličan)
USPJEH NA ISPITU
FREKVENCIJA
%
NEDOVOLJAN
25
62,5
DOVOLJAN
8
20
DOBAR
3
7,5
VRLO DOBAR
2
5
ODLIČAN
2
5
UKUPNO
40
100
Radi lakšeg zaključivanja o prolaznosti na ispitu, moguće je izračunati
relativne frekvencije.
Relativna frekvencija izračuna se kao omjer
frekvencije određene kategorije i zbroja frekvencija svih kategorija
(ukupnog broja entiteta).
n
f
p
g
g
;
100
%
n
f
g
g
, g = 1,..,k
gdje je
p
g
relativna frekvencija izražena u proporciji grupe
g (g = 1,..,k)
f
g
frekvencija u grupi
g
%
g
relativna frekvencija izražena u postotku

Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
56
Slika 2.3-2.
Grafikon redaka
Strukturni krug
najčešće se koristi za prikaz relativnih frekvencija
(slika 2.3-3).
2.3.3. Grupiranje i grafičko prikazivanje
kvantitativnih podataka
Vrlo jednostavan postupak za sređivanje kvanitativnih podataka
predstavlja
sortiranje
ili
rangiranje
. Ako se podaci nižu od najmanje
do najveće vrijednosti, onda se takvo sortiranje naziva
uzlazno
, a ako
se nižu od najveće do najmanje, onda se naziva
silazno
. Sortiranje
omogućava uočavanje najmanje (
minimalne
) vrijednosti i najveće
nedovoljan
62,5%
dobar
7,5%
dovoljan
20%
odličan
5%
vrlo dobar
5%
Slika 2.3-3.
Strukturni krug
0
5
10
15
20
25
30
nedovoljan
dovoljan
dobar
vrlo dobar
odličan
Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
57
(
maksimalne
) vrijednosti temeljem kojih je moguće izračunati
totalni
raspon rezultata
.
R = x
max
- x
min
gdje je
R
totalni raspon rezultata
x
max
maksimalna vrijednost
x
min
minimalna vrijednost.
Veća količina kvantitativnih diskretnih podataka s manjim brojem
mogućih vrijednosti najčešće se sređuje postupkom
grupiranja
.
Postupak grupiranja provodi se razvrstavanjem entiteta u podskupove
prema vrijednostima kvantitativog obilježja i to tako da jedan podskup
čine entiteti s jednom vrijednosti kvantitativnog obilježja. Broj entiteta
s jednakom vrijednosti kvantitativnog obilježja predstavlja
frekvenciju
grupe
, a uređeni niz kvantitativnih vrijednosti s pripadajućim
frekvencijama
distribuciju frekvencija
. Primjerice, tablica 2.3-7
prikazuje broj osobnih pogrešaka 18 košarkaša na jednoj košarkaškoj
utakmici.
Tablica 2.3-7.
Broj osobnih pogrešaka (OP) 18 košarkaša na jednoj košarkaškoj utakmici
ENTITETI
OP
ANZU-V
4
ERJA-M
2
KRST-V
1
MILA-D
4
MILL-M
3
NORI-M
1
NOVO-K
4
SAMA-A
2
SUBO-S
3
VANJ-M
5
VOLO-D
3
VUJI-I
2
BAZD-M
3
BLAS-M
3
GIRI-G
4
KRUN-D
3
MALI-M
3
MAMI-M
2
Nakon uzlaznog sortiranja podataka (tablica 2.3-8), lako se uočava
najmanja (1) i najveća vrijednost (5).

Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
59
Slika 2.3-4.
Histogram frekvencija
Histogram frekvencija
je površinski grafički prikaz distribucije
frekvencija u kojem se numeričke vrijednosti obilježja upisuju na
sredini pravokutnika jednakih osnovica čija će visina ovisiti o veličini
frekvencije (slika 2.3-4).
Slika 2.3-5.
Poligon frekvencija
Poligon frekvencija
je linijski grafički prikaz distribucije frekvencija
koji nastaje spajanjem točaka položaj kojih je u koordinatnom sustavu
određen numeričkom vrijednošću obilježja i veličinom frekvencije
(slika 2.3-5).
F
re
kv
e
n
ci
ja
0
1
2
3
4
5
6
7
8
1
2
3
3
5
0
1
2
3
4
5
6
7
8
1
2
3
4
5
Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
60
Ako diskretna varijabla ima veliki broj mogućih vrijednosti ili ako se
radi o kontinuiranoj varijabli, podaci se grupiraju u manji broj razreda.
Za uspješno grupiranje potrebno je odrediti prikladan broj razreda i
njihovu veličinu -
interval razreda
. Broj razreda prije svega ovisi o
broju entiteta i najčešće se kreće između pet i petnaest.
Primjerice, u tablici 2.3-10 prikazano je grupiranje 60 judaša u 5
razreda u varijabli
skok udalj s mjesta
. Vidljivo je da je najveći broj
entiteta u trećem razredu (26 ili 43.33 %), odnosno da najveći broj
judaša u skoku udalj s mjesta postiže vrijednosti koje se nalaze u
intervalu između 161 i 180 cm, dok se broj entiteta s boljim i lošijim
rezultatima smanjuje.
Tablica 2.3-10.
Apsolutne i relativne frekvencije
Intervali razreda
f
rf (%)
120<x<=140
1
1,67
140<x<=160
12
20,00
160<x<=180
26
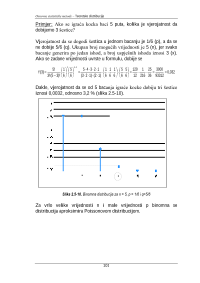
43,33
180<x<=200
16
26,67
200<x<=220
5
8,33
Dobivene frekvencije (apsolutne i relativne) moguće je također
grafički prikazati histogramom (slika 2.3-6) i poligonom frekvencija
(slika 2.3-7).
Histogram frekvencija
crta se tako da osnovicu
pravokutnika određuje interval razreda, a visinu frekvencija pojedinog
razreda.
Slika 2.3-6.
Histogram frekvencija s razredima
F
re
k
v
e
n
c
ij
a
0
5
10
15
20
25
30
35
120
140
160
180
200
220

Osnovne statističke metode – Osnovni postupci za uređivanje i prikazivanje podataka
62
Slika 2.3-8.
Kumulativni poligon frekvencija
Ako se na istoj slici žele prikazati i usporediti dvije ili više distribucija
frekvencija, tada je radi veće preglednosti bolje koristiti poligone
frekvencija (slika 2.3-9).
Slika 2.3-9.
Poligoni frekvencija dviju grupa
0
5
10
15
20
25
30
x<=120
120<x<=140 140<x<=160 160<x<=180 180<x<=200 200<x<=220
220<x
0
10
20
30
40
50
60
120<x<=140
140<x<=160
160<x<=180
180<x<=200
200<x<=220
Osnovne statističke metode – Deskriptivni pokazatelji
63
2.4
Deskriptivni
pokazatelji
Deskriptivni pokazatelji
koriste se za opis varijabli, a dijele se na
mjere centralne tendencije ili središnje mjere, mjere varijabilnosti ili
disperzije te mjere asimetrije i izduženosti distribucije.
2.4.1. Mjere centralne tendencije ili središnje
mjere
Zajedničko obilježje
mjera centralne tendencije
ili
središnjih mjera
jest da svaka od njih predstavlja jednu vrijednost koja bi trebala biti
dobra zamjena za skup svih pojedinačnih vrijednosti, odnosno njihov
najbolji reprezentant. Dakle, težnja je mjera centralne tendencije da
ukažu na vrijednost oko koje postoji tendencija grupiranja rezultata,
odnosno ukazuju na rezultat koji ima najveću vjerojatnost
pojavljivanja. Postoji nekoliko mjera centralne tendencije koje se
razlikuju prema načinu utvrđivanja i mogućnostima primjene. Tako se
najčešće razlikuju
potpune
i
položajne
mjere centralne tendencije.
Potpune mjere centralne tendencije izračunavaju se na temelju svih
podataka. To su:
aritmetička sredina
,
geometrijska sredina
i
harmonijska sredina
. Nasuprot njima,
mod
i
medijan
su određeni
položajem u uređenom nizu podataka. S obzirom na prirodu varijabli,
u kineziološkim istraživanjima najčešće se koriste aritmetička sredina,
mod i medijan, dok se ostale mjere centralne tendencije rijetko
primjenuju.

Osnovne statističke metode – Deskriptivni pokazatelji
65
min
x
x
n
1
i
2
i
aritmetička sredina uvijek se nalazi između minimalne i maksimalne
vrijednosti.
max
min
x
x
x
S obzirom na to da je aritmetička sredina potpuna mjera centralne
tendencije, odnosno da na njenu vrijednost podjednako utječu rezultati
svih entiteta, podložna je promjenama pod utjecajem izrazito niskih ili
visokih pojedinčnih vrijednosti, što može znatno utjecati na njenu
reprezentativnost.
Dokaz:
Treba dokazati da je
n
1
i
2
i
m
x
minimum kada je
x
m
.
n
1
i
2
n
1
i
i
n
1
i
2
i
n
1
i
2
i
2
i
n
1
i
2
i
m
m
2x
x
m
m
2x
x
m
x
S obzirom da je
m
konstanta, onda je izraz
n
i
m
1
2
ekvivalentan izrazu
2
nm
, pa je
2
nm
x
2m
x
m
x
n
1
i
i
n
1
i
2
i
n
1
i
2
i
. Ako dodamo i oduzmemo
2
x
n
tako da
vrijednost izraza ostane ista te zamijenimo
n
i
i
x
1
za
x
n
, tada dobijemo
2
2
2
n
1
i
2
i
n
1
i
2
i
nm
x
2mn
x
n
x
n
x
m
x
.
Daljnjim sređivanjem dobijemo
)
m
x
2m
x
n(
x
n
x
m
x
2
2
2
n
1
i
2
i
n
1
i
2
i
,
odnosno
2
2
n
1
i
2
i
n
1
i
2
i
m)
x
n(
x
n
x
m
x
. Moguće je uočiti da će izraz
2
2
n
1
i
2
i
m)
x
n(
x
n
x
biti minimalan kada je
x
m
, jer je tada
0
m)
x
n(
2
.
Osnovne statističke metode – Deskriptivni pokazatelji
66
Aritmetička sredina varijable dobivene dodavanjem ili
množenjem konstantnom vrijednošću
U praksi se često događa da se svim rezultatima ispitanika u nekoj
varijabli
x
i
dodaje ili oduzima neka konstantna vrijednost
i
i
x
x
'
Aritmetička sredina tako nastale varijable jednaka je aritmetičkoj
sredini originalnih rezultata (prije dodavanja konstante), koja je
uvećana ili umanjena za vrijednost konstante
x
x
'
Primjer:
x
i
x
i
' =x
i
+ 3
1
4
2
5
2
5
3
6
3
6
3
6
3
6
4
7
4
7
5
8
30
60
Ako svaki rezultat ispitanika u nekoj varijabli
x
i
pomnožimo
(ponderiramo) nekom konstantnom vrijednošću
(najčešće radi toga
da se promijeni važnost pojedine varijable u odnosu na neku drugu
varijablu)
i
i
x
x
'
,
Dokaz:
β
x
n
β
n
1
x
n
1
β
x
n
1
'
x
n
1
i
i
n
1
i
i
3
10
30
n
x
x
n
1
i
i
6
10
60
n
x
x
n
i
i
1
,
'
6
3
3
3
x
x
'

Osnovne statističke metode – Deskriptivni pokazatelji
68
Primjer:
x
i1
x
i2
x
i3
y
i
=x
i1
+x
i2
+x
i3
1
3
2
6
2
4
5
11
2
2
1
5
3
5
4
12
3
1
5
9
3
1
4
8
3
5
5
13
4
4
3
11
4
5
1
10
5
3
4
12
30
33
34
97
Diferencijalno ponderirana linearna kombinacija
je nova varijabla
(vektor) nastala zbrajanjem produkata drugih varijabli sa skalarima.
Ako su
x
j
(
j = 1,…,m
) vektori istog reda, a
j
skalari, onda je
m
2
1
j
x
x
x
x
y
m
m
j
j
...
2
1
1
diferencijalno ponderirana linearna kombinacija vektora
x
j
.
Aritmetička sredina tako dobivene varijable jednaka je zbroju
ponderiranih aritmetičkih sredina varijabli uključenih u linearnu
kombinaciju.
m
m
m
j
j
j
x
x
x
x
y
...
2
2
1
1
1
Dokaz:
m
2
1
n
1
i
im
n
1
i
i2
n
1
i
i1
n
1
i
im
n
1
i
i2
n
1
i
i1
n
1
i
im
i2
i1
n
1
i
i
x
...
x
x
x
n
1
...
x
n
1
x
n
1
x
...
x
x
n
1
x
...
x
x
n
1
y
n
1
y
3
10
30
n
x
x
n
1
i
i1
1
3,3
10
33
n
x
x
n
1
i
i2
2
3,4
10
34
n
x
x
n
1
i
i3
3
9,7
10
97
n
y
y
n
1
i
i
9,7
3,4
3,3
3
x
x
x
y
3
2
1
Osnovne statističke metode – Deskriptivni pokazatelji
69
Primjer:
x
i1
x
i2
x
i3
2x
i1
3x
i2
5x
i3
y
i
=2x
i1
+3x
i2
+5x
i3
1
3
2
2
9
10
21
2
4
5
4
12
25
41
2
2
1
4
6
5
15
3
5
4
6
15
20
41
3
1
5
6
3
25
34
3
1
4
6
3
20
29
3
5
5
6
15
25
46
4
4
3
8
12
15
35
4
5
1
8
15
5
28
5
3
4
10
9
20
39
30
33
34
60
99
170
329
Računanje aritmetičkih sredina matričnom algebrom
Ako je
X
matrica podataka dobivena opisivanjem nekog skupa od
n
entiteta skupom od
m
varijabli
X
= (x
ij
)
gdje je
i = 1,…,n
, a
j = 1,…,m
, tada se vektor aritmetičkih sredina
m
dobije operacijom
Dokaz:
m
m
2
2
1
1
n
1
i
im
m
n
1
i
i2
2
n
1
i
i1
1
n
1
i
im
m
n
1
i
i2
2
n
1
i
i1
1
n
1
i
im
m
i2
2
i1
1
n
1
i
i
x
...
x
x
x
n
1
...
x
n
1
x
n
1
x
...
x
x
n
1
x
...
x
x
n
1
y
n
1
y
3
10
30
n
x
x
n
1
i
i1
1
;
3,3
10
33
n
x
x
n
1
i
i2
2
;
3,4
10
34
n
x
x
n
1
i
i3
3
32,9
10
329
n
y
y
n
1
i
i
;
32,9
3,4
5
3,3
3
3
2
x
5
x
3
x
2
y
3
2
1

Osnovne statističke metode – Deskriptivni pokazatelji
71
Primjer:
10 entiteta je postiglo sljedeće rezultate u nekom
motoričkom testu: 1, 2, 2, 3, 3, 3, 3, 4, 4, 5. Mod je jednak
o
= 3.
Ocjena
f
1
1
2
2
3
4
4
2
5
1
Kod kontinuiranih kvantitativnih varijabli određivanje modalne
vrijednosti je otežano. Moguće je utvrditi razred u kojem se mod
nalazi. Modalni razred je onaj s najvećom frekvencijom. Da bismo
unutar modalnog razreda utvrdili mod, koristimo pretpostavku da na
njegovu vrijednost utječu frekvencije susjednih razreda. Stoga je mod
moguće aproksimativno odrediti pomoću formule
I
c
b
a
b
a
b
L
o
)
(
)
(
)
(
1
gdje je
L
1
donja granica modalnog razreda
a
frekvencija ispred modalnog razreda
b
frekvencija modalnog razreda
c
frekvencija iza modalnog razreda
I
interval modalnog razreda
Primjer:
U tablici 2.4-1 prikazano je grupiranje 60 judaša u 5 razreda
u varijabli
skok udalj s mjesta
. Vidljivo je da je najveći broj entiteta u
trećem razredu (26), odnosno da najveći broj judaša u skoku u dalj s
mjesta ima vrijednosti koje se nalaze u intervalu između 161 i 180 cm.
Tablica 2.4-1.
Tablica frekvencija
Intervali razreda
f
120<x<=140
1
140<x<=160
12
160<x<=180
26
180<x<=200
16
200<x<=220
5
6
,
172
66
,
11
161
20
24
14
161
20
)
16
26
(
)
12
26
(
)
12
26
(
161
o
Osnovne statističke metode – Deskriptivni pokazatelji
72
Dakle, aproksimativna modalna vrijednost je 172,6 (slika 2.4-1).
Ovako aproksimativno utvrđena modalna vrijednost ne mora nužno
imati najveću frekvenciju.
Slika 2.4-1.
Histogram frekvencija
2.4.1.3. Medijan ili centralna vrijednost
Medijan
je vrijednost koja se nalazi na sredini uređenog niza podataka
(uzlazno ili silazno sortiranog), odnosno vrijednost koja uređeni niz
podataka dijeli na dva jednakobrojna dijela. Medijan je moguće
odrediti za negrupirane i grupirane ordinalne te kvantitativne diskretne
i kontinuirane varijable.
Medijan negrupiranih podataka moguće je odrediti nakon uzlaznog ili
silaznog uređenja (sortiranja) podataka. Ako je broj podataka neparan,
onda medijan predstavlja vrijednost središnjeg člana tj. entiteta (
x
r
)
e
= x
r
gdje je
2
1
n
r
Ako je broj podataka paran, onda je medijan jednak aritmetičkoj
sredini vrijednosti dvaju središnjih članova uređenog niza.
o
a
b-a
b-c
b
c
L
1

Osnovne statističke metode – Deskriptivni pokazatelji
74
I
interval medijalnog razreda
Primjer:
Neka su rezultati 60 entiteta u varijabli
skok udalj s mjesta
dani kao distribucija frekvencija:
Intervali razreda
f
cf
120<x<=140
1
1
140<x<=160
12
13
160<x<=180
26
39
180<x<=200
16
55
200<x<=220
5
60
L
1
= 161;
f
1
= 13; f
med
= 26; I = 20
174.07
13.07
161
20
26
13
30
161
I
f
f
2
n
L
μ
med
1
1
e
Na medijan i mod ne utječu ekstremno visoki ili niski rezultati pa
bolje reprezentiraju pozitivno i negativno asimetrično distribuirane
varijable.
2.4.2. Mjere varijabilnosti ili disperzije
Za dobru deskripciju analizirane pojave nije dostatno samo izračunati
mjere centralne tendencije. Ako se rezultati entiteta grupiraju oko
neke središnje vrijednosti, onda odgovarajuća mjera centralne
tendencije može biti dobar reprezentant analiziranih podataka. Ako
rezultati malo variraju oko aritmetičke sredine, onda ih ona bolje
reprezentira nego kad podaci znatno variraju. Dvije se varijable, koje
se ne razlikuju po mjeri centralne tendencije, mogu razlikovati po
raspršenosti (disperziji) podataka. Kada bi podaci bili međusobno
jednaki, tada ne bi bilo varijabilnosti, a tendencija grupiranja rezultata
bila bi maksimalna. Ako bi se pri mjerenju nekog obilježja na nekoj
mjernoj skali uvijek dobivale različite vrijednosti, tada ne bi bilo
nikakvog grupiranja rezultata, a varijabilnost bi bila maksimalna (slika
2.4-2).
Osnovne statističke metode – Deskriptivni pokazatelji
75
Slika 2.4-2.
Prikaz dva ekstremna slučaja: 1. nema varijabilnosti (maksimalno grupiranje
rezultata); 2. maksimalna varijabilnost (nema grupiranja rezultata)
U stvarnosti se, međutim, takvi ekstremni slučajevi gotovo nikad ne
događaju, već se prikupljeni podaci uglavnom, manje ili više,
grupiraju oko neke središnje vrijednosti. Grupiranje se može
procijeniti
mjerama varijabilnosti
ili
disperzije
. Za opis disperzije
varijabli u kineziološkim istraživanjima najčešće se koriste
totalni
raspon
,
interkvartil
,
varijanca
i
standardna devijacija
.
2.4.2.1. Totalni raspon
Totalni raspon
(
R
tot
) je najjednostavnija mjera varijabilnosti, a
utvrđuje se kao razlika između maksimalne (
x
max
) i minimalne (
x
min
)
vrijednosti.
min
max
tot
x
x
R
Totalni raspon se iskazuje u mjernim jedinicama varijable, a s
obzirom da zavisi samo od dva podatka (maksimalnog i minimalnog),
ekstremni rezultati znatno utječu na njegovu vrijednost. Osim toga,
lako je uočiti da se s povećanjem broja entiteta u uzorku obično
povećava i totalni raspon jer se povećava vjerojatnost uključivanja
entiteta s ekstremnim (maksimalnim i minimalnim) vrijednostima.
Stoga je raspon vrlo nesigurna mjera varijabilnosti.
F
REZULTATI
F
1
REZULTATI

Osnovne statističke metode – Deskriptivni pokazatelji
77
2.4.2.3. Varijanca i standardna devijacija
Stupanj raspršenosti moguće je procijeniti i putem odstupanja
rezultata entiteta od neke središnje vrijednosti, najčešće aritmetičke
sredine. Dakle, potrebno je izračunati odstupanja vrijednosti svakog
entiteta u određenoj varijabili od aritmetičke sredine te varijable.
x
x
d
i
i
Temeljem tih odstupanja (
d
i
) moguće je izračunati mjeru varijabilnosti
jer veća odstupanja ukazuju na veću raspršenost podataka. Iz toga
slijedi da je stupanj varijabilnosti podataka moguće iskazati putem
aritmetičke sredine izračunatih odstupanja. Međutim, takva bi
operacija kao rezultat dala
nulu
jer je aritmetička sredina težište
rezultata, odnosno zbroj odstupanja svih pojedinačnih rezultata od
aritmetičke sredine jednak je
nuli
.
n
1
i
i
0
d
Ovaj problem moguće je riješiti kvadriranjem. Na taj način dobiveno
prosječno kvadratno odstupanje rezultata entiteta od aritmetičke
sredine varijable naziva se
varijanca
.
n
d
n
x
x
n
i
i
n
i
i
1
2
1
2
2
)
(
S obzirom na to da je varijanca prosječno kvadratno odstupanje,
otežano je njezino interpretiranje. Da bi se izračunata mjera
raspršenosti svela na mjernu jedinicu varijable, potrebno je iz
varijance izračunati drugi korijen. Tako izračunata mjera varijabilnosti
naziva se
standardna devijacija (
)
.
n
d
n
x
x
n
i
i
n
i
i
1
2
1
2
2
)
(
Daljnjim razvojem ove formule može se dobiti formula koja
omogućava ekonomičnije izračunavanje zato što nije potrebno
Osnovne statističke metode – Deskriptivni pokazatelji
78
izračunavati pojedinačne distance između rezultata svakog entiteta i
aritmetičke sredine niti kvadrirati te distance.
2
n
1
i
i
n
1
i
2
i
x
x
n
n
1
σ
Želi li se izračunati standardna devijacija nekog uzorka entiteta,
temeljem koje se procjenjuje standardna devijacija populacije koje je
odabrani uzorak reprezentant, onda se standardna devijacija računa s
nazivnikom
n-1
umjesto
n
.
1
n
)
x
x
(
s
n
1
i
2
i
Izvod:
Kvadriranjem binoma u zagradi dobijemo
n
1
i
2
i
2
i
n
1
i
2
i
2
x
x
2x
x
n
1
x
x
n
1
σ
,
što je ekvivalentno izrazu
n
1
i
2
n
1
i
i
n
1
i
2
i
2
x
x
2x
x
n
1
σ
.
Množenjem sa
1/n
dobijemo
2
n
1
i
2
i
n
1
i
2
n
1
i
i
n
1
i
2
i
2
x
x
2
x
n
1
x
n
1
x
2x
n
1
x
n
1
σ
2
jer je
n
i
x
1
2
ekvivalentan izrazu
2
x
n
.
Daljnjim sređivanjem dobijemo
2
n
1
i
i
2
n
1
i
2
i
2
n
1
i
2
i
2
x
n
1
x
n
1
x
x
n
1
σ
.
Množenjem sa
n
2
dobijemo
2
2
n
1
i
i
n
1
i
2
i
n
1
i
i
2
2
n
1
i
2
i
2
2
2
x
x
n
x
n
n
x
n
n
σ
n
. Množenjem sa
1/n
2
dobijemo
2
n
1
i
i
n
1
i
2
i
2
2
x
x
n
n
1
σ
, pa je standardna devijacija jednaka
2
n
1
i
i
n
1
i
2
i
x
x
n
n
1
σ
.

Osnovne statističke metode – Deskriptivni pokazatelji
80
'
Ako svaki rezultat ispitanika u nekoj varijabli
x
i
pomnožimo
(ponderiramo) nekom konstantnom pozitivnom vrijednošću
i
i
x
x
'
,
onda je varijanca ovako nastale varijable jednaka varijanci originalnih
rezultata
koja je pomnožena s kvadratnom vrijednošću konstante
2
2
2
'
,
a standardna je devijacija jednaka standardnoj devijaciji originalnih
rezultata koja je pomnožena vrijednošću konstante
2
2
'
Dokaz:
2
n
1
i
i
n
1
i
i
n
1
i
,
i
2
σ
x
x
n
1
)
x
(β
)
x
(β
n
1
x
x
n
1
'
σ
2
2
2
2
2
,
2
2
σ'
Dokaz:
n
1
i
i
n
1
i
i
n
1
i
i
n
1
i
,
i
2
x
x
n
1
β
β
x
x
n
1
β)
x
(
β)
(x
n
1
x
x
n
1
'
σ
2
2
2
2
,
Osnovne statističke metode – Deskriptivni pokazatelji
81
Varijanca i standardna devijacija linearne kombinacije varijabli
Ako je
m
2
1
j
x
x
x
x
y
...
1
m
j
jednostavna linearna kombinacija
x
j
(
j = 1,…,m
) varijabli istog reda,
onda je varijanca ovako dobivene varijable jednaka zbroju varijanci i
dvostrukom zbroju kovarijanci između varijabli uključenih u linearnu
kombinaciju
m
1
k
j,
jk
m
1
j
2
j
2
y
c
2
σ
σ
;
j,k=1,...,m (j
k),
gdje je
n
d
d
n
x
x
x
x
c
n
i
ik
ij
n
i
k
ik
j
ij
jk
1
1
)
)(
(
;
i=1,...,n
kovarijanca između varijabli
j
i
k
. S obzirom da je Pearsonov
koeficijent korelacija između varijabla
j
i
k
(v. poglavlje 2.11. str. 160-
179) jednak,
k
j
n
i
ik
ij
jk
n
d
d
r
1
množenjem obiju strana formule sa
j
i
k
, dobije se
jk
n
i
ik
ij
k
j
jk
c
n
d
d
r
1
Tako se formula za izračunavanje varijance linearne kombinacije
varijabli može napisati u sljedećem obliku
k
j
m
1
k
j,
jk
m
1
j
2
j
2
y
r
2
σ
σ
;
j,k=1,...,m (j
k)
Ako su
x
j
(
j = 1,…,m
) vektori istog reda, a
j
skalari, onda je
m
2
1
j
x
x
x
x
y
m
m
j
j
...
2
1
1

Osnovne statističke metode – Deskriptivni pokazatelji
83
n
x
x
x
x
c
n
i
i
i
1
2
2
1
1
12
)
)(
(
Matrica kovarijanci
C
varijabli iz
X
izračuna se operacijom
C
=
X
c
T
X
c
n
-1
,
gdje je
X
c
matrica centriranih podataka početnih vrijednosti matrice
X
.
Matrica centriranih podataka
X
c
dobije se operacijom
X
c
=
X
-
1m
T
,
gdje je
1
sumacijski vektor sa
m
jedinica, a
m
=
X
T
1
n
-1
vektor
aritmetičkih sredina, gdje je
1
sumacijski vektor sa
n
jedinica, ili
operacijom
X
c
= (
X
-
PX
)
,
gdje je
P=1
(
1
T
1
)
-1
1
T
ili
P=11
T
n
-1
lijevi centroidni projektor matrice
X
,
a
1
sumacijski vektor sa
n
jedinica. Matricu kovarijanci
C
moguće je
izračunati i sljedećim formulama
C
=
X
c
T
X
c
n
-1
=
(
X
-
PX
)
T
(
X
-
PX
)
n
-1
=
(
X
T
X
-
X
T
PX
-
X
T
PX
+
X
T
PPX
)n
-1
=
(
X
T
X
-
X
T
PX
) n
-1
jer je
PP
=
P
.
C
=
X
c
T
X
c
n
-1
=
(
X
-
1m
T
)
T
(X
-
1m
T
)n
-1
=
(
X
T
-
m1
T
)
(X
-
1m
T
)n
-1
=
(
X
T
X
-
X
T
1m
-
m1
T
X
+
m1
T
1m
T
)n
-1
=
(
X
T
X
-
mm
T
n)n
-1
jer je
X
T
1m
=
m1
T
X
, a
1
T
1
= n
.
Ekstrakcijom dijagonale matrice kovarijanci
C
dobije se dijagonalna
matrica varijanci
V
2
=diag
C
, a operacijom
V
= (diag
C
)
1/2
dijagonalna
matrica standardnih devijacija
V
.
Osnovne statističke metode – Deskriptivni pokazatelji
84
Primjer:
9 ispitanika postiglo je sljedeće rezultate u
skoku udalj
(SD),
trčanju na 100 metara
(T100m) i
bacanju kugle
(BK). Potrebno je izračunati
standardne devijacije navedenih varijabli uz pomoć matrične algebre.
Matrica centriranih podataka
X
c
dobije se operacijom
X
c
=
X
-
1m
T
,
gdje je
1
sumacijski vektor sa
n
jedinica, a
m
=
X
T
1
n
-1
vektor
aritmetičkih sredina.
SD
T100m
BK
359
13,6
561
321
13,9
550
346
13,7
538
332
14
490
450
12,2
518
314
14,1
551
410
12,5
589
425
12,3
602
369
13,5
547
X
=
1
1
1
1
1
1
1
1
1
SD
T100m
BK
369,56
13,31
549,56
SD
T100m
BK
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
1
m
T
=
SD
T100m
BK
359
13,6
561
321
13,9
550
346
13,7
538
332
14
490
450
12,2
518
314
14,1
551
410
12,5
589
425
12,3
602
369
13,5
547
X
SD
T100m
BK
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
1 m
T
SD
T100m
BK
-10,56
0,29
11,44
-48,56
0,59
0,44
-23,56
0,39
-11,56
-37,56
0,69
-59,56
80,44
-1,11
-31,56
-55,56
0,79
1,44
40,44
-0,81
39,44
55,44
-1,01
52,44
-0,56
0,19
-2,56
X
c
-
=

Osnovne statističke metode – Deskriptivni pokazatelji
86
izračunava se kao omjer standardne devijacije (
) i aritmetičke sredine
(
x
) pomnožen sa
100
.
100
x
σ
V
Koeficijent varijabilnosti pokazuje u kojoj varijabli ista grupa entiteta
manje ili više varira te koja grupa manje ili više varira u istoj varijabli.
2.4.3. Mjere asimetrije distribucije (
engl.
skewness
)
Ako su frekvencije rezultata u nekoj varijabli ravnomjerno
raspodijeljene lijevo i desno od prosječne vrijednosti, tada se radi o
simetričnoj
distribuciji podataka (slika 2.4-3). Kod
unimodalne
(distribucija koja ima jednu modalnu vrijednost) simetrične
distribucije aritmetička sredina, mod i medijan jednake su vrijednosti
(
x =
o
=
e
). Ako frekvencije rezultata nisu ravnomjerno
raspodijeljene lijevo i desno od prosječne vrijednosti, tada se radi o
pozitivno
ili
negativno asimetričnoj
distribuciji podataka.
Slika 2.4-3.
Simetrična unimodalna distribucija
Ako se većina entiteta grupirala u zoni nižih vrijednosti s nekolicinom
ekstremno visokih vrijednosti, takva se distribucija podataka zove
pozitivno asimetrična
(slika 2.4-4). Kod pozitivno asimetrične
distribucije aritmetička sredina, mod i medijan nisu međusobno
jednaki. Najveću vrijednost ima aritmetička sredina, zatim medijan pa
mod (
x >
e
>
o
).
x
o
e
Osnovne statističke metode – Deskriptivni pokazatelji
87
Slika 2.4-4.
Pozitivno asimetrična distribucija rezultata
Kod
negativno asimetrične
distribucije (slika 2.4-5) grupiranje entiteta
je u zoni viših vrijednosti, a manjim brojem entiteta u zoni ekstremno
niskih vrijednosti (obrnuto od pozitivno asimetrične distribucije
podataka). U negativno asimetričnim distribucijama aritmetička
sredina je najmanja, a zatim po veličini slijede medijan i mod
(
x <
e
<
o
).
Slika 2.4-5.
Negativno asimetrična distribucija rezultata
x
e
o
o
e
x

Osnovne statističke metode – Deskriptivni pokazatelji
89
4
4
4
m
a
Četvrti moment oko sredine izračuna se formulom
n
x
x
m
n
1
i
4
i
4
Ako je koeficijent spljoštenosti:
a
4
=3
- distribucija je
mezokurtična
- normalna
a
4
>3 -
distribucija je
leptokurtična
- izdužena
a
4
<3
- distribucija je
platikurtična
- spljoštena (slika 2.4-6).
Slika 2.4-6.
Platikurtična, mezokurtična i leptokurtična distribucija podataka
platikurtična
mezokurtična
leptokurtična
a
4
< 3
a
4
= 3
a
4
> 3
Osnovne statističke metode – Teoretske distribucije
90
2.5
Teoretske
distribucije
Za razliku od distribucija eksperimentalno prikupljenih podataka, koje
se nazivaju
empirijskim distribucijama
,
teoretske distribucije
su
zadane matematičkom formulom, odnosno one predstavljaju
matematičke funkcije te omogućavaju utvrđivanje
vjerojatnosti
nekog
slučajnog događaja u zadanim uvjetima. Teoretske se distribucije
koriste kao matematički modeli za opisivanje većeg broja statističkih
pojava. S obzirom da statistički podaci mogu imati diskretna
(izražavaju konačan broj vrijednosti mjerenog svojstva i uvijek su
određene cijelim brojem) i kontinuirana (mogu poprimiti bilo koju
numeričku vrijednost) obilježja, moguće je razlikovati
diskretne
(uniformna
distribucija,
binomna
distribucija,
Poissonova
distribucija
) i
kontinuirane
(
normalna distribucija, t-distribucija, F-
distribucija,
2
-distribucija
) teoretske distribucije. Međutim, prije
negoli opišemo navedene teoretske distribucije, potrebno je upoznati
se s elementarnim pojmovima teorije vjerojatnosti.

Osnovne statističke metode – Teoretske distribucije
92
Primjer:
Na koliko je načina moguće obojiti tri prazna kružića ako je
prvi moguće obojiti crvenom, bijelom i plavom bojom, drugi crnom,
zelenom i žutom, a treći narančastom i ljubičastom bojom?
Ukupan broj elementarnih događaja iznosi
3
3
2
=
18
. Dakle,
kružiće je moguće obojiti na
18
načina. U tablici 2.5-2 prikazan je
skup svih mogućih načina (elementarnih događaja) na koje je moguće
obojiti kružiće prema navedenom pravilu.
Tablica 2.5-2.
Svi elementarni događaji koje je moguće dobiti bojenjem triju praznih kružića
prema navedenom pravilu
2.5.1.2. Pravilo permutacija
Ako su
x
1
, x
2
,…,x
n
elementi nekog skupa, na koliko ih je načina
moguće poredati? Svaka međusobno različita kombinacija elemenata
x
1
, x
2
,…,x
n
naziva se
permutacija
. Moguće je razlikovati
permutacije
bez ponavljanja
i
permutacije s ponavljanjima
.
Permutacije bez ponavljanja
Dakle, ako su
x
1
, x
2
,…, x
n
elementi nekog skupa, moguće ih je
poredati na
1
2
2).....3
(n
1)
(n
n
načina, odnosno
!
n
P
)
n
(
gdje je
P
(n)
broj mogućih permutacija (elementarnih događaja) za
n
različitih elemenata
n!
(čitamo: “n faktorijel”) predstavlja produkt prirodnih brojeva od
1
do
n
(prema dogovoru
0! = 1
).
Primjerice, imamo četiri prazna kružića koja je potrebno obojiti
plavom, crvenom, žutom i zelenom bojom. Pri tome je svaki kružić
Osnovne statističke metode – Teoretske distribucije
93
potrebno obojiti drugom bojom. Ukupan broj svih mogućih
elementarnih događaja iznosi
24
1
2
3
4
4!
n!
P
(n)
U tablici 2.5-3 prikazani su svi mogući načini (permutacije) na koje je
moguće obojiti četiri kružića, tako da se za svaki kružić koristi po
jedna od četiri boje.
Tablica 2.5-3.
Svi elementarni događaji koje je moguće dobiti bojenjem četiriju praznih
kružića prema navedenom pravilu
Iz ovog primjera vidi se da je prvi kružić moguće obojiti
4
bojama, za
drugi je moguće koristiti jednu od
3
preostale boje, za treći jednu od
2
preostale, a za posljednji kružić ostaje samo jedna boja.
Primjer:
Ako
8
trkača sudjeluje u nekoj finalnoj trci, koliko je
mogućih ishoda trke?
Broj mogućih ishoda moguće je izračunati pravilom permutacije,
odnosno formulom
40320
1
2
3
4
5
6
7
8
!
8
P
)
8
(
Dakle, broj mogućih ishoda trke u kojoj sudjeluje
8
trkača iznosi
40320
.
Permutacija s ponavljanjem
Ako je od
n
elemenata njih
r
1
, r
2,
…,r
k
jednakih, tada svaki mogući
poredak tih
n
elemenata predstavlja jednu
permutaciju s
ponavljanjem
. Broj permutacija s ponavljanjem moguće je izračunati
formulom

Osnovne statističke metode – Teoretske distribucije
95
2.5.1.3. Pravilo varijacija
Moguće je razlikovati
varijacije bez ponavljanja
i
varijacije s
ponavljanjima
.
Varijacije bez ponavljanja
Ako iz nekog skupa od
n
različitih elemenata formiramo kombinacije
(razrede) od
r
elemenata, a da se isti element ne pojavi dva ili više
puta u istoj kombinaciji (razredu), onda se broj mogućih ishoda
izračuna prema formuli
)!
r
n
(
!
n
V
)
n
(
r
gdje je
V
r
(n)
broj varijacija bez ponavljanja
n
-tog reda i
r
-tog razreda
n
broj svih elemenata u skupu
r
broj elemenata u traženoj kombinaciji (razredu).
Primjer:
Na koliko je različitih načina moguće posložiti
2
kuglice (
r
)
od ukupno
5
kuglica (
n
) različitih boja (plava, crvena, žuta, zelena i
bijela), a da se ista kuglica ne pojavi dva ili više puta u jednom
razredu? Broj mogućih ishoda je
20
6
120
1
2
3
1
2
3
4
5
)!
2
5
(
!
5
V
)
5
(
2
Tablica 2.5-5 prikazuje sve moguće varijacije za
n=5
, a
r=2
, odnosno
prikazani su svi mogući načini na koje je moguće posložiti dvije od
pet kuglica različitih boja.
Tablica 2.5-5.
Svi elementarni događaji (ishodi) koje je moguće dobiti slaganjem dviju od pet
kuglica različitih boja, a da se ista kuglica ne pojavi dva ili više puta
Osnovne statističke metode – Teoretske distribucije
96
Primjer:
Želimo li prognozirati redoslijed prva
3
od ukupno
8
trkača
koji sudjeluju u nekoj finalnoj trci, postavlja se pitanje: koliko je
mogućih ishoda? Broj mogućih ishoda izračunava se formulom za
varijacije bez ponavljanja
336
120
40320
1
2
3
4
5
1
2
3
4
5
6
7
8
)!
3
8
(
!
8
V
)
8
(
3
Varijacije s ponavljanjem
Ako iz nekog skupa od
n
različitih elemenata formiramo kombinacije
(razrede) od
r
elemenata, a da pri tom dopustimo da se u istoj
kombinaciji jedan element pojavi dva ili više puta, onda se broj
mogućih ishoda izračuna prema formuli
r
)
n
(
r
n
V
,
gdje je
)
n
(
r
V
broj varijacija s ponavljanjem
n
-tog reda i
r
-tog razreda
n
broj svih elemenata u skupu, a
r
broj elemenata u traženoj kombinaciji (razredu).
Primjerice, na koliko različitih načina možemo posložiti
2
kuglice (
r
)
od ukupno
5
kuglica (
n
) različitih boja (plava, crvena, žuta, zelena i
bijela), a da se ista kuglica može pojaviti više puta u jednom razredu?
Broj mogućih ishoda moguće je izračunati formulom
25
5
V
2
)
5
(
2
Tablica 2.5-6 prikazuje sve moguće varijacije s ponavljanjem za
n=5
,
a
r=2
.
Tablica 2.5-6.
Svi elementarni događaji koje je moguće dobiti slaganjem dviju od pet kuglica
različitih boja, a da se ista kuglica može pojaviti u istom razredu dva ili više puta

Osnovne statističke metode – Teoretske distribucije
98
Primjer:
Koliko je mogućih uzoraka (kombinacija) ako od
45
brojeva
formiramo uzorke od po
6
brojeva (“loto 6 od 45”)? Broj mogućih
kombinacija izračuna se formulom za kombinacije bez ponavljanja
8145060
1
2
3
4
5
6
40
...
44
45
1
...
38
39
1
2
3
4
5
6
1
...
44
45
6)!
(45
6!
45!
K
)
8
(
3
Dakle, moguće je dobiti
8 145 060
različitih kombinacija (ishoda).
2.5.1.5. Vjerojatnost
Elementarne događaje moguće je podijeliti na one s
povoljnim
i na
one s
nepovoljnim ishodom
. Ako u skupu od
n
elementarnih događaja
x
-om označimo elementarne događaje s povoljnim ishodom, onda
omjer elementarnih događaja s povoljnim ishodom
x
i skupa
elementarnih događaja
n
predstavlja
vjerojatnost
da će se elementarni
događaj s povoljnim ishodom
x
dogoditi
n
x
)
x
(
p
, a
p
1
n
x
1
n
x
n
)
x
(
q
predstavlja vjerojatnost da se elementarni događaj s povoljnim
ishodom
x
neće dogoditi. Dakle, može se reći da je vjerojatnost broj
koji pokazuje šanse za pojavljivanje nekog elementarnog događaja.
Iz navedenih formula vidi se da je:
p(x) + q(x) =1,
pa je
1- p(x)= q(x),
a
1- q(x)= p(x)
0
p(x)
1
i
0
q(x)
1
ako je
p(x) = 1
(apsolutna sigurnost da će se događaj
x
dogoditi),
onda je
q(x) = 0
(apsolutna sigurnost da se događaj
x
neće dogoditi),
i obrnuto.
Osnovne statističke metode – Teoretske distribucije
99
2.5.2. Diskretne teoretske distribucije
2.5.2.1. Uniformna distribucija
Uniformna distribucija
je najjednostavnija diskretna teoretska
distribucija, a osnovna joj je karakteristika jednaka vjerojatnost
ostvarenja svake vrijednosti slučajne varijable
x
(elementarnog
događaja). Neka slučajna varijabla
x
ima uniformnu distribuciju ako je
vjerojatnost bilo koje njene vrijednosti (elementarnog događaja) u
skupu od
n
elementarnih događaja jednaka
n
1
)
x
(
p
,
gdje je
p(x)
vjerojatnost elementarnog događaja
x = 1,..,n
n
ukupan broj vrijednosti koje može imati slučajna varijabla
x
.
Primjerice, ako bacamo pravilnu igraću kocku, vjerojatnost da se
dogodi svaka od šest mogućih vrijednosti je jednaka. S obzirom da je
n=6
, onda je vjerojatnost za bilo koju od šest mogućih vrijednosti
(elementarnih događaja) jednaka
p(x)=1/6=0,1666...
(slika 2.5-8).
Slika 2.5-8.
Uniformna distribucija za n=6

Osnovne statističke metode – Teoretske distribucije
101
Primjer:
Ako se igraća kocka baci
5
puta, kolika je vjerojatnost da
dobijemo
3
šestice?
Vjerojatnost da se dogodi šestica u jednom bacanju je
1/6
(
p
), a da se
ne dobije
5/6
(
q
). Ukupan broj mogućih vrijednosti je
5
(
n
), jer svako
bacanje generira po jedan ishod, a broj uspješnih ishoda iznosi
3
(
x
).
Ako se zadane vrijednosti uvrste u formulu, dobije se
0,032
93312
3000
36
25
216
1
12
120
6
5
6
5
6
1
6
1
6
1
1)
(2
1)
2
(3
1
2
3
4
5
6
5
6
1
3)!
(5
3!
5!
(3)
f
3
5
3
Dakle, vjerojatnost da se od
5
bacanja igraće kocke dobiju tri šestice
iznosi
0,0032
, odnosno
3,2 %
(slika 2.5-10).
Slika 2.5-10.
Binomna distribucija za n = 5, p = 1/6 i q=5/6
Za vrlo velike vrijednosti
n
i male vrijednosti
p
binomna
se
distribucija aproksimira
Poissonovom distribucijom
.
Osnovne statističke metode – Teoretske distribucije
102
0
5
10
15
20
25
30
nedovoljan
dovoljan
dobar
vrlo dobar
odličan
Siméon Poisson
(1781. – 1840.) francuski
matematičar. Od 1798. studira matematiku
na Ecole
Polytechnique
kod znamenitih matematičara
Laplacea i Lagrangea s kojima postaje prijatelj.
Predaje na
Ecole Polytechnique
od 1802. do 1808.,
a od 1809. godine predaje teorijsku matematiku u
novootvorenom
Faculté des Sciences
. Publicirao je
puno radova (preko 300). Jedan od važnijih radova
objavio je 1837. godine u kome je opisao
distribuciju rijetkih događaja koja je po njemu dobila ime. Njegovi radovi su
uvelike pridonijeli razvoju matematike, fizike i astronomije.
Prema, J J O'Connor and E F Robertson: http://www-groups.dcs.st-
and.ac.uk/%7Ehistory/Mathematicians/Poisson.html
3
10
30
x
15
,
1
33
,
1
9
12
1
)
(
1
2
n
x
x
s
N
i
i
2.5.2.3. Poissonova distribucija
Poissonova distribucija
aproksimira
binomnu distribuciju
za velike
vrijednosti
n
(npr.
n>50
) i male vrijednosti
p
(npr.
p<0,05
), pa
predstavlja njen ekstreman slučaj. Stoga se
Poissonova distribucija
naziva i
distribucijom
rijetkih događaja
. Ako
se
= n
p
tretira kao
konstanta, jer
n
teži
beskonačnom (
n
),
a
p
nuli (
p
0
), onda je
vjerojatnost
nekog
događaja
x
jednaka
e
x
x
p
x
!
)
(
,
gdje je
p(x)
vjerojatnost događaja
x = 0,1,..,n
e
baza prirodnog logaritma (
e =2,71828
)
=n
p
parametar
Poissonove distribucije
(
n -
ukupan broj opažanja,
entiteta, događaja, eksperimenata, a
p -
vjerojatnost povoljnog
ishoda, događaja).
Poissonova distribucija
ima pozitivno asimetričan oblik s očekivanom
vrijednošću (
) i varijancom (
2
)
E(x) =
=
2
=
te koeficijentom asimetrije
1
a
3
i koeficijentom spljoštenosti
1
3
a
4
Oblik
Poissonove distribucije
zavisit će isključivo od veličine
parametra
. S obzirom da slučajna varijabla
x
ne može imati
vrijednosti manje od nule (
x =0,1,2,...
), s povećanjem parametra
distribucija teži simetričnosti (slika 2.5-11).

Osnovne statističke metode – Teoretske distribucije
104
Carl Friedrich Gauss
(1777.- 1855.) jedan
je od najvećih matematičara. Rodio se u vrlo
siromašnoj obitelji koja nije imala novca za
njegovo školovanje. U početku mu je
školovanje omogućio ujak. Negov iznimni
matematički talent primijetili su već u
djetinjstvu njegovi učitelji Büttner i Bartels
kada je mali Gauss za nekoliko trenutaka
zbrojio cijele brojeve od 1 do 100 uvidjevši
da se radi o zbroju 50 parova čiji je zbroj
101. Uz njihovu pomoć Gauss započinje školovanje te dobiva bogatog
mecenu grofa Carla Wilhelma Ferninanda uz čiju pomoć od 1792. godine
pohađa Brunswick Collegium Carolinum. Od 1795. godine nastavlja
studiranje na Sveučilištu u Göttingenu gdje diplomira i postiže prve
znanstvene rezultate. Nakon diplome doktorirao je na Sveučilištu u
Helmstedtu (1799.) te se predaje istraživačkom radu. Godine 1801.
objavljuje svoju prvu znamenitu knjigu
Disquisitiones Arithmeticae
, a 1809.
drugu knjigu pod nazivom
Theoria motus corporum coelestium in
sectionibus conicis Solem ambientium
, u kojoj raspravlja o gibanju
nebeskih tijela. Za metodologiju znanstveno-istraživačkog rada u biološkim
i društvenim znanostima posebno je značajno njegovo djelo
Theoria
combinationis observationum erroribus minimis obnoxiae
(1823), koje je
posvećeno matematičkoj statistici, posebice metodi najmanjih kvadrata i
normalnoj krivulji, koja se u njegovu čast naziva Gaussovom krivuljom.
Prema,Kolesarić i Petz, 1999, i
http://de.wikipedia.org/wiki/Carl_Friedrich_Gauss
2.5.3. Kontinuirane teoretske distribucije
2.5.3.1. Normalna distribucija
Normalna distribucija
sigurno je najvažnija i najčešće korištena
kontinuirana teoretska distribucija u statističkim analizama (slika 2.5-
13). Naziva se još i
Gaussovom distribucijom
jer se smatra da ju je
Gauss prvi matematički definirao. Osim Gaussa, u definiranju
normalne
raspodjele
značajnu ulogu imali su
Laplace
1
i De Moivre
2
.
Za slučajnu kontinuiranu
varijablu
x
kaže se da ima
normalnu distribuciju s
parametrima
i
2
ako
je
2
x
2
1
e
2
1
)
x
(
f
gdje je
aritmetička sredina
standardna devijacija
= 3,14459..
.
e
=2,71828
.
Slika 2.5-13.
Normalna distribucija s parametrima
i
1
Pierre Simone Laplace (1749. - 1827.) francuski matematičar
2
Abraham De Moivre (1667. - 1754.) engleski matematičar francuskog podrijetla
-3
-2
-1
1
2
3
Osnovne statističke metode – Teoretske distribucije
105
Ako su vrijednosti izražene u standardiziranom obliku (v. poglavlje
2.7, str. 114-123.)
x
z
,
onda se formula normalne distribucije svodi na oblike
2
2
z
e
2
1
)
z
(
f
s parametrima
= 0
i
=1
(slika 2.5-14). U statističkim analizama
često je važnije utvrditi vjerojatnost postizanja boljeg ili lošijeg
rezultata od neke vrijednosti, što se izračunava tzv. integralom
vjerojatnosti
dz
e
2
1
)
z
(
z
2
z
2
Dobivena funkcija
(z)
je normalna kumulativna distribucija (slika
2.5-14), vrijednosti koje odgovaraju vjerojatnosti postizanja rezultata
koji je jednak ili manji od rezultata
z
, što odgovara površini ispod
normalne distribucije od
-
do
z
. Slika 2.5-14 ilustrira odnos funkcije
f(z)
i
(z)
. Vrijednosti funkcije
(z)
za odgovarajuće
z
vrijednosti
prikazane su u tablici
A
str. 316.
Moguće je uočiti da je normalna distribucija zvonastog oblika,
unimodalna i zrcalno simetrična u odnosu na aritmetičku sredinu.
Aritmetička sredina, modus i medijan su jednaki. Normalna
distribucija je definirana aritmetičkom sredinom i standardnom
devijacijom. Proteže se u intervalu od -
do +
, a vjerojatnost da se
dogodi vrijednost u intervalu (slika 2.5-15):
od
-1
do
+1
je 68,27 %
od
-2
do
+2
je 95,45 %
od
-3
do
+3
je 99,73 %,
odnosno
od
-1,96
do
+ 1,96
je 95 %
od
-2,58
do
+ 2,58
je 99 %.

Osnovne statističke metode – Teoretske distribucije
107
t-distribucija
nazivaju
Studentov t-test
i
Studentova t-distribucija
. Posjećivao
je i dopisivao se s mnogim statističarima, među kojima i s R. Fisherom i K.
Pearsonom.
Prema, Kolesarić i Petz, (1999) i O'Connor i Robertson:
http://www–groups.dcs.st– and.ac.uk/%7Ehistory/Mathematicians/Gosset.html
William Gosset
(1876. – 1937.) studirao je
kemiju i matematiku na New College u Oxfordu.
Po završetku studija 1899. godine dobiva posao
kemičara u poznatoj pivarskoj tvrtci Guinness u
Dublinu. U nastojanju da unaprijedi proizvodnju,
razvijao je statističke metode. Osobito je značajan
njegov doprinos u
oblikovanju t-testa
i
t-
distribucije
.
Objavljivao
je
članke
pod
pseudonimom
Student
pa se često
t-test
i
Znanstveni članak
The Probable Error of Mean
objavljen u
časopisu
Biometrika
1908. godine.
2.5.3.2. Studentova t - distribucija
William Gosset definirao
je
t-distribuciju
i objavio
je u časopisu
Biometri-
ka
, 1908. godine pod
pseudonimom
Student
.
Slučajna varijabla
t
ima
Studentovu t-distribuciju
s parametrom
df
ako je
2
1
2
1
2
2
1
)
(
df
df
t
df
df
df
t
f
gdje je
df
broj stupnjeva slobode
(
df=1,2…
)
3
gama funkcija
4
=3.14459...
Studentova
t-distribucija
ima oblik sličan normalnoj
distribuciji. Za
df
,
t-
distribucija
se približava
standardiziranoj normalnoj
distribuciji s parametrima
=0
i
=1
. Sa smanjivanj-
em broja stupnjeva slobode
t-distribucija
poprima sve
širi oblik (slika 2.5-16).
3
Broj stupnjeva slobode (
engl. degrees of freedom
) definira se kao broj neovisnih opažanja (entiteta)
n
umanjen za broj
k
parametara potrebnih da bi se odredio dani pokazatelj. Dakle, broj stupnjeva slobode
df
= n – k
(prema Šošić i Sedar, 2002: 249).
4
Više o gama funkciji moguće je pročitati u knjizi I.Pavić (1988). Statistička teorija i primjena. (str.113-
116). Zagreb: Tehnička knjiga.
Osnovne statističke metode – Teoretske distribucije
108
Vrijednosti za
t-distribuciju
za određeni broj stupnjeva slobode (
df
)
dane su u tablici
B
str. 317.
Slika 2.5-16.
t-distribucija za df = 3, df =5, df = 10, df =100
3,18
95%
2,57
95%
2,23
95%
1,97
95%

Osnovne statističke metode – Teoretske distribucije
110
2.5.3.4.
2
- distribucija
Za neku slučajnu kontinuiranu varijablu
x
kaže se da ima
2
-
distribuciju
s parametrom
df
ako je
2
/
1
2
/
2
/
2
/
2
1
)
(
x
df
df
e
x
df
x
f
,
gdje je
df
broj stupnjeva slobode (
df = 1,2,…
)
gama funkcija
e
=2,71828.
Vidljivo je da funkcija
f(x)
zavisi samo od parametra
df
. Za male
vrijednosti
df
(broja stupnjeva slobode)
2
-distribucija
ima jako
izraženu pozitivnu asimetriju, a s povećanjem broja stupnjeva slobode
teži simetričnosti (slika 2.5-18). Zbog složenosti izračunavanja,
vrijednosti
2
-distribucije
za odgovarajući broj stupnjeva slobode (
df
)
dane su u tablici
D
str. 322.
Slika 2.5-18.
2
- distribucija za broj stupnjeva slobode df =3, df=5, df=10, df=15
df=3
df=5
df=10
df=15
Osnovne statističke metode – K-S test normaliteta distribucije
111
2.6
K-S test
normaliteta
distribucije
S obzirom na to da primjena parametrijskih statističkih metoda
zahtijeva kvantitativne normalno distribuirane varijable, obično se u
svakom realnom istraživanju utvrđuje da li empirijske distribucije
statistički značajno odstupaju od normalne distribucije. Naime,
emipirijske distribucije uvijek u nekoj mjeri odstupaju od teoretske
normalne distribucije zbog toga što se u istraživanjima koriste uzorci
ispitanika koji nikada potpuno ne odražavaju stanje populacije. Stoga
se, ovisno o reprezentativnosti uzorka ispitanika, može dogoditi da
inače normalno distribuirane varijable u populaciji, manje ili više
odstupaju od teoretske normalne distribucije. Takva odstupanja su
proizvod slučajnog variranja entiteta u uzorcima i ne smatraju se
statistički značajnima. S druge strane, ako su odstupanja neke
empirijske distribucije toliko velika da prelaze razinu slučajnih
odstupanja, tada se smatraju statistički značajnima. Takva odstupanja
nisu posljedica slučajnog variranja entiteta u uzorku, već se radi o
varijablama kojih je stvarna distribucija različita od normalne
distribucije.

Osnovne statističke metode – K-S test normaliteta distribucije
113
izračunati odstupanja između empirijske i teoretske relativne
kumulativne frekvencije (stupac-D u tablici 2.6-1)
odrediti najveće odstupanje empirijske i teoretske relativne
kumulativne (
maxD
) frekvencije i usporediti ga s tabličnom
vrijednošću
KS-testa
, određenom za odgovarajući broj entiteta
(tablica
E
, str. 323). Kritična (tablična) vrijednost
KS-testa
uz
pogrešku od 0,05 za 60 entiteta iznosi 0,172. Ako je najveće
odstupanje (slika 2.6-1) između empirijske i teoretske relativne
kumulativne frekvencije manje od kritične vrijednosti KS-testa
(
maxD<KS-test)
, zaključujemo da empirijska distribucija ne odstupa
statistički značajno od normalne distribucije uz određenu pogrešku.
U ovom primjeru vrijednost
maxD
(0,0852) je manja od kritične
vrijednosti
KS-testa
(0,172), pa zaključujemo da empirijska
distribucija ne odstupa statistički značajno od normalne distribucije
uz pogrešku od 5%.
Slika 2.6-1.
Poligon empirijskih i teoretskih relativnih kumulativnih frekvencija
Za broj entiteta veći od
100
moguće je kritične vrijednosti
KS-testa
uz
pogrešku od 0,05 i 0,01 računati formulama (prema Pauše, 1993, str.
263):
n
36
,
1
test
KS
05
,
0
n
63
,
1
test
KS
01
,
0
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
1
2
3
4
5
rcf
trcf
maxD
Osnovne statističke metode – Standardizacija podataka (z-vrijednosti)
114
2.7
Standardizacija
podataka
(
z - vrijednost
)
Za prikupljanje podataka na nekom uzorku entiteta koriste se različiti
mjerni instrumenti, pa su i rezultati izraženi u različitim mjernim
jedinicama. Stoga je usporedba vrijednosti entiteta u različitim
varijablama znatno otežana. Ovaj problem se rješava postupkom
transformacije originalnih vrijednosti neke varijable u tzv.
standardizirane
ili
z-vrijednosti
.
Postupak standardizacije provodi se pomoću formule
j
j
ij
ij
x
x
z
,
gdje je
z
ij
standardizirani rezultat entiteta
i
u varijabli
j
x
ij
originalna vrijednost ispitanika
i
u varijabli
j
j
x
aritmetička sredina varijable
j
j
standardna devijacija varijable
j
.

Osnovne statističke metode – Standardizacija podataka (z-vrijednosti)
116
Tablica 2.7-2.
Aritmetičke sredine i standardne devijacije
SD
T100m
BK
x
370,4
13,36
545,6
45,66
0,73
34,21
Drugi korak
: Transformirati originalne podatake u
z-vrijednosti
na
temelju izračunatih aritmetičkih sredina i standardnih devijacija.
Primjerice, standardizirani rezultat učenika AB u disciplini
skok udalj
(SD) izračuna se prema formuli
25
,
0
66
,
45
4
,
11
66
,
45
4
,
370
359
z
SD
,
AB
Na isti način transformiraju se rezultati ostalih učenika u sve tri
discipline. Rezultati su prikazani u tablici 2.7-3.
Tablica 2.7-3.
Standardizirani rezultati 10 učenika u tri atletske discipline
SD
T100M
BK
AB
-0,25
0,33
0,45
DF
-1,08
0,74
0,13
JG
-0,53
0,46
-0,22
KL
-0,84
0,87
-1,63
DD
1,74
-1,58
-0,81
ED
-1,24
1,01
0,16
TB
0,87
-1,17
1,27
ZN
1,20
-1,44
1,65
RG
-0,03
0,19
0,04
EN
0,17
0,60
-1,04
Treći korak
: Prije kondenzacije rezultata (zbrojem ili prosječnom
vrijednošću), potrebno je varijable koje su obrnuto skalirane
pomnožiti s
-1
, odnosno promijeniti im predznak. Naime, varijabla
trčanje na 100 metara
(T100m) je obrnuto skalirana, što znači da veća
numerička vrijednost predstavlja lošiji rezultat. Stoga tu varijablu
treba pomnožiti s
-1
. Nakon ovog postupka dobiju se rezultati
prikazani u tablici 2.7-4.
Osnovne statističke metode – Standardizacija podataka (z-vrijednosti)
117
Tablica 2.7-4.
Standardizirani rezultati 10 učenika u tri atletske discipline nakon što je
varijabla T100M pomnožena sa -1
SD
T100M
BK
AB
-0,25
-0,33
0,45
DF
-1,08
-0,74
0,13
JG
-0,53
-0,46
-0,22
KL
-0,84
-0,87
-1,63
DD
1,74
1,58
-0,81
ED
-1,24
-1,01
0,16
TB
0,87
1,17
1,27
ZN
1,20
1,44
1,65
RG
-0,03
-0,19
0,04
EN
0,17
-0,60
-1,04
Četvrti korak
: Kondenzirati standardizirane vrijednosti aritmetičkom
sredinom, odnosno izračunavanjem prosječne
z-vrijednosti
za svakog
učenika u navedenim disciplinama. Primjerice, prosječna
z-vrijednost
učenika AB izračuna se formulom
0,04
3
0,45
0,33)
(
0,25
3
z
z
z
z
BK
AB,
T100
AB,
AB,SD
AB
Na isti način izračunaju se prosječni rezultati ostalih učenika u sve tri
discipline. Rezultati su prikazani u tablici 2.7-5.
Tablica 2.7-5.
Prosječni standardizirani rezultati 10 učenika u tri atletske discipline
z
AB
-0,04
DF
-0,56
JG
-0,41
KL
-1,11
DD
0,84
ED
-0,70
TB
1,10
ZN
1,43
RG
-0,06
EN
-0,49
Peti korak
: Silazno (od većega k manjem) poredati učenike po
izračunatoj prosječnoj
z-vrijednosti
. Konačan redoslijed učenika
prikazan je u tablici 2.7-6.

Osnovne statističke metode – Standardizacija podataka (z-vrijednosti)
119
Slika 2.7-1.
Površina ispod normalne distribucije odgovara vjerojatnosti da neki rezultat bude
bolji ili lošiji od zadane z - vrijednosti
Dakle, za vrijednost
z=1,25
odgovara površina ispod normalne
distribucije od
p=0,1057
, ili izraženo u postotku
10,57%,
što izražava
vjerojatnost da se postigne bolji rezultat od ispitanika XY.
z = 1,25
p = 0,1057
10,57 %
Vjerojatnost postizanja lošijeg rezultata jednaka je
1-0,1057=0,8943
,
odnosno
89,43 %
.
Na temelju procijenjene vjerojatnosti može se izračunati broj
ispitanika s boljim, odnosno lošijim rezultatom. S obzirom na to da je
n
d
p
, odnosno
100
n
d
%
,
gdje je
p
proporcija (
p= 0,1057
)
d
dio cjeline (broj učenika s boljim rezultatom od
z = 1,25
)
n
cjelina (ukupan broj učenika
n = 257
),
onda je
27
16
,
27
257
1057
,
0
n
p
d
učenika s boljim,
odnosno,
257 - 27 = 230
učenika s lošijim rezultatom.
z=1,25
p = 0,1057
10,57 %
p = 0,8943
89,44 %
Osnovne statističke metode – Standardizacija podataka (z-vrijednosti)
120
Praktična korist od standardizacije rezultata ogleda se i u mogućnosti
grafičkog prikazivanja rezultata entiteta u većem broju varijabli koje
opisuju njegov antropološki profil (slika 2.7-2).
Legenda: SDM - skok udalj s mjesta, IP - iskret palicom, NEB – neritmično bubnjanje, SKL – sklekovi, T12min –
trčanje 12 minuta, T20m - trčanje 20 m, KUS – koraci u stranu, BP – brzina provlaka, TR – taping rukom.
Slika 2.7-2.
Grafički prikaz profila treniranosti sportaša
To omogućava, primjerice, uočavanje stanja činilaca odgovornih za
uspješnost u određenoj sportskoj aktivnosti, odnosno određivanje
profila stanja treniranosti sportaša (slika 2.7-2). Na temelju slike 2.7-2
može se uočiti u kojim je testovima ispitanik postigao dobre, a u
kojima loše rezultate, odnosno na što bi trebalo obratiti pozornost pri
programiranju treninga u sljedećem razdoblju.
2.7.1. Standardizacija varijabli matričnom algebrom
Neka je
X
matrica podataka dobivena opisivanjem nekog skupa od
n
entiteta skupom od
m
varijabli.
X
= (x
ij
)
,
gdje je
i = 1,…,n
, a
j = 1,…,m
. Matrica standardiziranih podataka
Z
dobije se operacijom
Z
=
X
c
V
-1
SKL
SDM
IP NEB
T12m
T20m KUS
BP
TR

Osnovne statističke metode – Standardizacija podataka (z-vrijednosti)
122
Matrica kovarijanci
C
varijabli iz
X
izračuna se operacijom
C
=
X
c
T
X
c
n
-1
,
gdje je
X
c
matrica centriranih podataka početnih vrijednosti matrice
X
.
Ekstrakcijom dijagonale matrice kovarijanci
C
dobije se dijagonalna
matrica varijanci
V
2
V
2
=
diag
C
,
a operacijom
V
=
(diag
C
)
1/
2
dijagonalna matrica standardnih devijacija
V
.
SD
T100m
BK
SD
2337,78
-36,11
531,53
T100m
-36,11
0,58
-11,41
BK
531,53
-11,41
1140,28
=
C
SD
-10,56
-48,56
-23,56
-37,56
80,44
-55,56
40,44
55,44
T100m
0,29
0,59
0,39
0,69
-1,11
0,79
-0,81
-1,01
BK
11,44
0,44
-11,56
-59,56
-31,56
1,44
39,44
52,44
X
c
T
SD
T100m
BK
-10,56
0,29
11,44
-48,56
0,59
0,44
-23,56
0,39
-11,56
-37,56
0,69
-59,56
80,44
-1,11
-31,56
-55,56
0,79
1,44
40,44
-0,81
39,44
55,44
-1,01
52,44
-0,56
0,19
-2,56
X
c
9
-1
n
-1
SD
T100m
BK
SD
2337,78
0
0
T100m
0
0,58
0
BK
0
0
1140,28
V
2
=diag
C
SD
T100m
BK
SD
48,35
0
0
T100m
0
0,76
0
BK
0
0
33,77
V
=(diag
C
)
1/2
SD
T100m
BK
359
13,6
561
321
13,9
550
346
13,7
538
332
14
490
450
12,2
518
314
14,1
551
410
12,5
589
425
12,3
602
369
13,5
547
X
SDM
T100m
BK
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
369,56
13,31
549,56
1 m
T
SD
T100m
BK
-10,56
0,29
11,44
-48,56
0,59
0,44
-23,56
0,39
-11,56
-37,56
0,69
-59,56
80,44
-1,11
-31,56
-55,56
0,79
1,44
40,44
-0,81
39,44
55,44
-1,01
52,44
-0,56
0,19
-2,56
X
c
-
=
Osnovne statističke metode – Standardizacija podataka (z-vrijednosti)
123
Standardizirani podaci dobiju se operacijom
SD
T100m
BK
-10,56
0,29
11,44
-48,56
0,59
0,44
-23,56
0,39
-11,56
-37,56
0,69
-59,56
80,44
-1,11
-31,56
-55,56
0,79
1,44
40,44
-0,81
39,44
55,44
-1,01
52,44
-0,56
0,19
-2,56
X
c
SD
T100m
BK
SD
0,0207
0
0
T100m
0
1,3146
0
BK
0
0
0,0296
V
-1
SD
T100m
BK
-0,22
0,38
0,34
-1,00
0,77
0,01
-0,49
0,51
-0,34
-0,78
0,91
-1,76
1,66
-1,46
-0,93
-1,15
1,04
0,04
0,84
-1,07
1,17
1,15
-1,33
1,55
-0,01
0,25
-0,08
Z
=

Osnovne statističke metode – Procjena aritmetičke sredine populacije
125
dostupnim entitetima (prigodni uzorak), dok kod slučajnih uzoraka svi
entiteti (iz populacije izbora uzorka) imaju jednaku vjerojatnost
izbora. S obzirom da se uzorci biraju radi što bolje reprezentativnosti
populacije iz koje su izabrani (jer se zaključci dobiveni na uzorku uz
određenu pogrešku generaliziraju na populaciju), lako je uočiti da će
pogreška procjene biti manja što je broj entiteta uzorka bliži populaciji
i u kome svi entiteti imaju jednaku vjerojatnost izbora.
Općenito, neki parametar populacije
(npr. aritmetičke sredine,
varijance...) procjenjuje se na temelju istovrsnog parametra
izračunatog iz nekog slučajnog uzorka
’
. S obzirom na to da je iz
neke populacije moguće izabrati puno slučajnih uzoraka, jasno je da
se time dobiva i veliki broj prametara
’
. Izračunati parametri
’
dobiveni na velikom broju uzoraka ne moraju biti jednaki parametru
populacije
jer su izračunati na dijelu (podskupu) populacije.
Parametri izračunati na uzorcima
’
ne moraju biti međusobno jednaki
jer su izračunati na podacima koji se mogu međusobno razlikovati od
uzorka do uzorka. Stoga se postavlja pitanje: kako je moguće
procijeniti parametar populacije
ako od svih mogućih uzoraka
odabranih iz neke populacije odaberemo jedan?
Ako iz neke populacije od
N
entiteta odaberemo sve moguće uzorke
veličine
n
(
n<N
) te za svaki uzorak izračunamo parametar
’
, dobit
ćemo neku distribuciju po kojoj će parametri
’
varirati. S obzirom na
to da su uzorci birani slučajno, i vrijednosti parametra
’
slučajno će
varirati, odnosno činit će slučajnu varijablu koja će imati neku
distribuciju vjerojatnosti. Distribucija vjerojatnosti prema kojoj varira
slučajna varijabla
’
naziva se
sampling distribucija
. S obzirom da
sampling distribucija
parametra
’
odgovara nekoj od teoretskih
distribucija vjerojatnosti (
Gaussovoj, t-distribuciji, F-distribuciji...
),
moguće je s određenom vjerojatnošću odrediti interval u kome se
nalazi parametar populacije
.
Najjednostavniji slučaj statističkog zaključivanja (ali izuzetno bitan za
razumijevanje logike statističkog zaključivanja) jest procjena
aritmetičke sredine populacije
na temelju aritmetičke sredine nekog
slučajno odabranog uzorka
x.
Radi lakšeg predočavanja i razumijevanja navedenog problema,
pretpostavimo da iz jedne velike i konačne populacije (npr.
N=10000
)
Osnovne statističke metode – Procjena aritmetičke sredine populacije
126
izračunamo aritmetičku sredinu (
) i standardnu devijaciju (
) neke
varijable
X
koja je normalno distribuirana (slika 2.8-1).
Slika 2.8-1.
Normalna distribucija pojedinačnih rezultata entiteta neke populacije s
parametrima
i
Ako iz te populacije metodom slučajnog odabira (npr. generatorom
slučajnih brojeva, koji je implementiran u gotovo sve novije
programske proizvode
STATISTICA
,
SPSS
i sl.), odaberemo jedan
uzorak veličine 5 entiteta (
n=5
), postavlja se pitanje: hoće li
aritmetička sredina tog (prvog) uzorka (
1
x
) biti jednaka aritmetičkoj
sredini populacije (
)?
S obzirom na to da su entiteti slučajno odabrani u ovaj uzorak može se
pretpostaviti da će aritmetička sredina tog uzorka biti slična
aritmetičkoj sredini populacije, a da joj ne mora biti jednaka.
Ako se odabere novi uzorak, postavlja se isto pitanje: hoće li
aritmetička sredina tog uzorka (
2
x
) biti jednaka aritmetičkoj sredini
prvog uzorka (
1
x
), odnosno aritmetičkoj sredini populacije (
)?
Odgovor će biti sličan prethodnome, dakle, vjerojatno će biti slična,
ali ne mora biti ista. Ako se nastavi sa slučajnim izborom uzoraka
1
iste
veličine (npr.
10 000
puta) i računanjem njihovih aritmetičkih sredina
1
Entiteti se u slučajni uzorak biraju uz povrat, odnosno nakon izbora jednog entiteta zabilježimo njegov
rezultat te ga vratimo u populaciju.
-3
-2
-1
1
2
3

Osnovne statističke metode – Procjena aritmetičke sredine populacije
128
slučajnog odstupanja aritmetičkih sredina uzoraka od aritmetičke
sredine populacija ili pak nema nikakvog utjecaja?
Nije teško zaključiti da povećanje veličine uzorka smanjuje
vjerojatnost slučajnog odstupanja aritmetičkih sredina uzoraka oko
aritmetičke sredine populacije. Dakle, distribucija aritmetičkih sredina
slučajno odabranih uzoraka veličine 10 entiteta u odnosu na
distribuciju aritmetičkih sredina slučajno odabranih uzoraka veličine 5
entiteta bit će uža, odnosno, imat će manju standardnu devijaciju
(slika 2.8-2).
Slika 2.8-2.
Distribucija aritmetičkih sredina slučajno odabranih uzoraka veličine
n
1
=5, n
2
=10, n
3
=20
Valja zaključiti da će standardna devijacija varijable aritmetičkih
sredina slučajno odabranih uzoraka biti to manja što su uzorci veći.
Osim toga, na standardnu devijaciju aritmetičkih sredina slučajno
odabranih uzoraka utječe i varijabilnost istraživane pojave (varijable)
u populaciji. Logično je da će standardna devijacija aritmetičkih
sredina slučajno odabranih uzoraka jednake veličine biti manja kod
manje varijabilnih populacija nego kod populacija kod kojih
istraživana pojava više varira. Međutim, kako na varijabilnost neke
pojave u određenoj populaciji ne možemo utjecati, smanjenje
standardne devijacije aritmetičkih sredina slučajno odabranih uzoraka
može se postići jedino povećanjem uzorka. Standardna devijacija
aritmetičkih sredina slučajno odabranih uzoraka naziva se
standardna
pogreška aritmetičke sredine
(
x
) i ključna je za procjenu aritmetičke
sredine populacije.
n=5
n=10
n=20
Osnovne statističke metode – Procjena aritmetičke sredine populacije
129
Ako je poznata standardna devijacija aritmetičkih sredina slučajno
odabranih uzoraka, odnosno
standardna pogreška aritmetičke sredine
,
onda je moguća i procjena aritmetičke sredine populacije. Naime, ako
su aritmetičke sredine slučajno odabranih uzoraka
normalno
distribuirne, moguće je konstatirati da se u intervalu:
x
3
od aritmetičke sredine populacije nalazi približno 99% svih
aritmetičkih sredina uzoraka,
x
2
od aritmetičke sredine populacije nalazi približno 95% svih
aritmetičkih sredina uzoraka (v. poglavlje 2.5.3.1, str. 104-106).
Prema tome, aritmetička sredina populacije nalazit će se u intervalu
x
3
od bilo koje aritmetičke sredine uzorka s približnom
vjerojatnošću od 99%, odnosno u intervalu
x
2
s približnom
vjerojatnošću od 95%.
Ako odstupanja aritmetičkih sredina uzoraka (
x
i
) u odnosu na
aritmetičku sredinu populacije (
) podijelimo sa standardnom
pogreškom aritmetičke sredine (
x
)
x
i
i
x
z
(gdje je
i=1,...n
, a
n
- ukupan broj slučajno odabranih uzoraka),
dobijemo standardizirana odstupanja aritmetičkih sredina uzoraka u
odnosu na aritmetičku sredinu populacije. S obzirom na to da su pri
statističkom zaključivanju uobičajene pogreške
2
od
p=0,05
(
5%
) i
p=0,01
(
1%
), moguće je uvidjeti da će
z
biti između
1,96
u 95%,
odnosno između
2,58
u 99% slučajeva.
96
,
1
96
,
1
x
x
; za
p=0,05
58
,
2
58
,
2
x
x
; za
p=0,01
Ako svaki član gornjeg izraza pomnožimo sa standardnom pogreškom
aritmetičke sredine (
x
), dobijemo
2
Za pogrešku s kojom se donosi određeni statistički zaključak još se upotrebljava i naziv
razina
značajnosti
ili
razina signifikantnosti
.

Osnovne statističke metode – Procjena aritmetičke sredine populacije
131
n
s
s
x
Zbog takvog načina procjenjivanja standardne pogreške aritmetičke
sredine,
sampling distribucija
za izraz
x
i
s
x
neće biti
normalna
, već
Studentova t-distribucija
(v. poglavlje
2.5.3.2, str. 107-108)
Studentova t-distribucija
teži
normalnoj
kada
broj stupnjeva slobode teži beskonačnom (
df
) pa su i
t-vrijednosti
za velike uzorke (
n>30
) vrlo slične vrijednostma
normalne
distribucije (
1,96
za
95%
, odnosno
2,58
za
99%
pouzdanosti
procjene). Stoga kod malih uzoraka (
n<30
) izraz
x
i
i
s
x
t
(umjesto oznake
z
koristimo oznaku
t
) ima oblik
Studentove t-
distribucije
uz broj stupnjeva slobode
df=n-1
(slika 2.8-3).
Slika 2.8-3.
Usporedba normalne i t-distribucije za df=4
Interval u kojem se s određenom vjerojatnošću nalazi aritmetička
sredina populacije moguće je procijeniti formulom
x
p
x
p
s
t
x
s
t
x
,
Osnovne statističke metode – Procjena aritmetičke sredine populacije
132
gdje je:
x
aritmetička sredina uzorka,
x
s
procjena standardne pogreške aritmetičke sredine,
t
p
vrijednost koja se za pogrešku
p
(u statističkom zaključivanju
najčešće se koristi pogreške
0,01
ili
1%
, i
0,05
ili
5%
) i određeni
broj stupnjeva slobode (
df=n-1
) dobije se na temelju
Studentove t-
distribucije
.
U tablici
B
str. 317, dane su
t-vrijednosti
za odgovarajući broj
stupnjeva slobode (
df=n-1)
i pogrešku (
p
).
Primjer:
Na slučajno odabranom uzorku veličine
100
entiteta
izračunata je aritmetička sredina (
x = 180
cm
) i standardna devijacija
(
s = 10 cm
). Potrebno je procijeniti interval u kojemu se s
vjerojatnošću od 0,95 nalazi aritmetička sredina populacije.
Prvo je potrebno procijeniti standardnu pogrešku aritmetičke sredine
cm
1
100
10
n
s
s
x
Iz tablice
B
str. 317 odredi se
t-vrijednost
za
df=n-1=100-1=99
i
pogrešku od
0,05
.
98
,
1
t
05
,
0
99
Uvrštavanjem dobivenih vrijednosti u formulu za procjenu aritmetičke
sredine populacije dobije se
1
98
,
1
x
1
98
,
1
x
,
odnosno
98
,
181
02
,
178
.
Dakle, moguće je zaključiti da se aritmetička sredina populacije nalazi
u intervalu od 178,02 do 181,98 sa sigurnošću od
95%
, odnosno uz
pogrešku od
5%
.
Formula za standardnu pogrešku aritmetičke sredine
n
x

Osnovne statističke metode – Procjena aritmetičke sredine populacije
134
78
,
0
07
,
7
5
,
5
50
5
,
5
s
x
Dakle, sa sigurnošću od
95%
aritmetička sredina populacije nalazi se
u intervalu
78
,
0
t
55
p
Uz pomoć tablice
B
str. 317 odredi se
t-vrijednost
za određenu
pogrešku
p
i broj stupnjeva slobode
df
. Za pogrešku
p=0,05
i broj
stupnjeva slobode
df=49
t-vrijednost
iznosi
2,01
. Prema tome, raspon
u kojem može varirati aritmetička sredina populacije iznosi
14
,
3
78
,
0
01
,
2
2
mlO
2
/kg/min
Smatramo li taj raspon prevelikim i želimo li da on ne iznosi više od
2
mlO
2
/kg/min
, potrebno je povećati uzorak ispitanika. Broj entiteta koji
će osigurati da raspon intervala procjene aritmetičke sredine ne bude
veći od
2 mlO
2
/kg/min
izračuna se postupkom
n
11
,
22
n
5
,
5
01
,
2
2
2
122
06
,
11
n
2
11
,
22
n
2
Prema tome, formulu pomoću koje procjenjujemo veličinu uzorka za
odgovarajući raspon procjene aritmetičke sredine populacije moguće
je napisati u ovom obliku
2
p
I
s
t
2
n
gdje je:
n
broj entiteta
t
p
vrijednost za određenu sigurnost procjene, odnosno pogrešku
p
,
koja se dobije se na temelju
Studentove t-distribucije
uz određeni
broj stupnjeva slobode
df=n-1
s
standardna devijacija, a
I
prihvatljivi interval procjene aritmetičke sredine populacije.
Osnovne statističke metode – t-test
135
2.9
t - test
Dio statistike koji se bavi problemima statističkog zaključivanja,
odnosno generaliziranjem zaključaka s uzorka na populaciju naziva se
inferencijalna
statistika
.
U
okviru
inferencijalne
statistike,
odgovarajućim statističkim testom,
testiraju se statističke hipoteze
o
veličini određenog statističkog parametra populacije na temelju
slučajnog uzorka. Hipoteze definira istraživač na temelju cilja
znanstvenog istraživanja. Naime, svako znanstveno istraživanje
usmjereno je na rješavanje nekog
znanstvenog problema
. Uočeni
znanstveni problem, koji se želi rješavati nekim znanstvenim
istraživanjem, valja detaljno i precizno opisati i obrazložiti. Pojedino
znanstveno istraživanje u pravilu je usmjereno na rješavanje jednog
dijela uočenog znanstvenog problema pa se za svako znanstveno
istraživanje jasno navode
ciljevi istraživanja
, a na temelju njih
precizno se definiraju
hipoteze
. Dakle, “hipoteze proizlaze iz
znanstvenog problema (dijela znanstvenog problema) koji želimo
istraživati, odnosno iz hipotetičke teorije (dijela hipotetičke teorije)
koju provjeravamo” (Mejovšek, 2003, str. 76.). Vrijednost neke
znanstvene hipoteze moguće je procjenjivati temeljem sljedećih
mjerila:
svrhovitost
– hipoteza treba biti u funkciji postizanja određenog cilja
istraživanja;
provjerljivost
– hipotezu treba postaviti tako da ju je moguće
provjeriti odgovarajućim postupcima;
plodotvornost
– hipoteza treba omogućiti donošenje plodotvornih
zaključaka u odnosu na istraživani problem;

Osnovne statističke metode – t-test
137
uzorke
) te statistička značajnost razlike aritmetičke sredine nekog
uzorka u odnosu na neku unaprijed poznatu aritmetičku sredinu.
Razlike između dviju aritmetičkih sredina moguće je utvrditi
jednostavno njihovom usporedbom, ali uočena razlika ne mora biti i
statistički značajna. Naime, pojam
statistički značajna razlika
dviju
aritmetičkih sredina nije obična razlika između njih, već je to razlika
veća od one koja se može dogoditi sasvim slučajno, kao posljedica
slučajnoga odabira entiteta u uzorak. Dakle, statistički značajna
razlika aritmetičkih sredina dvaju slučajno odabranih uzoraka
predstavlja razliku koja je posljedica stvarnih razlika između
populacija kojima uzorci pripadaju, a ne slučajnog variranja uzoraka.
Statistički značajna razlika je veća od razlike koja se može dobiti
slučajnim variranjem uzoraka.
T-test
upravo služi za utvrđivanje
statističke značajnosti razlike
aritmetičkih sredina zavisnih ili
nezavisnih uzoraka.
2.9.1. t-test za nezavisne uzorke
Za lakše razumijevanje
t-testa
pretpostavimo da iz jedne velike i
normalno
distribuirane populacije (npr.
N=10000
) slučajnim
odabirom biramo uzorke veličine 5 entiteta (
n=5
). Nakon što
odaberemo dva slučajna uzorka izračunamo, njihove aritmetičke
sredine. Postavlja se pitanje: hoće li aritmetička sredina prvog uzorka
biti jednaka aritmetičkoj sredini drugog uzorka? S obzirom da su
entiteti slučajno odabrani u oba uzorka, može se pretpostaviti da
aritmetičke sredine tih uzoraka mogu, ali i ne moraju biti jednake.
Dakle, izračunamo li razliku između tih dviju aritmetičkih sredina,
ona može, ali i ne mora biti jednaka nuli.
Ako nastavimo (npr.
10 000
puta) slučajno birati parove uzoraka iste
veličine i računati razlike aritmetičkih sredina (
R
), dobit ćemo
n
n
n
R
x
x
R
x
x
R
x
x
2
1
2
2
2
2
1
1
1
2
1
1
.
.
.
.
.
.
.
varijablu razlika aritmetičkih sredina slučajno odabranih uzoraka
veličine 5 entiteta. Postavlja se pitanje: kolika će biti aritmetička
Osnovne statističke metode – t-test
138
sredina ove varijable i kakva će joj biti distribucija? Aritmetička
sredina varijable razlika aritmetičkih sredina slučajno odabranih
uzoraka odgovarala bi
pravoj razlici
. Budući da su uzorci birani iz iste
populacije, ta razlika je jednaka
nuli
jer slučajnim odabirom entiteta u
uzorak isključujemo bilo kakvu mogućnost sistematske (namjerne)
tendencije razlikovanja aritmetičkih sredina uzoraka. Slučajnim
odabirom uzoraka osiguravamo da se aritmetičke sredine slučajno
razlikuju. To znači da će, uz jednaku vjerojatnost, neke razlike biti
pozitivnoga predznaka (aritmetička sredina prvog uzorka slučajno je
veća od aritmetičke sredine drugog uzorka), a neke negativnoga
predznaka (aritmetička sredina prvog uzorka slučajno je manja od
aritmetičke sredine drugog uzorka). Prema tome, tendencija grupiranja
razlika aritmetičkih sredina uzoraka bit će oko
nule
prema
normalnoj
distribuciji (slika 2.9-1).
Slika 2.9-1.
Distribucija razlika aritmetičkih sredina slučajno odabranih uzoraka
Ako se nastavi s izborom slučajnih uzoraka, ali ne više veličine 5
entiteta, već 10 i računanjem razlika između njihovih aritmetičkih
sredina, dobije se nova varijabla.
n
n
n
R
x
x
R
x
x
R
x
x
2
1
2
2
2
2
1
1
1
2
1
1
.
.
.
.
.
.
.
0

Osnovne statističke metode – t-test
140
2
1
3
x
x
s
nalazi približno 99% svih razlika između aritmetičkih
sredina slučajno odabranih uzoraka, a u intervalu
2
1
2
x
x
s
nalazi se približno 95% (v. poglavlje 2.5.3.1, str. 104-106).
Iz toga slijedi da će svaka razlika između dviju aritmetičkih sredina
slučajno odabranih uzoraka biti statistički značajna ako je, primjerice,
3
puta veća od
standardne pogreške razlika aritmetičkih sredina
(
2
1
x
x
s
), zbog toga što je vjerojatnost slučajnog pojavljivanja tako
velike razlike između aritmetičkih sredina vrlo mala, manja od
1%
.
Prema tome, da li će neka razlika između dviju aritmetičkih sredina
biti statistički značajna, ovisi o tome koliko je puta veća od
standardne pogreške razlika aritmetičkih sredina
(
2
1
x
x
s
).
Koliko je puta razlika aritmetičkih sredina dvaju slučajno odabranih
uzoraka veća od standardne pogreške razlika aritmetičkih sredina
izračuna se na sljedeći način
2
1
2
1
x
x
s
x
x
t
,
gdje je
t
vrijednost koja pokazuje koliko je puta razlika aritmetičkih sredina
veća od standardne pogreške razlika aritmetičkih sredina
1
x
aritmetička sredina prvog uzorka
2
x
aritmetička sredina drugog uzorka
2
1
x
x
s
standardna pogreška razlika aritmetičkih sredina.
Standardnu pogrešku razlika aritmetičkh sredina možemo izračunati
formulom (matematički dokaz moguće je pronaći u knjizi I. Pavić:
Statistička teorija i primjena, str. 244-245):
2
1
2
1
2
1
2
2
2
2
1
1
)
(
)
(
2
1
n
n
n
n
2
n
n
s
1
n
s
1
n
s
x
x
,
gdje je
s
1
2
varijanca prvog uzorka
s
2
2
varijanca drugog uzorka
n
1
broj entiteta prvog uzorka
n
2
broj entiteta drugog uzorka.
Osnovne statističke metode – t-test
141
S obzirom da je varijanca populacije uglavnom nepoznata, standardna
pogreška razlika aritmetičkih sredina procjenjuje se na temelju
procjene varijance populacije pomoću varijance uzorka pa se varijanca
računa sa
n-1
u nazivniku umjesto
n
.
Izračunata
t-vrijednost
ne raspodjeljuje se prema
normalnoj
distribuciji, već prema
t-distribuciji
. Stoga je potrebno, na temelju
t-
distribucije
, za određenu sigurnost procjene, odnosno pogrešku
p
(u
statističkom zaključivanju najčešće se koriste pogreške
p=0,01
ili
1%
,
i
p=0,05
ili
5%
), i određeni broj stupnjeva slobode
df = (n
1
-1)+(n
2
-1)
,
utvrditi
kritičnu t-vrijednost
.
Kritične t-vrijednosti
za odgovarajući broj stupnjeva slobode (
df
) i
odgovarajuću pogrešku
p
prikazane su u tablici
B
str. 315. S obzirom
na to da
Studentova t-distribucija
teži k
normalnoj
(v. poglavlje
2.5.3.2, str. 107-108) kada broj stupnjeva slobode teži beskonačnom
(
df
), onda su i
t-vrijednosti
za velike uzorke (
n>100
) vrlo slične
vrijednostima normalne distribucije (
1,96
za
95%
, odnosno
2,58
za
99%
sigurnosti procjene).
Ako je
t-vrijednost
veća od
kritične t-vrijednosti
, moguće je zaključiti,
uz određenu pogrešku
p
, da je razlika između aritmetičkih sredina
analiziranih uzoraka statistički značajna, odnosno da uzorci ne
pripadaju istoj populaciji jer je vjerojatnost da se tako velika razlika
dobije slučajno manja od
p
(najčešće
p=0,01
ili
1%
, odnosno
p=0,05
ili
5 %
). Dakle, odbacujemo
nultu
i prihvaćamo
alternativnu
hipotezu
t
>
df
t
p
H
1
:
x
1
x
2
- Razlika između aritmetičkih sredina
analiziranih uzoraka statistički je značajna
uz pogrešku
p
.
Međutim, ako je
t-vrijednost
manja od
kritične t-vrijednosti
, nije
moguće tvrditi da je razlika između aritmetičkih sredina analiziranih
uzoraka statistički značajna, odnosno da uzorci ne pripadaju istoj
populaciji jer se takva razlika može dobiti slučajno u više od
1%
ili
5%
slučajeva. Dakle, prihvaćamo nultu hipotezu
t
<
df
t
p
H
0
:
x
1
=
x
2
- Uz pogrešku
p
ne možemo tvrditi da je
razlika između aritmetičkih sredina
analiziranih uzoraka statistički značajna.

Osnovne statističke metode – t-test
143
2
2
2
1
2
1
2
1
n
s
n
s
s
x
x
te se izračuna
t-vrijednost
2
1
2
1
x
x
s
x
x
t
Kritična
t-vrijednost
određuje se prema formuli
2
2
2
2
1
2
2
1
2
1
x
x
x
x
p
s
s
t
s
t
s
t
,
gdje je
t
p
kritična
t-vrijednost
za pogrešku
p
2
1
x
s
standardna pogreška aritmetičke sredine prvog uzorka
2
2
x
s
standardna pogreška aritmetičke sredine drugog uzorka
t
1
tablična
t-vrijednost
uz broj stupnjeva slobode vezana za prvi
uzorak (
df=n
1
-1
) i pogrešku
p
t
2
tablična
t-vrijednost
uz broj stupnjeva slobode vezana za drugi
uzorak (
df=n
2
-1
) i pogrešku
p
.
Ako je izračunata apsolutna
t-vrijednost
veća od na taj način utvrđene
kritične
t-vrijednosti
, zaključujemo da je razlika između aritmetičkih
sredina statistički značajna uz pogrešku
p
.
Primjer:
Slučajnim odabirom formirani su uzorci od 100 košarkaša i
100 odbojkaša. Osnovni statistički parametri ovih uzoraka u varijabli
skok uvis s mjesta
iznose:
cm
x
k
62
;
cm
s
k
10
cm
x
o
67
;
cm
s
o
12
Potrebno je utvrditi da li se košarkaši i odbojkaši statistički značajno
razlikuju u varijabli
skok u vis s mjesta
uz pogrešku od 0,05.
Statističku značajnost razlike aritmetičkih sredina slučajno odabranih
uzoraka košarkaša i odbojkaša u varijabli
skok uvis s mjesta
moguće je
Osnovne statističke metode – t-test
144
utvrditi uz pomoć
t-testa za nezavisne uzorke
. Prije testiranja
uobičajeno je postaviti hipoteze:
H
0
(nulta hipoteza)
– nema statistički značajne razlike između
aritmetičkih sredina slučajno odabranih uzoraka košarkaša i
odbojkaša, odnosno za uočenu razliku ne može se s pogreškom
p=0,05
tvrditi da je statistički značajna. Formalno se ta hipoteza
može napisati kao:
o
k
x
x
H
:
0
.
H
1
(alternativna hipoteza)
– postoji statistički značajna razlika
između aritmetičkih sredina slučajno odabranih uzoraka košarkaša i
odbojkaša, odnosno uočena razlika može se smatrati statistički
značajnom uz pogrešku
p=0,05.
Formalno se ta hipoteza može
napisati kao:
o
k
x
x
H
:
1
.
Zavisno od rezultata
t-testa
, bit će prihvaćena jedna od navedenih
hipoteza.
Standardna pogreška razlika aritmetičkih sredina iznosi
1,56
2,44
1000
200
198
12
99
10
99
s
n
n
n
n
2
n
n
s
1
n
s
1
n
s
2
2
x
x
o
k
o
k
o
k
o
o
k
k
x
x
o
k
o
k
2
2
)
(
)
(
S obzirom na to da se radi o velikim uzorcima (
n>30
), standardnu
pogrešku razlika aritmetičkih sredina moguće je procijeniti i
pojednostavljenom formulom
1,56
2,44
1,44
1
100
12
100
10
n
s
n
s
s
2
2
o
k
x
x
o
k
2
2
1
2
.
t-vrijednost
iznosi

Osnovne statističke metode – t-test
146
1)
n(n
d
n
1
d
s
2
n
1
i
n
1
i
i
2
i
x
x
2
1
,
gdje je
d
i
=
1
x
i
-
2
x
i
razlika između rezultata ispitanika
i
u 1. i 2. mjerenju
(
i=1...n
)
n
broj ispitanika u uzorku.
Ako se radi o velikim uzorcima (
n>30
),
standardnu pogrešku razlika
moguće je procijeniti formulom
2
1
2
x
1
x
2
1
x
x
2
2
x
x
s
s
r
2
s
s
s
,
gdje je
1
x
s
standardna pogreška aritmetičke sredine prvog mjerenja
2
x
s
standardna pogreška aritmetičke sredine drugog mjerenja
r
korelacija između varijabli prvog i drugog mjerenja (v. poglavlje
2.11, str. 160-179).
Izračunata
t-vrijednost
(kao i kod
t-testa za nezavisne uzorke
)
uspoređuje se s
kritičnom t-vrijednošću
koja se očita iz tablice
B
str.
317 uz određenu pogrešku
p
i broj stupnjeva slobode
df=n-1
. Ako je
izračunata
t-vrijednost
veća od
kritične t-vrijednosti
, zaključuje se, uz
određenu pogrešku
p
, da je razlika između aritmetičkih sredina prvog i
drugog mjerenja statistički značajna, odnosno da je došlo do statistički
značajne promjene u promatranoj varijabli između prvoga i drugog
mjerenja.
Primjer:
Uzorak od
120
učenika testiran je
Seargentovim testom
prije
i poslije tromjesečnog trenažnog procesa provedenoga s ciljem da se
poboljša eksplozivna snaga. Dobiveni su sljedeći rezultati:
10
s
45
x
1
1
8
s
49
x
2
2
r=0,75
Da li su promjene u eksplozivnoj snazi učenika između prvog i drugog
mjerenja statistički značajne uz pogrešku od
0,05
?
Osnovne statističke metode – t-test
147
Statističku značajnost razlika aritmetičkih sredina prvoga i drugog
mjerenja moguće je utvrditi pomoću
t-testa za zavisne uzorke
. Prije
testiranja uobičajeno je postaviti hipoteze:
2
1
0
:
x
x
H
- razlika između aritmetičkih sredina prvoga i drugog
mjerenja nije statistički značajna uz pogrešku
0,05
.
2
1
1
:
x
x
H
- razlika između aritmetičkih sredina prvoga i drugog
mjerenja statistički je značajna uz pogrešku
0,05
.
Zavisno od rezultata
t-testa
bit će prihvaćena jedna od navedenih
hipoteza. Dobivene vrijednosti potrebno je uvrstiti u formulu za
izračunavanje
standardne pogreške aritmetičkih sredina
prvog
91
,
0
95
,
10
10
120
10
s
1
x
i drugog mjerenja
73
,
0
95
,
10
8
120
8
s
2
x
,
pomoću kojih se izračunava
standardna pogreška razlika
0,6.
0,73
0,91
0,75
2
0,73
0,91
s
s
r
2
s
s
s
2
2
x
x
2
x
2
x
x
x
2
1
2
1
2
1
Potom se izračuna
t-vrijednost
6
,
6
6
,
0
4
6
,
0
45
49
2
1
1
2
x
x
s
x
x
t
i usporedi se s
kritičnom t-vrijednošću
(koja se očita iz tablice
B
str.
317 za pogrešku
p=0,05
i broj stupnjeva slobode
df=120-1=119
) koja
iznosi
1,98
t
0,05
119
. Izračunata
t-vrijednost
pokazuje da je razlika
aritmetičkih sredina prvoga i drugog mjerenja statistički značajna jer
je vjerojatnost da se takva razlika dogodi slučajno manja od
0,05
(
5%
).

Osnovne statističke metode – t-test
149
U trećem koraku izračunaju se sume svih stupaca koje se uvrste u
formule za računanje aritmetičkih sredina
39,92
12
479
x
1
;
41,75
12
501
x
1
te u formulu za računanje standardne pogreške razlika
0,57
0,33
132
43,67
132
40,33
84
1)
n(n
d
n
1
d
σ
2
n
1
i
n
1
i
i
2
i
x
x
2
1
.
U posljednjem koraku izračuna se
t-vrijednost
3,19
0,57
41,75
39,92
σ
x
x
t
2
1
x
x
2
1
i usporedi s
kritičnom t-vrijednošću
(koja se očita iz tablice
B
str. 317
za pogrešku
p=0,01
i broj stupnjeva slobode
df=12-1=11
) koja iznosi
3,106
. Izračunata
t-vrijednost
ukazuje na to da je razlika aritmetičkih
sredina prvoga i drugog mjerenja statistički značajna jer je
vjerojatnost da se takva razlika dogodi slučajno manja od
1%
. Stoga
prihvaćamo hipotezu
H
1
.
Napomena
:
Dodatne informacije vezane uz gradivo izneseno u poglavlju 2.8 i 2.9, mogu se pronaći u knjizi B.
Petz: Osnovne statističke metode za nematematičare, poglavlje 9: Razlika između dvije aritmetičke
sredine.
Osnovne statističke metode – Univarijatna analiza varijance
150
Ronald A. Fisher
(1890. - 1962.) diplomirao je
astronomiju na Sveučilištu Cambridge 1912.
godine. Njegov interes za teoriju pogrešaka u
astronomskim promatranjima doveo ga je do
istraživanja statističkih problema. Po završetku
studija do 1919. godine radio je kao učitelj
matematike, nakon čega prelazi na poljoprivredni
institut
Rothamsted Agricultural Experiment
Station
. Od tada počinje njegov plodotvoran
znanstveni rad na razvoju eksperimentalnih nacrta, statističkih metoda i
genetike. Dao je velik doprinos razvoju statističke metodologije, od čega
najznačajniji oblikovanje analize varijance. Objavio je puno znanstvenih
članaka i knjiga, od kojih su najpoznatije
The design of experiments
(1935.) i
Statistical methods and scientific inference
(1956.). Smatra se jednim od
osnivača moderne statistike.
Prema, Kolesarić i Petz, 1999; O'Connor i Robertson:
http://www–groups.dcs.st–and.ac.uk/%7Ehistory/Mathematicians/Fisher.html)
2.10
Univarijatna analiza
varijance
Univarijatna
analiza
varijance koristi se za
utvrđivanje statističke
značajnosti
razlika
između
aritmetičkih
sredina dviju ili više
grupa
u
određenoj
varijabli.
Analizu varijance, koja
se
skraćeno
naziva
ANOVA
(od
engl
.
An
alysis
o
f
Va
riance
),
razvio je Ronald Fisher u prvoj polovini dvadesetog stoljeća. Osnovna
logika univarijatne analize varijance temelji se na omjeru varijabiliteta
između grupa
(engl.
between groups
) i varijabiliteta
unutar grupa
(engl.
within groups
). Ako je varijabilitet između grupa statistički
značajno veći nego varijabilitet unutar grupa, onda se grupe
međusobno statistički značajno razlikuju, odnosno, ne pripadaju istoj
populaciji. Dakle, da bismo utvrdili jeli razlika između aritmetičkih
sredina grupa statistički značajna, varijabilitet između grupa mora biti
veći od varijabiliteta unutar grupa (slika 2.10-1).

Osnovne statističke metode – Univarijatna analiza varijance
152
Odstupanje rezultata ispitanika
x
i
od zajedničke aritmetičke sredine
svih grupa
x
t
i
= x
i
-
x
sastoji se od odstupanja rezultata ispitanika
x
i
od aritmetičke sredine
grupe
x
g
kojoj pripada
i
= x
i
-
x
g
i od odstupanja aritmetičke sredine grupe
x
g
od zajedničke aritmetičke
sredine
x
t
i
=
x
g
-
x.
Dakle,
i
=
i
+
i
ako se odstupanja rezultata ispitanika od zajedničke aritmetičke
sredine kvadriraju i zbroje, dobije se
zajednička suma kvadrata
n
1
i
2
i
tot
)
x
(x
SS
ili
)
x
(n
)
x
(
SS
2
n
1
i
2
i
tot
Suma kvadrata između grupa
predstavlja sumu kvadrata odstupanja
aritmetičkih sredina grupa od zajedničke aritmetičke sredine
k
1
g
2
g
g
ig
)
x
x
(
n
S
S
ili
)
x
(n
)
x
(n
SS
2
k
1
g
2
g
g
ig
.
Suma kvadrata unutar grupa
predstavlja sumu kvadratnih odstupanja
rezultata entiteta od aritmetičkih sredina grupa kojima pripadaju
k
1
g
n
1
i
2
g
gi
ug
g
)
x
(x
SS
,
gdje je
k
broj grupa, a
n
g
broj ispitanika u pojedinoj grupi.
Osnovne statističke metode – Univarijatna analiza varijance
153
Zajednička suma kvadrata
SS
tot
sastoji od sume kvadrata unutar grupa
SS
ug
i sume kvadrata između grupa
SS
ig
.
ug
ig
tot
SS
SS
SS
Da bi se izračunale varijance iz navedenih suma kvadrata, potrebno je
svaku sumu kvadrata podijeliti odgovarajućim brojem stupnjeva
slobode
df
.
df
tot
= n - 1
df
ug
= n - k
df
ig
= k – 1,
gdje je
n
broj entiteta, a
k
broj grupa.
Zajednička (totalna) varijanca
izračuna se
1
n
)
x
(x
σ
n
1
i
2
t
i
2
tot
,
a
varijanca unutar grupa
Dokaz:
Rezultat ispitanika
i
jednak je
)
x
(x
)
x
x
(
x
x
g
ig
g
ig
, gdje je
x
zajednička aritmetička sredina, a
x
g
aritmetička sredina grupe kojoj pripada ispitanik
i
. Pa
je
)
g
ig
g
ig
x
(x
)
x
x
(
)
x
(x
, dakle razlika između rezultata svakog ispitanika i
zajedničke aritmetičke sredine može se prikazati kao zbroj razlika između: aritmetičke
sredine kojoj ispitanik pripada i zajedničke aritmetičke sredine te rezultata ispitanika i
pripadajuće aritmetičke sredine. Ako taj izraz za svakog ispitanika kvadriramo i zbrojimo,
dobijemo
k
1
g
n
1
i
g
ig
g
2
k
1
g
n
1
i
ig
g
g
x
x
x
x
)
x
(x
2
)
(
)
(
2
g
ig
k
1
g
n
1
i
g
ig
k
1
g
n
1
i
g
2
k
1
g
g
g
)
x
x
(
)
x
x
)(
x
x
(
2
)
x
x
(
n
g
g
2
)
x
x
(
)
x
x
(
n
g
ig
k
1
g
n
1
i
2
k
1
g
g
g
g
, budući da je
0
)
x
x
)(
x
x
(
2
g
ig
k
1
g
n
1
i
g
g
jer je zbroj odstupanja od aritmetičke sredine jednak
nuli. Time je dokazano da je
ug
ig
tot
SS
SS
SS

Osnovne statističke metode – Univarijatna analiza varijance
155
dokazao Boneau (1960). Stoga je u praksi potrebno planirati
eksperimente u kojima će uzorci biti slične veličine kako bi pogreške
u računu
analize varijance
i
t - testa
bile što manje.
Primjer:
Četiri slučajno odabrana uzorka od 6 entiteta izmjerena su
jednim testom motorike. Dobiveni su sljedeći rezultati (tablica 2.10-
1). Potrebno je utvrditi pripadaju li grupe istoj populaciji uz pogrešku
0,05.
Tablica 2.10-1.
Rezultati četiriju grupa ispitanika izmjerenih jednim testom motorike
x
1
x
2
x
3
x
4
3
6
1
3
2
3
2
2
4
2
2
2
5
4
3
1
2
5
2
4
4
3
1
5
Statističku značajnost razlika aritmetičkih sredina četiriju promatranih
grupa ispitanika moguće je utvrditi
univarijatnom analizom varijance
.
Zavisno od rezultata
univarijatne analize varijance,
bit će prihvaćena
jedna od navedenih hipoteza:
4
3
2
1
0
:
x
x
x
x
H
- razlike između aritmetičkih sredina
promatranih grupa nisu statistički značajne.
4
3
2
1
1
:
x
x
x
x
H
- razlike između aritmetičkih sredina
promatranih grupa statistički su značajne.
F-vrijednost
, pomoću koje će se testirati navedene hipoteze,
izračunava se u nekoliko koraka:
U prvom se koraku kvadriraju rezultati svih ispitanika, kao što je
prikazano u tablici 2.10-2.
Osnovne statističke metode – Univarijatna analiza varijance
156
Tablica 2.10-2.
Kvadrirani rezultati četiriju grupa ispitanika
izmjerenih jednim testom motorike
x
12
x
22
x
32
x
42
9
36
1
9
4
9
4
4
16
4
4
4
25
16
9
1
4
25
4
16
16
9
1
25
Potom se izračunaju sume rezultata i sume kvadrata rezultata za svaku
grupu i za sve grupe zajedno
x
1
=20;
x
2
=23;
x
3
=11;
x
4
=17;
x
tot
=71
x
1
2
= 74;
x
2
2
=99;
x
3
2
=23;
x
4
2
=59;
x
tot
2
=255
U drugom se koraku izračunaju aritmetičke sredine grupa i zajednička
aritmetička sredina
33
,
3
6
20
x
1
;
83
,
3
6
23
x
2
;
83
,
1
6
11
x
3
;
83
,
2
6
17
x
4
;
96
,
2
24
71
x
tot
U trećem se koraku izračunaju:
ukupna suma kvadrata
72
,
44
)
96
,
2
24
(
255
)
x
n
(
)
x
(
SS
2
2
t
n
1
i
2
i
tot
suma kvadrata između grupa
40
,
12
)
28
,
210
68
,
222
(
)
x
n
(
)
x
n
(
SS
2
t
k
1
g
2
g
g
ig
suma kvadrata unutar grupa
32
,
32
40
,
12
72
,
44
SS
SS
SS
ig
tot
ug
U četvrtom se koraku izračunaju:

Osnovne statističke metode – Univarijatna analiza varijance
158
S obzirom na to da je izračunata
F-vrijednost
manja od granične
vrijednosti, prihvaćamo
H
0
i zaključujemo da nema statistički
značajne razlike između aritmetičkih sredina grupa, odnosno ne
možemo uz zadanu pogrešku tvrditi da grupe pripadaju različitim
populacijama.
Statističku značajnost razlike između aritmetičkih sredina dviju grupa
moguće je utvrditi
t-testom
i
univarijatnom analizom varijance
.
Naime, ako utvrđujemo statističku značajnost razlike između
aritmetičkih sredina dviju grupa, tada je
F-vrijednost
ekvivalentna
t-
vrijednosti
, odnosno
F = t
2
.
Ako smo analizom varijance utvrdili da četri analizirane grupe ne
pripadaju istoj populaciji, postavlja se pitanje koje se od njih
međusobno statistički značajno razlikuju. Za odgovor na to pitanje
morali bismo međusobno uspoređivati sve parove uzoraka (npr.
t-
testom
). To su:
1.
prvi i drugi
2.
prvi i treći
3.
prvi i četvrti
4.
drugi i treći
5.
drugi i četvrti
6.
treći i četvrti.
Ukupan broj svih mogućih usporedaba za
k
uzoraka dobije se
formulom
2
1)
(k
k
c
.
Tako, primjerice, za 8 uzoraka imamo 28 parova koje međusobno
uspoređujemo, pa vjerojatnost dobivanja statistički značajne razlike,
kad ona stvarno ne postoji, nije više, primjerice, 0,01 ili 0,05 nego je
znatno viša. Uspoređujući 28 parova uzoraka, vjerojatno ćemo dobiti
da se barem jedan par uzoraka statistički značajno razlikuje, iako ti
uzorci pripadaju istoj populaciji, jer pri pogrešci od 0,05, jedna će od
dvadeset razlika biti statistički značajna iako u stvari nije. Stoga je
potrebno smanjit vjerojatnost pogreške koja nastaje zbog većeg broja
međusobnih usporedaba. Jednostavno rješenje ovog problema ponudio
je Bonferroni (1936). On predlaže da se pogreška statističkog
Osnovne statističke metode – Univarijatna analiza varijance
159
zaključka (
p
) podijeli brojem mogućih usporedaba (
c
). Dakle,
korigirana pogreška izračuna se formulom
c
p
p
'
.
Primjerice, ako uspoređujemo 5 uzoraka uz pogrešku 0,01, broj
mogućih usporedaba parova uzoraka je 10 (
c=5·4/2=10
), pa
korigirana pogreška statističkog zaključka nije više 0,01 već
0,001
10
0.01
c
p
p'
.
Osim ovog vrlo jednostavnog postupka, postoji više složenijih koje su
predložili različiti autori (Tukey, Scheffe, Duncan i dr.), a koji su
implementirani u većinu poznatijih računalnih programa za statističku
obranu podataka (npr.
STATISTICA
,
SPSS
).

Osnovne statističke metode - Korelacija
161
prirodne sposobnosti raspodjeljuju prema normalnoj distribuciji. Prvi je
uveo pojam korelacije u radu
Co-relations and their measurement,
chiefly from anthropometric data,
objavljenom 1888. godine. Surađivao
je s Karlom Pearsonom i pomogao je u osnivanju prvog statističkog
časopisa
Biometrika.
Prema, Kolesarić i Petz, 1999.;http://www.mugu.com/galton/
Francis Galton
(1822. - 1911.) engleski
antropolog (studirao medicinu i matematiku),
rođak znamenitog Charlesa Darwina, među
prvima je počeo znanstveno istraživati
inteligenciju čovjeka. Godine 1884. osnovao je
Antropometrijski laboratorij
za istraživanje
individualnih razlika u antropološkim karak-
teristikama. U svojim je istraživanjima za
analizu prikupljenih podataka prvi koristio
matematičke metode, čime je dao značajan
doprinos razvoju statistike. Dokazivao je da se
U ovom poglavlju razmotrit će se utvrđivanje odnosa dviju varijabli,
premda se može utvrđivati i međusobna povezanost više varijabli
(multipla ili višestruka korelacija). Potrebno je naglasiti da se
korelacijska analiza provodi na zavisnim uzorcima, odnosno, na istim
ispitanicima mjerenima dva ili više puta istim ili različitim mjernim
instrumentima.
Začetnikom korelacijske i
regresijske analize smatra
se
engleski
antropolog
Francis Galton
koji je
istraživao utjecaj naslijeđa
na
razvoj
čovjekovih
karakteristika. Surađujući s
Galtonom, veliki doprinos
razvoju statističkih metoda
i njihovoj primjeni u analizi
bioloških problema dao je
Karl Pearson
. Pearson je
razvio brojne statističke
postupake, među kojima i
produkt-moment
koeficijent
korelacije
(
r
)
n
z
z
r
n
i
y
x
i
i
1
)
(
,
gdje je
i
x
z
standardizirani rezultat
ispitanika
i
u varijabli
x
i
y
z
standardizirani
rezultat ispitanika
i
u
varijabli
y
Osnovne statističke metode - Korelacija
162
metoda (
korelacijske i regresijske analize
,
2
– test
…). Uveo je pojam
standardna devijacija
. Zajedno s Weldonom i Galtonom osnivač je prvog
statističkog časopisa
Biometrika.
Jedan je od najznačajnijih statističara.
Prema, Kolesarić i Petz, 1999; http://en.wikipedia.org/wiki/Karl_Pearson
Karl Pearson
(1857. – 1936.) diplomirao je na
Sveučilištu Cambridge 1879. godine, nakon
čega je proveo karijeru na
Universthy College
u
Londonu, gdje je bio profesor od 1911. do 1933.
g. Surađujući s Galtonom, razvija matematičko -
statističke metode za analizu bioloških
problema. Od 1893. do 1912. g. napisao je niz
radova
pod
naslovom
Mathematical
Contribution to the Theory of Evolution
, čime je
dao izniman doprinos razvoju statističkih
Pearsonov koeficijent korelacije (
r
) može se izračunati na različite
načine. Jedan od njih je pomoću formule
n
i
yi
n
i
xi
n
i
yi
xi
d
d
d
d
r
1
2
1
2
1
,
gdje je
d
x
=x
i
-
x
centrirani
rezultat entiteta
i
u
varijabli
x
d
yi
= y
i
-
y
centrirani
rezultat entiteta
i
u
varijabli
y
Koeficijent korelacije je
moguće izračunati iz
originalnih
rezultata
(intaktni
realni
oblik)
formulom:
n
i
n
i
i
i
n
i
n
i
i
i
n
i
n
i
i
n
i
i
i
i
y
y
n
x
x
n
y
x
y
x
n
r
1
2
1
2
1
2
1
2
1
1
1

Osnovne statističke metode - Korelacija
164
Korelacijski odnos varijabli može se prikazati dijagramom.
Primjerice, na
apscisi
se nalaze rezultati entiteta u varijabli
x
, a na
ordinati
rezultati entiteta u varijabli
y
. Na sjecištu pravaca okomitih na
osi
x
i
y
dobiju se rezultati entiteta u bivarijatnom koordinatnom
sustavu (slika 2.11-1). Rezultat entiteta označava se točkom s
koordinatama
T(x
i
,y
i
)
.
Izvod:
Pearsonov koeficijent korelacije iz standardiziranih rezultata izračuna se formulom
n
1
i
yi
xi
z
z
n
1
r
; zamjenom
z–vrijednosti
odgovarajućim formulama za njihovo
izračunavanje dobijemo
n
1
i
i
i
y
x
n
1
i
y
i
x
i
n
1
i
yi
xi
y
y
x
x
σ
nσ
1
σ
y
y
σ
x
x
n
1
z
z
n
1
r
.
Množenjem elemenata u zagradama dobijemo
n
1
i
n
1
i
i
n
1
i
n
1
i
i
i
y
x
n
1
i
i
i
i
i
y
x
y
x
x
y
y
x
y
x
σ
nσ
1
y
x
x
y
y
x
y
x
σ
nσ
1
r
S obzirom na to da je
x
n
x
n
i
i
1
, a
y
n
y
n
i
i
1
, dobijemo
y
x
n
y
x
σ
nσ
1
y
x
n
y
x
n
y
x
n
y
x
σ
nσ
1
r
n
1
i
i
y
x
n
1
i
i
y
x
.
Ako u ovaj izraz uvrstimo formule za izračunavanje aritmetičkih sredina i standardnih
devijacija, dobijemo
2
n
1
i
i
n
1
i
2
i
2
n
1
i
i
n
1
i
2
i
n
i
i
n
i
n
i
i
i
i
y
y
n
n
1
x
x
n
n
1
n
n
y
n
x
n
y
x
r
1
1
1
. Ako brojnik i nazivnik
pomnožimo sa
n
,
dobijemo
2
1
1
2
2
1
1
2
1
1
1
n
i
i
n
i
i
n
i
i
n
i
i
n
i
i
n
i
i
n
i
i
i
y
y
n
x
x
n
y
x
y
x
n
r
formulu za izračunavanje Pearsenovog koeficijenta korelacije iz orginalnih podataka.
Osnovne statističke metode - Korelacija
165
Slika 2.11-1.
Potpuna pozitivna korelacija (r = + 1)
Ako na temelju rezultata nekog ispitanika u jednoj varijabli možemo
točno predvidjeti rezultat u drugoj varijabli (slika 2.11-1), odnosno,
ako svako povećanje/smanjenje rezultata u jednoj varijabli prati
proporcionalno povećanje/smanjenje rezultata u drugoj varijabli, onda
se radi o
potpunoj pozitivnoj korelaciji
(
r=+1
). Dakle, svi ispitanici s
određenim iznadprosječnim rezultatom u varijabli
x
imaju jednako
toliko iznadprosječan rezultat u varijabli
y
, a svi ispitanici s određenim
ispodprosječnim rezultatom u varijabli
x
imaju jednako toliko
ispodprosječan rezultat u varijabli
y
.
Ako svako povećanje rezultata u jednoj varijabli prati isto toliko
smanjenje rezultata u drugoj varijabli (slika 2.11-2), odnosno, ako
postoji potpuna obrnuto proporcionalna veza dviju varijabli, onda se
takva korelacija zove
potpuna negativna korelacija
(
r=-1
). U tom
slučaju svi ispitanici s određenim iznadprosječnim rezultatom u
varijabli
x
imaju jednako toliko ispodprosječan rezultat u varijabli
y
, a
svi ispitanici s određenim ispodprosječnim rezultatom u varijabli
x
imaju jednako toliko iznadprosječan rezultat u varijabli
y
.
x
y
x
i
y
i

Osnovne statističke metode - Korelacija
167
Ako većim rezultatima ispitanika u jednoj varijabli najvjerojatnije
odgovaraju veći rezultati u drugoj varijabli, odnosno određenom
rezultatu u jednoj varijabli ne odgovara samo jedan rezultat u drugoj
varijabli već se rezultati kreću u nekom intervalu tada se radi o
nepotpunoj pozitivnoj korelaciji
(
0<r<+1
).
Slika 2.11-4.
Nepotpuna pozitivna korelacija (0 < r < + 1)
Dakle, na osnovi rezultata ispitanika u jednoj varijabli nije moguće sa
100%
sigurnošću tvrditi koliki je njegov rezultat u drugoj varijabli. S
određenom vjerojatnošću pretpostavljamo da se ispitanikov rezultat
kreće u određenom intervalu (slika 2.11-4). Interval će biti to manji
što je koeficijent korelacije bliži
1
(elipsoidni oblik točaka tendira k
pravcu), odnosno veći što je bliži
0
(elipsoidni oblik točaka tendira ka
kružnom obliku). Primjerice, korelacija između visine i težine čovjeka
je pozitivna i nepotpuna. To znači da će viši čovjek najvjerojatnije biti
teži, ali ne možemo točno prognozirati njegovu tjelesnu težinu samo
na temelju tjelesne visine. Ako je neki čovjek visok 185 cm, on je
navjerojatnije težak oko 75 kg, ali je poznato da osobe visoke 185 cm
mogu biti i teže i lakše od 75 kg. Povezanost svakako postoji,
međutim težina ne ovisi isključivo o visini tijela, nego i o drugim
karakteristikama (potkožno masno tkivo, mišićna masa itd.).
Sve što je rečeno za nepotpunu pozitivnu korelaciju, važi i za
nepotpunu negativnu, osim što je odnos između varijabli obrnuto
proporcionalan (slika 2.11-5).
x
y
x
i
y
i
Osnovne statističke metode - Korelacija
168
Slika 2.11-5.
Nepotpuna negativna korelacija ( 0>r>-1)
Radi lakše interpretacije korelacije često se koristi
koeficijent
determinacije
. On predstavlja proporciju zajedničkog varijabiliteta
dviju varijabli, a izračuna se
= r
2
.
Koeficijent determinacije pomnožen sa
100
daje postotak kojim se
može predviđati rezultat u jednoj varijabli ako nam je poznat rezultat
u drugoj varijabli. Tako npr., korelacija od
0,66
i iz nje izveden
koeficijent determinacije pomnožen sa
100
ukazuje na to da
uspješnost predviđanja rezultata na jednom testu na osnovi rezultata u
drugom testu iznosi
43%
.
Osim toga, valja napomenuti da
Pearsonov produkt - moment
koeficijent korelacije
izražava jačinu
linearanog
odnosa dviju
varijabli, što se ne smije izgubiti iz vida pri njegovoj interpretaciji.
Naime, odnos između dvije varijable ne mora biti linearan, pa će u
tom slučaju
produkt - moment
koeficijent korelacije
pokazati znatno
manju povezanost od stvarne. Stoga je potrebno, prije računanja
koeficijenta korelacije, izraditi korelacijski dijagram (
engl.
scatter
plot
) kako bi se uočilo radi li se o linearnom ili nelinearnom odnosu
dviju varijabli. Ako se iz korelacijskog dijagrama uočava linearan
odnos između dviju varijabli, tada je opravdano izračunati
produkt -
moment
koeficijent korelacije
. Međutim, ako uočeni odnos nije
linearan (slika 2.11-12) već nelinearan (logaritamski, eksponencijalni,
x
y
x
i
y
i

Osnovne statističke metode - Korelacija
170
prošli klasifikacijski ispit). To za posljedicu ima niži koeficijent
korelacije, što ilustrira slika 2.11-13.
Slika 2.11-13.
Primjer korelacijskih dijagrama prije i nakon selekcije entiteta
Zbog neadekvatnog uzorka entiteta koeficijent korelacije može biti i
znatno veći nego što je stvarna povezanost dviju varijabli. Dobar
primjer za takvu pojavu dao je B. Petz u svom udžbeniku (1997). Ako
se izračuna koeficijent korelacije između varijabli
sposobnost pisanja
i
dužina stopala
na uzorku djece od 7 do 15 godina, tada će koeficijent
korelacije između ovih varijabli, za koje nije teško pretpostaviti da
međusobno nisu povezane, biti vrlo visok. Naime, s porastom godina
djece raste
sposobnost pisanja
i
dužina stopala
. Stvarna korelacija
između
sposobnosti pisanja
i
dužine stopala
je vjerojatno jednaka
nuli, međutim, visoki koeficijent korelacije je posljedica
neadekvatnog uzorka entititeta. Kada bismo računali korelaciju
posebno na uzorcima učenika svakog razreda osnovne škole,
vjerojatno bismo dobili koeficijente koralacije jednake nuli. Dakle,
visok koeficijent korelacije posljedica je utjecaja treće varijable -
dob
,
koja je u pozitivnoj korelaciji s obje varijable (što su djeca starija to
bolje pišu, a i dužih su stopala). Ako bismo isključili njen utjecaj, tada
bi korelacija između varijabli
sposobnost čitanja
i
dužina stopala
bila
vjerojatno nula. Analitički se to postiže pomoću formule za računanje
tzv.
parcijalne korelacije
)
r
)(1
r
(1
r
r
r
r
2
yz
2
xz
yz
xz
xy
xy/z
,
gdje je
r
yx/z
koeficijent parcijalne korelacije između varijabli
x
i
y
r
yx
koeficijent korelacije između varijabli
x
i
y
r
xz
koeficijent korelacije između varijabli
x
i
z
x
y
x
y
neselekcionirani uzorak
selekcionirani uzorak
Osnovne statističke metode - Korelacija
171
r
yz
koeficijent korelacije između varijabli
y
i
z
Parcijalna korelacije
predstavlja stupanj povezanosti između dvije
varijable iz kojeg je isključen utjecaj jedne ili više ostalih varijabli. U
navedenom primjeru izračunavanje koeficijenta parcijalne korelacije
bilo je nužno zbog pogrešnog planiranja eksperimenta, odnosno,
neadekvatnog izbora uzorka entiteta.
2.11.1. Korelacija kao kosinus kuta dvaju vektora
Kosinus kuta između dvaju vektora,
x
i
y
, jednak je koeficijentu
korelacije među njima. Kosinus kuta koji zatvaraju dva vektora istog
reda
x
i
y
izračuna se kao omjer skalarnog produkta dvaju vektora i
umnoška njihovih normi
1/2
T
T
1/2
T
cos
α
y
y
y
x
x
x
,
odnosno
y
x
cos
α
T
y
x
Ako se rezultati u varijablama centriraju, odnosno ako su izraženi kao
odstupanja od odgovarajućih aritmetičkih sredina,
x
ci
= x
i
-
x
y
ci
= y
i
-
y
,
tada je kosinus kuta
jednak
n
1
i
2
ci
n
1
i
2
ci
n
1
i
ci
ci
y
x
y
x
cos
,
što je formula za izračunavanje koeficijenta korelacije pa je
r = cos
.
Budući da je kosinus kuta između dvaju centriranih i normiranih
vektora jednak koeficijentu korelacije, odnose između varijabli-
vektora moguće je prikazivati geometrijski. Ako je korelacija između
varijabli jednaka nuli (
r= 0
), tada su dva normirana vektora pod
kutom od 90
(slika 2.11-6).

Osnovne statističke metode - Korelacija
173
Ako je korelacija nepotpuna negativna (
-1<r<0
), tada je kut između
dvaju vektora veći od 90
, a manji od 180
(slika 2.11-10).
Slika 2.11-10.
Negativna nepotpuna korelacija ( -1 < r < 0)
2.11.2. Računanje korelacija matričnom
algebrom
Neka je
X
matrica podataka dobivena opisivanjem nekog skupa od
n
entiteta skupom od
m
varijabli
X
= (x
ij
)
,
gdje je
i = 1,…,n
, a
j = 1,…,m
.
Podaci iz matrice
X
standardiziraju se operacijom
Z
=
X
c
V
-1
,
gdje je
X
c
= (X - PX)
matrica centriranih podataka,
P = 1(1
T
1)
-1
1
T
lijevi centroidni projektor matrice
X
, a
V
dijagonalna matrica
standardnih devijacija.
Matrica korelacija
R
izračuna se operacijom
R
=
Z
T
Z n
-1
=
{(X - PX)V
-1
}
T
{(X - PX)V
-1
}
n
-1
=
V
-1
(X
T
- X
T
P)(X - PX)V
-1
n
-1
=
V
-1
(X
T
X - X
T
PX - X
T
PX + X
T
PPX)V
-1
n
-1
=
V
-1
(X
T
X - X
T
PX) V
-1
n
-1
=
V
-1
C V
-1
,
gdje je
V
-1
inverz dijagonalne matrice standardnih devijacija
V
, a
C
matrica kovarijanci.
1
x
cos
= -r
y
Osnovne statističke metode - Korelacija
174
Matrica korelacija
R
je kvadratnog oblika, simetrična je s obzirom na
glavnu
dijagonalu
u
kojoj
se
nalaze
jedinice
(varijance
standardiziranih varijabli jednake su jedinici), a izvandijagonalni
elementi predstavljaju korelacije među varijablama. S obzirom da je
matrica, kako je već rečeno, simetrična, svaki koeficijent korelacije
ponavlja se dva puta (slika 2.11-11).
Tablica 2.11-11.
Matrica korelacija
R
za četiri varijable
1
r
12
r
13
r
14
r
21
1
r
23
r
24
r
31
r
32
1
r
34
r
41
r
42
r
43
1
Primjer:
9 ispitanika postiglo je sljedeće rezultate u
skoku udalj
(SD),
trčanju na 100 metara
(T100m) i
bacanju kugle
(BK). Potrebno je
izračunati koeficijente korelacije među varijablama uz pomoć
matrične algebre.
Matrica centriranih podataka
X
c
dobije se operacijom
X
c
=
X
-
1m
T
,
gdje je
1
sumacijski vektor sa
n
jedinica, a
m
=
X
T
1
n
-1
vektor
aritmetičkih sredina.
SD
T100m
BK
359
13,6
561
321
13,9
550
346
13,7
538
332
14
490
450
12,2
518
314
14,1
551
410
12,5
589
425
12,3
602
369
13,5
547
X
=

Osnovne statističke metode - Korelacija
176
a operacijom
V
=
(
diag
C)
1/2
dijagonalna matrica standardnih devijacija
V
.
Podaci iz matrice
X
standardiziraju se operacijom
Matrica korelacija
R
izračuna se operacijom
SD
T100m
BK
-10,56
0,29
11,44
-48,56
0,59
0,44
-23,56
0,39
-11,56
-37,56
0,69
-59,56
80,44
-1,11
-31,56
-55,56
0,79
1,44
40,44
-0,81
39,44
55,44
-1,01
52,44
-0,56
0,19
-2,56
X
c
SD
T100m
BK
SD
0,02
0,00
0,00
T100m
0,00
1,31
0,00
BK
0,00
0,00
0,03
V
-1
SD
T100m
BK
-0,22
0,38
0,34
-1,00
0,77
0,01
-0,49
0,51
-0,34
-0,78
0,91
-1,76
1,66
-1,46
-0,93
-1,15
1,04
0,04
0,84
-1,07
1,17
1,15
-1,33
1,55
-0,01
0,25
-0,08
Z
=
SD
T100m
BK
SD
2337,78
0
0
T100m
0
0,58
0
BK
0
0
1140,28
V
2
=diag
C
SD
T100m
BK
SD
48,35
0
0
T100m
0
0,76
0
BK
0
0
33,77
V
=(diag
C
)
1/2
SD
T100m
BK
-0,22
0,38
0,34
-1,00
0,77
0,01
-0,49
0,51
-0,34
-0,78
0,91
-1,76
1,66
-1,46
-0,93
-1,15
1,04
0,04
0,84
-1,07
1,17
1,15
-1,33
1,55
-0,01
0,25
-0,08
Z
SD
T100m
BK
SD
1,00
-0,98
0,33
T100m
-0,98
1,00
-0,44
BK
0,33
-0,44
1,00
=
R
SD
-0,22
-1,00
-0,49
-0,78
1,66
-1,15
0,84
1,15
T100m
0,38
0,77
0,51
0,91
-1,46
1,04
-1,07
-1,33
BK
0,34
0,01
-0,34
-1,76
-0,93
0,04
1,17
1,55
Z
T
9
-1
n
-1
Osnovne statističke metode - Korelacija
177
2.11.3. Testiranje značajnosti koeficijenta
korelacije
Koeficijent korelacije dviju varijabli najčešće se izračunava na uzorku
ispitanika koji je izvučen iz određene populacije, pa se postavlja
pitanje je li dobiveni koeficijent korelacije uistinu tolik i u populaciji.
S ciljem da se uz određenu grešku zaključivanja dobiju informacije o
povezanosti dviju varijabli u populaciji, utvrđuje se statistička
značajnost koeficijenta korelacije dobivenog na uzorku. U tu svrhu
postavljamo hipoteze:
H
0
: r = 0 -
korelacija nije statistički značajna uz pogrešku
p
H
1
: r
0
-
korelacija je statistički značajna uz pogrešku
p
Statistička značajnost koeficijenta korelacije osobito je važno jer
ukazuje na ovisnost koeficijenta korelacije o veličini uzorka iz kojega
je izračunat. Test značajnosti utemeljen je na pretpostavci da je svaka
od dviju varijabli normalno distribuirana te da njihova zajednička,
bivarijatna distribucija odgovara normalnoj. Koeficijent korelacije
testira se po sljedećoj formuli
2
r
1
2
n
r
t
,
gdje je:
t
vrijednost testa koja se distribuira kao
Studentova t-distribucija
r
koeficijent korelacije
n
broj entiteta.
Iz formule je vidljivo da
t-vrijednost
ovisi o broju ispitanika i veličini
koeficijenta korelacije. Vrijednost
t
je veća što je stupanj povezanosti
među varijablama jači i što je broj entiteta u uzorku veći.
T-vrijednost
se distribuira kao
Studentova t-distribucija
.
Izračunata
t-vrijednost
usporedi se s kritičnom
t-vrijednošću
koja se
očita iz tablice za određeni broj stupnjeva slobode (
df=n-2
)
i odabranu
pogrešku (
p=0,05
ili
p=0,01
).
Ako je izračunata
t-vrijednost
veća od
tablične t-vrijednosti
, odbacuje
se nulta hipoteza i zaključuje da je koeficijent korelacije statistički
značajan, uz mogućnost pogreške od
0,05
ili
0,01
, i to stoga jer je

Osnovne statističke metode - Korelacija
179
0,69
37,52
26
1408
26
44
32
26
26
120
6
14
38
6
26
14
65
6
y
y
n
x
x
n
y
x
y
x
n
r
2
2
n
1
i
2
n
1
i
i
2
i
n
1
i
2
n
1
i
i
2
i
n
1
i
n
1
i
i
n
1
i
i
i
i
Izračunatati koeficijent korelacije uvrstimo u formulu za testiranje
statističke značajnosti
91
,
1
52
,
0
4
69
,
0
69
,
0
1
4
69
,
0
r
1
2
n
r
t
2
2
Iz tablice
t-vrijednosti
(tablica
B
, str. 317) za broj stupnjeva slobode
df
= n-2=4
i pogrešku
p=0,05
dobije se granična
t-vrijednost
4
t
0.05
= 2,78
S obzirom na to da je izračunata
t-vrijednost
manja od granične,
prihvaćamo
H
0
: r = 0
i zaključujemo da korelacija nije statistički značajna, odnosno ne
možemo uz zadanu pogrešku tvrditi da je korelacija u populaciji
različita od nule.
Osnovne statističke metode - Korelacija
180

Multivarijatne metode – Regresijska analiza
182
On the Theory of Correlation
, objavljenom 1897. godine,
razvija vlastiti pristup korelaciji te je postavio temelje za
višestruku regresijsku analizu.
Prema, Kolesarić i Petz, 1999., i O'Connor and Robertson: http://www-
groups.dcs.st-d.ac.uk/%7Ehistory/Mathematicians/Yule.html
George Udny Yule (1871. - 1951.)
britanski statističar. Nakon što je
diplomirao inženjerstvo i fiziku, od
1893. godine počinje surađivati s
Karlom Pearsonom na
University
College
u Londonu, gdje je od
1896. godine predavao primije-
njenu matematiku, a od 1912.
statistiku na
Cambridgeu
. U radu
3.1
Regresijska
analiza
Regresijska analiza je matematičko-statistički postupak kojim se
utvrđuje odgovarajuća funkcionalna veza između jedne
zavisne
varijable
i jedne ili više
nezavisnih varijabli
. Time se omogućava
predviđanje zavisne varijable na temelju promjena u skupu nezavisnih
varijabli.
U razvoju regresijske analize
važnu ulogu imaju radovi
Gaussa, Galtona, Pearsona i
Yulea. Pearson i Galton su razvili
korelacijsku analizu proučavajući
nasljedne osobine te upotrijebili
regresijsku jednadžbu kako bi
utvrdili
funkcionalni
odnos
između visine očeva i sinova.
Pearson je otkrio da je Gauss
sedamdeset godina prije njih
koristio regresijsku analizu za određivanje orbite planeta (Viskić-
Štalec, 1991). Yule je postavio temelje višestrukoj regresijskoj analizi
(Yule, 1897).
Multivarijatne metode – Regresijska analiza
183
Znanstveni članak G. U. Yulea
On the Theory of Correlation
objavljen je u časopisu
Journal of the Royal Statistical Society
1897. godine.
Naziv
regresijska
analiza
potječe od
Francisa Galtona
koji je, proučavajući odnos
između
nekih
osobina,
primjetio
da,
primjerice,
izrazito visoki očevi imaju
visoku djecu, ali ona nisu
toliko visoka kao očevi, a da
izrazito niski očevi imaju
nisku djecu, ali nešto višu od
očeva. Ovu tendenciju da se
ekstremne vrijednosti koje
postoje u jednoj generaciji u
sljedećoj pomaknu prema
prosjeku, Galton je nazvao
zakon o regresiji
1
prema
prosječnosti,
nakon čega se za
matematičku funkciju kojom
se uspostavlja funkcionalna
veza između dviju varijabli
počeo upotrebljavati naziv
regresijska funkcija
, a za
cijeli postupak
regresijska analiza
.
Opći oblik regresijskog modela moguće je izraziti sljedećom relacijom
e
X
X
X
f
Y
m
)
,.......,
,
(
2
1
,
gdje je
Y
zavisna (kriterijska) varijabla
X
1
,…,X
m
nezavisne (prediktorske) varijable
e
greške prognoze
f
odgovarajuća funkcija.
Dakle, pomoću regresijske analize možemo predviđati vrijednosti
zavisne varijable na temelju promjena nezavisnih varijabli. Ako je
moguće funkcionalnu vezu jedne zavisne i jedne ili više nezavisnih
varijabli izraziti odgovarajućim matematičkim modelom na temelju
kojega je moguće točno utvrđivati vrijednosti zavisne varijable na
osnovi varijacija drugih varijable, radi se o
determinističkom modelu
1
Regresija (
lat. regressio
) - povratak, vraćanje, nazadovanje i sl.

Multivarijatne metode – Regresijska analiza
185
3.1.1. Jednostavna linearna regresijska analiza
Jednostavnom regresijskom analizom izražava se odnos dviju pojava.
Vrijednosti pojave čije se varijacije objašnjavaju (prognoziraju)
predstavljaju vrijednosti
zavisne (kriterijske) varijable
y
,
dok
vrijednosti pojave na temelju koje se objašnjavaju varijacije zavisne
varijable predstavljaju vrijednosti
nezavisne (prediktorske) varijable
x
. Opći je oblik jednostavne regresije
e
)
x
(
f
y
Međutim, pitanje je koja funkcija, odnosno, koji model (linearni,
eksponencijalni, logaritamski, polinom
m-tog
stupnja itd.) najbolje
objašnjava relaciju dviju varijabli. S obzirom na to da ne postoji
jedinstvena metoda odabira modela koji najbolje aproksimira
određenu funkcionalnu zavisnost varijabli, jedan od najjednostavnijih
i najčešće korištenih načina je tzv.
empirijski pristup
koji se zasniva
na zakonu velikih brojeva. Primjerice, ako se za neki skup empirijskih
podataka (
n
entiteta opisanih dvjema varijablama) želi pronaći takva
matematička funkcija koja najbolje aproksimira odnos dviju varijabli,
onda je potreban grafički prikaz rasipanja rezultata u koordinatnom
sustavu (korelacijski dijagram). Na
apscisi
(os
x
) se
nalaze rezultati
nezavisne varijable, a na
ordinati
(os
y
) rezultati zavisne varijable.
Svaki je rezultat u koordinatnom sustavu predstavljen odgovarajućom
točkom s koordinatama
T(x
i
,y
i
)
.
Slika 3.1-2.
Rezultati n entiteta u koordinatnom sustavu varijabli X i Y
x
y
x
i
y
i
Multivarijatne metode – Regresijska analiza
186
Prema rasporedu točaka u koordinatnom sustavu istraživač donosi
odluku o obliku funkcionalne veze te bira odgovarajuću funkciju
f(x)
.
Da bismo bili što sigurniji u oblik matematičke funkcije koja će
najbolje aproksimirati odnos rezultata dviju varijabli
,
potrebno je
raspolagati velikim brojem empirijskih podataka, tako da je iz oblika
raspodjele moguće uočiti oblik odgovarajuće matematičke funkcije.
Vrlo često korištena matematička funkcija kojom se može
aproksimirati linearnu zavisnost između varijabli jest
jednadžba
pravca
.
e
b
b
)
x
(
f
1
0
x
y
,
gdje je
y
zavisna varijabla
x
nezavisna varijabla
b
0
i
b
1
regresijski koeficijenti
e
rezidualne vrijednosti ili greške prognoze.
Dakle, jednostavna linearna regresijska analiza upotrebljava se za
utvrđivanje
linearne
zavisnosti jedne zavisne i jedne nezavisne
varijable.
Neka je svaki entitet slučajno izabranog uzorka od
n
entiteta iz
populacije
P
izmjeren u varijablama
y
i
x
s rezultatom (
x
i
, y
i
),
i=1,…,n
. Ako postoji linearna zavisnost rezultata entiteta u
varijablama
y
i
x
, tada je regresijska funkcija jednaka jednadžbi pravca
y
i
= b
0
+ b
1
x
i
+ e
i ;
i = 1,2,…,n
gdje je
y
i
rezultat entiteta
i
u zavisnoj varijabli
b
0
i
b
1
regresijski koeficijenti
x
i
rezultat entiteta
i
u nezavisnoj varijabli
e
i
rezidualna vrijednost entiteta
i.
U matričnom obliku
y = X b + e
n
1
1
0
n
1
n
1
e
.
.
.
e
b
b
x
1
.
.
.
.
.
.
x
1
y
.
.
.
y
,

Multivarijatne metode – Regresijska analiza
188
najmanjih kvadrata. Koeficijenti
b
0
i
b
1
su nepoznanice koje treba
izračunati, a
e
i
su rezidualne vrijednosti s očekivanom vrijednošću
E(e) = 0
Sustav normalnih jednadžbi
2
X
T
y = X
T
X b
,
gdje je
n
1
i
2
i
n
1
i
i
n
1
i
i
n
2
1
n
2
1
x
x
x
n
x
1
.
.
.
.
x
1
x
1
x
.
.
x
x
1
.
.
1
1
X
X
T
n
1
i
i
i
n
1
i
i
n
2
1
n
2
1
y
x
y
y
.
.
y
y
x
.
.
x
x
1
.
.
1
1
y
X
T
svodi se na oblik
n
1
i
i
i
n
1
i
i
1
0
n
1
i
2
i
n
1
i
i
n
1
i
i
y
x
y
b
b
x
x
x
n
ili
n
1
i
i
n
1
i
i
1
0
y
x
b
n
b
2
Normalne jednadžbe su linearne po koeficijentima
b
0
,…,b
m
.
Multivarijatne metode – Regresijska analiza
189
n
1
i
i
i
n
1
i
2
i
1
n
1
i
i
0
y
x
x
b
x
b
Ako se lijeva i desna strana pomnoži sa
n
-1
, dobije se
b
0
+ b
1
x =
y
pa je
b
0
=
y – b
1
x
Iz gornje relacije vidljivo je da za
b
1
= 0
vrijednost zavisne varijable
za bilo koju vrijednost nezavisne varijable jednaka je njenoj
aritmetičkoj sredini
y = b
0
. To ukazuje da ne postoji nikakva
funkcionalna zavisnost između varijabli.
Vektor regresijskih koeficijenata izračuna se primjenom inverza
matrice
X
T
X
b = (X
T
X)
-1
X
T
y
,
odnosno
n
1
i
i
i
n
1
i
i
1
n
1
i
2
i
n
1
i
i
n
1
i
i
1
0
y
x
y
x
x
x
n
b
b
Slijedi da je
n
1
i
2
i
n
1
i
2
i
n
1
i
i
i
n
1
i
i
n
1
i
2
i
n
1
i
i
0
)
x
(
x
n
y
x
x
x
y
b
n
i
i
n
i
i
n
i
i
n
i
i
n
i
i
i
x
x
n
y
x
y
x
n
b
1
2
1
2
1
1
1
1
)
(

Multivarijatne metode – Regresijska analiza
191
Rezidualni vektor
e
dobije se
e = y - y' = y – X b
Elementi vektora
e
predstavljaju odstupanja izmjerenih vrijednosti
zavisne varijable
y
i
od prognoziranih vrijednosti
y
i
’
.
Jednadžba
y
i
’=b
0
+b
1
x
i
aproksimira odnos varijabli u smislu
aritmetičke sredine. Stoga za vrijednosti vektora
e
vrijede sljedeće
pretpostavke:
očekivana vrijednost jednaka je nuli, odnosno prosječna pogreška u
beskonačno dugoj seriji eksperimenata je nula:
E(e) = 0,
odnosno
E(y) = b
0
+ b
1
x
varijanca distribucije reziduala
e
i
je konstantna za sve vrijednosti
x
i
distribucija vjerojatnosti reziduala
e
i
je normalna
rezidualne vrijednosti su međusobno nezavisne.
Slika 3.1-5:
Distribucije rezidualnih rezultata oko pravca regresije
Slika 3.1-5 prikazuje normalne distribucije rezidualnih rezultata za
odgovarajuće vrijednosti u nezavisnoj varijabli oko pravca regresije.
Rezidualne vrijednosti dane su u mjernim jedinicama zavisne
varijable. Radi jednostavnije interpretacije, moguće je izračunati i
relativne rezidualne vrijednosti
(
e
)
y
i
’=b
0
+b
1
x
i
x
y
1
2
3
4
5
distribucije rezidualnih
vrijednosti
Multivarijatne metode – Regresijska analiza
192
100
y
'
y
y
e
i
i
i
i
Promatra li se odstupanja izmjerenih vrijednosti zavisne varijable od
aritmetičke sredine (slika 3.1-6), moguće je uočiti da je
)
'
(
)
'
(
)
(
i
i
i
i
y
y
y
y
y
y
gdje je
)
(
y
y
i
odstupanje izmjerenog rezultata entiteta
i
od aritmetičke
sredine
)
'
(
y
y
i
odstupanje prognoziranog rezultata entiteta
i
od aritmetičke
sredine
)
'
(
i
i
y
y
odstupanje izmjerenog rezultata entiteta
i
od
prognoziranog, odnosno rezidualna vrijednost.
Slika 3.1-6.
Odstupanje prognoziranog i rezidualnog rezultata u odnosu na odstupanje
izmjerenog rezultata od aritmetičke sredine
x
x
i
y
i
’=b
0
+b
1
x
i
(
y
i
-
y)
(y
i
’ -
y)
(y
i
- y
i
’)
(x
i
,y
i
)
x
y
y
y
i

Multivarijatne metode – Regresijska analiza
194
ss
ss
ss
ss
t
r
t
p
r
1
.
Kvadrat koeficijenta korelacije naziva se
koeficijent determinacije
i
predstavlja količinu varijabiliteta zavisne varijable koja je objašnjiva
nezavisnom varijablom. Koeficijent determinacije je mjera doprinosa
nezavisne varijable prognoziranju zavisne varijable, odnosno pokazuje
koliki je dio pogreške pri prognoziranju zavisne varijable reduciran
korištenjem nezavisne varijable.
Primjerice, slika 3.1-7 prikazuje slučaj kada se nezavisna varijabla
x
ne koristi za prognoziranje zavisne varijable
y
. U tom je slučaju
najbolja prognoza zavisne varijable njezina aritmetička sredina
y
(y’=
y)
. Tada je suma kvadrata rezidualnih odstupanja jednaka
totalnoj sumi kvadrata, a koeficijent determinacije jednak je nuli.
Slika 3.1-7.
Rezidualne vrijednosti kada se varijabla x ne koristi za prognozu
rezultata varijable y
Ako se na istom skupu podataka metodom najmanjih kvadrata
izračuna regresijski pravac (slika 3.1-8) tada je suma kvadrata
rezidualnih odstupanja manja od totalne sume kvadrata, a koeficijent
determinacije veći od nule.
x
n
i
i
y
y
1
2
)
'
(
=
n
i
i
y
y
1
2
)
(
y
Multivarijatne metode – Regresijska analiza
195
Slika 3.1-8.
Rezidualne vrijednosti kada se po modelu najmanjih kvadrata izračuna regresijski
pravac za prognozu rezultata varijable y na temelju rezultata varijable x
Stoga se koeficijent determinacije kreće od
0
do
1
. Jednak je nuli ako
je
r
ss
= t
ss
. To znači da na veličinu ukupnog varijabiliteta zavisne
varijable nezavisna varijabla nema nikakva utjecaja. Ako je
r
ss
= 0
koeficijent determinacije maksimalne vrijednosti (
1
), što znači da je
cjelokupan varijabilitet zavisne varijable moguće pripisati utjecaju
nezavisne varijable
,
odnosno rezultate u zavisnoj varijabli moguće je
točno predvidjeti preko rezultata nezavisne varijable.
Primjer:
Ispitanik
TT
prošao je 11-tjedni kineziološki tretman radi redukcije
potkožnog masnog tkiva i poboljšanja funkcionalnih sposobnosti. Nakon svakog
tjedna tretmana mjerena je
tjelesna težina
(
x
). Potrebno je utvrditi linearnu
funkcionalnu zavisnost između nezavisne varijable
x - broj tjedana kineziološkog
tretmana
i varijable
y - tjelesna težina
.
x
y
1
84,9
2
83,7
3
83,7
4
83,5
5
83,0
6
83,0
7
82,7
8
81,2
9
81,0
10
80,4
11
80,0
x
y
n
i
i
n
i
i
y
y
y
y
1
2
1
2
)
(
)
'
(

Multivarijatne metode – Regresijska analiza
197
Slika 3.1-10.
Regresijski pravac y
i
’=85,23-0,461x
i
dobiven prema modelu najmanjih kvadrata
Pomoću regresijskih koeficijenata izračunaju se prognozirani rezultati
i
i
0,461x
85,23
'
y
x
i
y
i
’=85,23
-0,461x
i
1
84,77
2
84,31
3
83,85
4
83,39
5
82,92
6
82,46
7
82,00
8
81,54
9
81,08
10
80,62
11
80,16
Multivarijatne metode – Regresijska analiza
198
Standardna pogreška prognoze i koeficijent korelacije izračunaju se
formulama
y
i
-y
i
’
(y
i
-y
i
’)
2
y
i
-
y
(y
i
-
y)
2
0,13
0,02
2,44
5,94
-0,61
0,37
1,24
1,53
-0,15
0,02
1,24
1,53
0,11
0,01
1,04
1,07
0,08
0,01
0,54
0,29
0,54
0,29
0,54
0,29
0,70
0,49
0,24
0,06
-0,34
0,12
-1,26
1,60
-0,08
0,01
-1,46
2,14
-0,22
0,05
-2,06
4,26
-0,16
0,03
-2,46
6,07
r
ss
=1,40
t
ss
=24,77

Multivarijatne metode – Regresijska analiza
200
y
=
X b
+
e
n
1
m
1
0
nm
1
n
m
1
11
n
1
e
.
.
e
b
.
b
b
x
.
.
x
1
.
.
.
.
.
.
.
.
.
.
x
.
.
x
1
y
.
.
y
,
gdje je
y
vektor rezultata
n
entiteta u zavisnoj varijabli
X
matrica (reda
n
x
m+1
) rezultata entiteta u
m
nezavisnih varijabli
b
vektor
m+1
regresijskih koeficijenata
e
vektor rezidualnih rezultata
n
entiteta.
Metodom najmanjih kvadrata izračunaju se regresijski koeficijenti
b
za jednadžbu
y
=
X b
uz uvjet da suma kvadrata rezidualnih vrijednosti, odnosno odstupanja
izmjerenih vrijednosti
y
i
od prognoziranih
y
i
’ bude minimalna.
Sustav normalnih jednadžbi
3
dobije se množenjem gornjeg izraza s
X
T
(
X
T
- transponirana matrica
X
)
X
T
y
=
X
T
X b
Ako dobiveni izraz pomnožimo inverzom matrice
X
T
X
, dobijemo
(X
T
X)
-1
X
T
y
=
(X
T
X)
-1
X
T
X b
.
Kako je
(X
T
X)
-1
X
T
X
=
I
, gdje je
I
- matrica identiteta, a množenje
bilo
koje
matrice
matricom
identiteta
ostavlja
matricu
nepromijenjenom (kao broj
1
u skalarnoj algebri), dobije se
(X
T
X)
-1
X
T
y
=
b
vektor
b
sa
m+1
regresijskih koeficijenata u kojemu
b
0
predstavlja
vrijednost zavisne varijable kada su vrijednosti nezavisnih varijabli
jednake nuli, a
3
Normalne jednadžbe su linearne po koeficijentima
b
0
,...,b
m
.
Multivarijatne metode – Regresijska analiza
201
b
j
(j = 1,…,m)
su regresijski koeficijenti koji predstavljaju veličine
promjena vrijednosti zavisne varijable za jedinični porast vrijednosti
nezavisne varijable
x
j
,
uz uvjet da su vrijednosti preostalih nezavisnih
varijabli konstantne; ako se vrijednost nezavisne varijable
x
j
poveća za
jedan (uz uvjet da se ne mijenjaju vrijednosti preostalih nezavisnih
varijabli), vrijednost zavisne varijable povećat će se u prosjeku za
vrijednost
b
j
.
Rezidualni vektor
e
dobije se oduzimanjem prognoziranih rezultata
entiteta od izmjerenih
e
=
y
-
y'
=
y
-
X b
.
Rezidualne vrijednosti dane su u mjernim jedinicama zavisne
varijable. Radi jednostavnije interpretacije moguće je izračunati i
relativne rezidualne vrijednosti
100
y
y
y
e
i
i
i
i
'
.
Standardna pogreška prognoze
(
e
), odnosno standardna devijacija
izmjerenih rezultata u odnosu na prognozirane je
1
m
n
)
'
y
(y
df
r
n
1
i
2
i
i
ss
e
2
Ako se rezultati dobiveni mjerenjem
n
entiteta u zavisnoj varijabli i
m
nezavisnih varijabli standardiziraju, odnosno transformiraju u
standardiziranu skalu s očekivanim vrijednostima
E(z
i
)=0
i
E(z
i
2
)=1
,
onda je
standardizirani
oblik linearne regresijske jednadžbe
k
=
1
Z
1
+
2
Z
2
+
…
+
m
Z
m
+
,
odnosno, u matričnom obliku
k
=
Z
+
n
m
nm
n
m
n
z
z
z
z
k
k
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
1
1
1
1
11
1
,

Multivarijatne metode – Regresijska analiza
203
Vektor rezidualnih vrijednosti
dobije se oduzimanjem vektora
standardiziranih prognoziranih rezultata
k’
od vektora standardiziranih
izmjerenih rezultata
k
=
k
-
k'
=
k
-
Z
Koeficijent determinacije multiple korelacije
izračunava se prema
formuli
2
=
T
r
,
odnosno
m
j
j
m
j
j
j
m
m
m
j
p
r
r
r
r
1
1
2
2
1
1
1
2
.....
,
pa je
multipla korelacija
jednaka
2
.
Multipla korelacija
predstavlja mjeru povezanosti skupa nezavisnih
varijabli i zavisne varijable. Ako je vrijednost multiple korelacije
jednaka nuli (
= 0
), tada skupom nezavisnih varijabli nije moguće
predviđati zavisnu varijablu. Ako je multipla korelacija maksimalne
vrijednosti (
= 1
), tada je cjelokupan varijabilitet zavisne varijable
moguće pripisati utjecaju nezavisnih varijabli
,
odnosno rezultate u
zavisnoj varijabli moguće je točno predvidjeti pomoću nezavisnih
varijabli. Dakle, multipla korelacija pokazuje kolika je vrijednost svih
nezavisnih varijabli u predviđanju (objašnjenju) neke zavisne
varijable.
Vrijednosti
p
j
predstavljaju varijabilitet zajednički pojedinoj
nezavisnoj varijabli i zavisnoj varijabli, odnosno predstavljaju
relativni udio svake nezavisne varijable u objašnjenom varijabilitetu
zavisne varijable. Suma svih
p
j
jednaka je
2
te se naziva
parcijalni
koeficijent determinacije
. Ako se
p
j
pomnoži sa
100
, dobije se
postotak zajedničke varijance pojedine nezavisne i zavisne varijable.
Analizom
parcijalnih koeficijenata determinacije
(
p
j
) moguće je
otkriti tzv.
supresore
. Primjerice, ako je
p
j
negativnog predznaka, a
pripadajući standardizirani regresijski koeficijent (
j
) ima visoku
vrijednost, onda je varijabla
j
supresor). Supresor je ona nezavisna
varijabla koja je u nultoj ili vrlo niskoj korelaciji sa zavisnom
varijablom, a ima visoku vrijednost standardiziranog regresijskog
koeficijenta (
j
).
Multivarijatne metode – Regresijska analiza
204
Za potpuniji uvid u mehanizme djelovanja čimbenika na istraživanu
pojavu moraju se izračunati još neki pokazatelji:
Ako iz inverza korelacijske matrice (
R
-
1
) izdvojimo recipročnu
vrijednost dijagonale. dobijemo matricu
S
2
1
)
(dijag
1
2
R
S
čije vrijednosti predstavljaju neobjašnjene dijelove varijance svake
nezavisne varijable u odnosu na ostale.
Operacijom
D
I
S
2
2
dobije se dijagonalna matrica
D
2
čiji elementi predstavljaju
koeficijente determinacije,
odnosno,
kvadrate multiplih korelacija
pojedine nezavisne varijable s ostalima (
I
je matrica identiteta reda
m
x
m; m
-broj nezavisnih varijabli). Ako je koeficijent determinacije
pojedine varijable (
d
j
2
) visok, to znači da ta varijabla ne može bitno
utjecati na prognozu zavisne varijable (povećanje multiple
korelacije) jer je veliki dio njezine varijance sadržan u ostalim
varijablama. Stoga valja zaključiti da nezavisne varijable trebaju
biti u međusobno što manjim korelacijama, ali istodobno u što
većoj korelaciji sa zavisnom varijablom.
Izuzetak od ovog pravila su supresorske varijable jer mogu
povećati multiplu korelaciju iako su u niskim korelacijama sa
zavisnom varijablom, a u visokim s nekom nezavisnom varijablom.
Supresorska varijabla povećava multiplu korelaciju jer prigušuje
(supresira) dio varijance koja nije povezana sa zavisnom
varijablom neke nezavisne varijable.
Korelacija između dviju varijabli iz koje je isključen utjecaj svih
ostalih varijabli zove se
parcijalna korelacija.
Operacijom
P
=
S R
-1
S
izračuna se matrica
P
koje su izvandijagonalni elementi parcijalne
korelacije. Ako su parcijalne korelacije niske, a korelacije visoke,
to znači da je međusobna povezanost dviju varijabli uzrokovana
utjecajem drugih.

Multivarijatne metode – Regresijska analiza
206
statistički značajna povezanost između skupa nezavisnih varijabli i
zavisne varijable uz pogrešku
p
(slika 3.1-9).
0
ρ
:
H
F
F
1
p
.
U tom slučaju testira se statistička značajnost utjecaja pojedine
nezavisne varijable.
Slika 3.1-9.
F – distribucija
Za testiranje značajnosti pojedinog regresijskog koeficijenta
b
j
postavljaju se hipoteze
0
b
:
H
0
b
:
H
j
1
j
0
.
Ako je vrijednost regresijskog koeficijenta populacije
B
j
jednaka nuli,
onda je područje prihvaćanja nulte hipoteze
j
b
p
σ
t
0
,
gdje je
t
p
kritična t-vrijednost
koja se dobije pomoću
t-distribucije
za
pogrešku
p
i broja stupnjeva slobode
df = n - m - 1
bj
standardna pogreška regresijskog koeficijenta
b
j
, odnosno
standardna devijacija regresijskih koeficijenata uzoraka
b
j
oko
vrijednosti regresijskog koeficijenta populacije
B
j
Područje prihvaćanja nulte hipoteze
H
0
:
= 0
; kad je
F < F
p
F
p
Područje prihvaćanja
alternativne hipoteze
H
1
:
0
; kad je
F > F
p
Multivarijatne metode – Regresijska analiza
207
Standardna pogreška regresijskog koeficijenta
b
j
izračuna se
formulom
jj
e
bj
w
,
gdje je
e
standardna pogreška prognoze, a
w
jj
(
j=1,...,m
;
m
-broj
nezavisnih varijabli) dijagonalni element matrice
(X
T
X)
-1
(matematički
dokaz u knjizi Ž. Pauše: Uvod u matematičku statistiku, str. 297-298).
Slika 3.1-10.
Distribucija slučajnog variranja regresijskog koeficijenta uzorka b
j
ako je
regresijski koeficijent populacije jednak nuli (B
j
= 0)
Ako se vrijednost regresijskog koeficijenta uzorka
b
j
kreće u intervalu
j
b
p
σ
t
0
(slika 3.1.10),
tada prihvaćamo nultu hipoteza (
H
0
). Ako je
regresijski koeficijent uzorka
b
j
izvan tog intervala, prihvaća se
alternativna hipoteza (
H
1
) uz pogrešku
p
te se zaključuje: regresijski
koeficijent je statistički značajan, odnosno vjerojatnost da je slučajno
različit od nule manja je od
p
.
Ako se regresijski koeficijent
b
j
podijeli standardnom pogreškom
bj
,
dobije se
t-vrijednost
j
b
j
b
t
Područje prihvaćanja hipoteze
H
0
: b
j
= 0
Područje prihvaćanja
hipoteze
H
1
: b
j
0
Područje prihvaćanja
hipoteze
H
1
: b
j
0
B
j
=
b
j
= 0
-t
p
bj
+t
p
bj
p/2
p/2

Multivarijatne metode – Regresijska analiza
209
Najčešće primjenjivan test za testiranje autokorelacija rezidualnih
odstupanja prvog reda je
Durbin-Watsonov test
(Durbin i Watson,
1951). Durbin-Watsonovim testom izračuna se veličina
d
koja
predstavlja omjer zbroja kvadrata prvih razlika rezidualnih odstupanja
i zbroja kvadrata rezidualnih odstupanja
n
1
1
2
i
n
2
i
2
1
i
i
e
)
e
e
(
d
.
Nulta
hipoteza
pretpostavlja
nepostojanje
autokorelacije,
a
alternativna postojanje autokorelacije (pozitivne ili negativne).
Hipoteze se testiraju na temelju rezultata testa
d
i kritične vrijednosti
d
L
i
d
U
, koje se odrede uz određenu razinu značajnosti i stupnjeve
slobode
df
1
=
n; n
-broj entiteta,
df
2
= m; m-
broj nezavisnih varijabli.
Ako je
d < d
L
, prihvaća se hipoteza o postojanju pozitivne autokorelacije
d > d
U
, prihvaća se nulta hipoteza o nepostojanju autokorelacije,
d
L
< d
<
d
U
, test ne dovodi do zaključka.
Negativna korelacija testira se na isti način, s time što se s kritičnim
vrijednostima
d
L
i
d
U
uspoređuje vrijednost (
4 - d
). Osim provjere
kvalitete modela pomoću
Durbin-Watsonova testa
, ispitivanje je
moguće i na temelju različitih vrsta rezidualnih odstupanja i raznih
vrsta grafikona rasipanja rezidualnih vrijednosti. Tim postupcima
moguće je identificirati ekstremne rezultate entiteta (
outlies
) koji
uvelike mogu utjecati na finalni rezultat. Stoga pojavu tih vrijednosti
treba objasniti, a nerijetko se može utvrditi da je riječ o pogrešnom
rezultatu entiteta u određenoj varijabli. Ti su postupci su sadržani u
svim poznatijim programskim paketima za statističko-grafičku obradu
podataka (primjerice,
STATISTICA
, SPSS, i dr).
Napomena:
Dodatne imformacije o gradivu iznesenom u ovom poglavlju mogu se pronaći u knjizi I. Šošić
(2004). Primjenjena statistika, poglavlje 13.7 Elementi regresijske dijagnostike (514-531).Zagreb:
Školska knjiga.
Multivarijatne metode – Regresijska analiza
210
3.1.5. Dekompozicija varijance jednog skupa
varijabli drugim skupom varijabli
Regresijska analiza može se koristiti i za dekompoziciju varijance
nekih varijabli, nakon čega se na dekomponiranim varijablama mogu
provoditi različite analize, zavisno od cilja istraživanja. Primjerice,
ako se želi parcijalizirati utjecaj jednog skupa varijabli na neki drugi
skup varijabli, onda je to moguće učiniti na način da se utvrde relacije
drugog skupa varijabli s varijablama prvog skupa te dekomponiraju
rezultati entiteta u prvom skupu varijabli na zavisni dio i dio koji je
nezavisan od drugog skupa varijabli. Dakle, svaki se rezultat nekog
entiteta u određenoj varijabli može dekomponirati na dio koji je
zavisan od nekog drugog skupa varijabli i dio koji predstavlja
vrijednost tog entiteta nezavisnu od tog skupa varijabli. Stoga se može
napisati da je
v
i
= v
i
(p)
+v
i
(r)
,
gdje je
v
i
rezultat entiteta
i
u varijabli
v
v
i
(p)
rezultat entiteta
i
u varijabli
v
koji zavisi od nekog drugog skupa
varijabli
v
i
(r)
rezultat entiteta
i
u varijabli
v
koji ne zavisi od nekog drugog
skupa varijabli.
Slika 3.1-11.
Rezultati n entiteta u dva skupa varijabli
gdje je
1,…,n
isti skup entiteta opisan prvim
(
1
v
1
,…,
1
v
m
)
i drugim
(
2
v
1
,…,
2
v
k
)
skupom varijabli.
Prvi skup varijabli
1
v
1
. . . . . . . . . .
1
v
j
. . . . . . . . . .
1
v
m
Drugi skup varijabli
2
v
1
. . . . . . . . .
2
v
f
. . . . . . . . . . .
2
v
k
1
.
.
.
.
i
.
.
.
.
.
.
n
1
.
.
.
.
i
.
.
.
.
.
.
n

Multivarijatne metode – Regresijska analiza
212
varijabla), uz pretpostavku da su entiteti izjednačeni po morfološkim
varijablama (drugi skup varijabli), onda je potrebno utvrditi utjecaj
morfoloških varijabli (drugi skup varijabli) na motoričke varijable
(prvi skup varijabli) te dekomponirati rezultate entiteta na dio zavisan
o skupu morfoloških varijabli i dio nezavisan od njih te nakon toga
utvrditi relacije između nezavisnog dijela rezultata entiteta u
motoričkim varijablama i uspjeha u nekom sportu. Dakle, utvrditi
utjecaj skupa motoričkih varijabli na uspjeh u određenom sportu
nakon parcijalizacije utjecaja morfoloških varijabli. Ovaj postupak
transformacije varijabli moguće je ubrzati primjenom algoritma za
dekompoziciju varijance jednog skupa varijabli drugim skupom
varijabli, utemeljenog na regresijskoj teoriji, a koje Momirović, Štalec
i Zakrajšek (1973) nazivaju
generalne image transformacije
.
Neka su
X
1
matrica podataka entiteta iz skupa
E={e
i
;i=1,…,n}
opisanih skupom kvantitativnih varijabli
V
1
={v
j
;j=1,…,m
1
}
, a
X
2
matrica podataka istih entiteta opisanih skupom kvantitativnih
varijabli
V
2
={v
f
;f=1,…,m
2
}
.
Centrirani podataci iz matrica
X
1
i
X
2
dobije se operacijom
X
c1
=
X
1
-
1m
1
T
X
c2
=
X
2
-
1m
2
T
,
gdje su
m
1
=
X
1
T
1
n
-1
i
m
2
=
X
2
T
1
n
-1
vektori aritmetičkih sredina prvog i
drugog skupa varijabli.
Matrice kovarijanci za varijable prvog i drugog skupa izračunaju se
operacijom
C
1
=
X
c1
T
X
c1
n
-1
C
2
=
X
c2
T
X
c2
n
-1
,
a matrica kroskovarijanci operacijom
C
21
=
X
c2
T
X
c1
n
-1
Prema kriteriju najmanjih kvadrata moguće je izračunati regresijske
koeficijente
B
1
=
C
2
-1
C
21
,
temeljem kojih je moguće izračunati varijable prvog skupa,
procijenjene prema modelu najmanjih kvadrata varijablama drugog
skupa
Multivarijatne metode – Regresijska analiza
213
X
1
’
=
X
c2
B
+
1m
1
T
te rezidualne (nezavisne) rezultate entiteta u varijablama prvog skupa
E
1
=
X
1
-
X
1
’
Isti postupak moguće je primijeniti i na standardiziranim podacima.
Taj postupak često se primjenjuje pri utvrđivanju efekata
primijenjenog eksperimentalnog tretmana. Naime, da bi se utvrdio
utjecaj nekog tretmana, najčešće se koristi eksperimentalni nacrt u
kojem jedna grupa nije podvrgnuta tretmanu (kontrolna grupa), a
druga mu se podvrgava (eksperimentalna grupa). Ako su kontrolna i
eksperimentalna grupa slučajno odabrane iz iste populacije, a to znači
da se ne razlikuju statistički značajno u inicijalnom stanju, onda se
značajnost promjena izazvanih primijenjenim tretmanom može
utvrđivati preko razlike vektora aritmetičkih sredina u finalnom
stanju. Međutim, ako se kontrolna i eksperimentalna grupa statistički
značajno razlikuju u inicijalnom stanju, onda navedeni postupak nije
opravdan. U tom slučaju potrebno je neutralizirati utjecaj razlika
kontrolne i eksperimentalne grupe u inicijalnom stanju na razlike u
finalnom stanju te nakon toga utvrđivati značajnost razlika vektora
aritmetičkih sredina u finalnom stanju. To se može spomenutim
postupkom i to tako da se varijable prvog mjerenja kontrolne i
eksperimentalne grupe promatraju kao prediktorski (nezavisni) skup, a
varijable koje opisuju stanje entiteta kontrolne i eksperimentalne
grupe u drugom mjerenju kao kriterijski (zavisni) skup. Time se
dobiju rezultati entiteta kontrolne i eksperimentalne grupe u drugom
mjerenju u promatranom skupu varijabli koji su nezavisni (rezidualni)
od varijabli prvog mjerenja. Na tako dobivenim rezidualnim
rezultatima moguće je utvrđivati značajnost promjena izazvanih
primijenjenim tretmanom preko razlika vektora aritmetičkih sredina
eksperimentalne i kontrolne grupe u finalnom stanju. Taj postupak
obično se naziva
analiza kovarijance
. U okviru analiza kovarijance
obično se izvodi univarijatna i multivarijatna analiza varijance ili pak
diskriminacijska analiza izvedena tako da se iz analiziranog skupa
varijabli parcijalizira utjecaj nekog drugog skupa varijabli koji ima
logički status smetnji (Momirović, Gredelj i Sirovicza, 1977).

Multivarijatne metode – Faktorska analiza
215
Louis Leon Thurstone
(1887. - 1955.),
znameniti američki psihometričar. Karijeru je
započeo kao inženjer elektrotehnike. Patentirao
je filmski projektor. Radio je kao asistent u
laboratoriju T. A. Edisona. Na Sveučilištu u
Chicagu diplomirao je i doktorirao psihologiju.
Znatno je pridonio razvoju teorije mjerenja, a
osobito razvoju faktorske analize. U radu
Multiple
factor analysis
, koji objavljuje 1931. godine u
časopisu
Psyshological Review
, postavlja
teoretski model grupnih faktora za čiju empirijsku
provjeru razvija multifaktorsku analizu. Osim toga uvodi i definira kriterije
za
jednostavnu strukturu faktora
, čime je usmjerio daljnji razvoj
faktorske analize.
Prema Kolesarić i Petz (1999).
Znanstveni članak C.E. Spearmana:
General Intelligence Objectively
Determined and
Measured
objavljen je u časopisu
American Journal of
Psychology
1904. godine.
z
j
=
a
j
g + s
j
,
gdje je
z
j
manifestna varijabla
j
a
j
koeficijent utjecaja
generalnog faktora
g
na
manifestnu varijablu
j
g
generalni faktor
s
j
faktor specifičan samo
za manifestnu varijablu
j
.
Za
empirijsku
provjeru
svog teoretskog koncepta
Spearman je razvio prvi
model faktorske analize
(Spearman, 1904).
Osim Spearmana, značajnu
ulogu u razvoju faktorske
analize imao je američki
psihometričar Louis Leon
Thurstone, koji je za svoju
teoriju o postojanju više
primarnih mentalnih spo-
sobnosti razvio
multifakt-
orsku analizu
(Thurstone,
1931). Danas je faktorska
analiza
1
zajedničko ime za
više metoda kojima je
zajednički cilj kondenzaci-
ja većeg broja
manifestnih
varijabli
, među kojima
postoji povezanost (korelacija), na manji broj
latentnih dimenzija ili
faktora. Manifestne varijable
dobivene su mjerenjem, dok
latentne
dimenzije
nisu izravno mjerljive postojećim mjernim instrumentima,
već se dobivaju linearnom kombinacijom manifestnih varijabli.
Primjerice, latentne dimenzije mogu biti motoričke sposobnosti
1
Za potpuniji uvid u različite modele faktorske analize potrebno je koristiti dodatnu literaturu, primjerice,
knjige: A. Fulgosi (1984). Faktorska analiza, Školska knjiga, Zagreb; N. Viskić-Štalec (1991). Elementi
faktorske analize, Fakultet za fizičku kulturu, Zagreb.
Multivarijatne metode – Faktorska analiza
216
Znanstveni članak L.L. Thurstonea:
Multiple factor analysis
,
objavljen je u časopisu
Psyshological Review
1931. godine.
(koordinacija, eksplozivna snaga,
fleksibilnost itd.) jer nisu izravno
mjerljive, a odgovorne su za
uspješnost u motoričkim aktivno-
stima (npr. skok udalj s mjesta,
trčanje 20 metara itd.), koje
predstavljaju manifestne varija-
ble. Stoga je osnovni cilj
faktorske analize otkriti potenci-
jalne uzroke povezanosti među
brojnim pojavama.
Kineziološke aktivnosti mogu se
smatrati posljedicama djelovanja
velikog broja faktora, odnosno
antropoloških karakteristika, koje
se aktiviraju u različitim omjer-
ima. Odnos između manifestnih
varijabli (npr. motoričkih aktivnosti) i faktora (npr. motoričkih
sposobnosti) može se izraziti u obliku jednadžbe
z
ij
= a
j1
f
i1
+ a
j2
f
i2
+…+ a
jk
f
ik
+ u
j
e
ij
,
gdje je
z
ij
rezultat ispitanika
i
u manifestnoj varijabli
j
(
j=1,…,m
) za koju
vrijedi
E(z
j
)=0; E(z
j
2
)=1
f
ip
rezultati ispitanika
i
u skupu zajedničkih faktora (
p=1,…,k; k<m
)
za koje vrijedi
E(f
p
) = 0
a
jp
koeficijenti utjecaja pojedinog faktora
f
p
na varijablu
j
(
p=1,…,k
)
e
ij
rezultat ispitanika
i
u rezidualnom faktoru
j
za koji vrijedi
E(e
j
)=0
u
j
koeficijent utjecaja rezidualnog faktora
e
j
.
U matričnom obliku
Z
=
F A
+
E U
mm
nm
n
n
m
m
km
k
k
m
m
nk
n
n
k
k
nm
n
n
m
m
u
u
u
e
e
e
e
e
e
e
e
e
a
a
a
a
a
a
a
a
a
f
f
f
f
f
f
f
f
f
z
z
z
z
z
z
z
z
z
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
22
11
2
1
2
22
21
1
12
11
2
1
2
22
21
1
12
11
2
1
2
22
21
1
12
11
2
1
2
22
21
1
12
11

Multivarijatne metode – Faktorska analiza
218
Moguće je razlikovati dva osnovna tipa primjene faktorske analize:
eksplorativna primjena
konfirmativna primjena.
Eksplorativnom primjenom
faktorske analize utvrđuju se faktori u
nekom prostoru manifestnih varijabli kada ni broj ni struktura faktora
nisu unaprijed poznati, dok
konfirmativna primjena
pretpostavlja
empirijsku provjeru nekog unaprijed postavljenog (hipotetskog)
modela o broju i strukturi faktora.
Kako je već rečeno, postoje brojni faktorski modeli, no moguće je
razlikovati dva osnovna modela faktorske analize:
faktorski model
i
komponentni model
. Prema Viskić-Štalec (1991) osnovna razlika
između ta dva modela jest u tome što komponentni model ne
diferencira zajedničku i uniknu varijancu prije kondenzacije varijabli
u komponente, odnosno faktorizacija se izvodi na nereduciranoj
matrici korelacija, dok faktorski model diferencira zajedničku
(komunalitet) i uniknu varijancu varijabli te faktorizaciju izvodi na
zajedničkom dijelu varijance varijabli. Osim toga, razlike mogu biti i
u inicijalnoj metrici varijabli, kriteriju za određivanje broja faktora,
tipu rotacije inicijalnog koordinatnog sustava koji osigurava
optimalnu parsimonijsku strukturu i način izračunavanja rezultata
entiteta na dobivenim faktorima (faktorski skorovi).
U daljnjem tekstu bit će predstavljena
metoda glavnih komponenata
ili
komponentni model
(engl.
principal components
) u realnoj metrici kao
jedan od osnovnih i najčešće korištenih modela eksplorativne
faktorske analize.
Napomena:
Opis i objašnjavanje svih modela faktorske analize nadilazi ambicije ove knjige, stoga se zahtjevniji
čitatelji upućuju na knjige:
A. Fulgosi (1984). Faktorska analiza. Zagreb: Školska knjiga.
N. Viskić-Štalec (1991). Elementi faktorske analize. Zagreb: Fakultet za fizičku kulturu.
ili na neku drugu knjigu koja detaljnije i sveobuhvatnije opisuje veći broj faktorski modela.
Multivarijatne metode – Faktorska analiza
219
Harold Hotelling
(1895. – 1973.), američki
ekonomist, matematičar i statističar. Kao
profesor na Columbia University uz nekoliko
vrlo zapaženih radova iz područja ekonomije
objavio je i veći broj značajnih radova iz
područja matematičke statistike. U članku
The
Generalization of Student's Ratio
, objavljenom
1931. godine u časoposu
Annals of
Mathematical Statistics,
generalizirao je
Studentov t - test za analizu više varijabli
(Hotellingov multivarijatni T
2
–test). Osobito je značajan njegov dopirnos
razvoju multivarijatnih analiza. U članku
Analysis of a Complex of
Statistical Variables into Principal Components,
objavljenom 1933.
godine u časopisu
Journal of Educational Psychology
, predložio je
komponentni model faktorske analize, a u članku
Relation Between Two
Sets of Variates
, objavljenom u znamenitom časopisu
Biometrika
1936.
godine, predlaže metodu za utvrđivanje relacija između dvaju skupova
varijabli (kanoničku analizu).
Znanstveni članak H. Hotellinga:
Analysis of a Complex of Statistical
Variables into Principal Components
objavljen je u časopisu
Journal of
Educational Psychology
1933. godine.
3.2.1. Komponentni model faktorske analize
Komponentni model fakt-
orske analize predložio je
Harold Hotelling 1933.
godine. Ovim modelom se
iz
skupa
manifestnih
varijabli utvrđuju linearno
nezavisne komponente na
temelju nereducirane kore-
lacijske matrice (u glavnoj
dijagonali su jedinice), što
omogućava
objašnjenje
ukupne varijance analizira-
nog
skupa
manifestnih
varijabli pomoću dobivenih
komponenata. Pri tome se
postiže da prva ekstrahira-
na komponenta objašnjava
maksimalno
moguć
dio
ukupne varijance, druga
maksimalno moguć dio
preostale
varijance
itd.
Takav postupak omoguća-
va da svaka sljedeća
komponenta
objašnjava
manju proporciju varijance
od prethodno ekstrahirane
komponente pa se minimal-
nim brojem komponenata
može objasniti maksimalna
količina ukupne varijance
manifestnih varijabli.
Neka su u matrici
B
podaci
skupa
E
= {e
i
;i = i,…,n}
entiteta koji su opisani
skupom
V = {v
j
;j = 1,…,m}
varijabli
B
=
(b
ij
)

Multivarijatne metode – Faktorska analiza
221
skupinu, a
v
4
,
v
5
i
v
6
čine drugu skupinu međusobno jače povezanih
varijabli. To upućuje na zaključak da kovariranje tog skupa
manifestnih varijabli dominantno određuju dva faktora. Komponentni
model faktorske analize rješava problem utvrđivanja faktora tzv.
spektralnom dekompozicijom korelacijske matrice
R
R
=
X
X
T
mm
m
m
m
m
m
mm
m
m
m
m
m2
m1
2m
21
1m
12
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
1
.
.
r
r
.
.
.
.
.
.
.
.
.
.
r
.
.
1
r
r
.
.
r
1
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2
1
2
22
12
1
21
11
2
1
2
1
2
22
21
1
12
11
koja se izvodi rješavanjem
karakteristične jednadžbe korelacijske
matrice
R
(
R
-
I
)
X
=
0
Rješavanjem karakteristične jednadžbe dobije se matrica svojstvenih
vektora
X
za koju vrijedi da je
X
T
X
=
X X
T
=
I
,
gdje je
I
matrica identiteta (matrica koje su dijagonalni elementi
jedinice, a izvandijagonalni nule) te dijagonalna matrica svojstvenih
vrijednosti
za čije dijagonalne elemente vrijedi
1
2
…
m
i
1
+
2
+ …+
m
= m
.
Postoji niz postupaka za utvrđivanje svojstvenih vrijednosti i
svojstvenih vektora. Primjerice,
Hotellingov iterativni postupak
,
Q-R
postupak dijagonalizacije
itd.
Napomena:
Detaljniji opis većeg broja postupaka za utvrđivanje svojstvenih vrijednosti i svojstvenih vektora
nalazi se u knjizi A. Fulgosi (1984). Faktorska analiza (str. 100-114). Zagreb: Školska knjiga.
Multivarijatne metode – Faktorska analiza
222
Varijable
matrice
standardiziranih
podataka
Z
moguće je
transformirati u glavne komponente
K
operacijom
K
=
Z X
mm
m
m
m
m
nm
n
n
m
m
nm
n
n
m
m
x
x
x
x
x
x
x
x
x
z
z
z
z
z
z
z
z
z
k
k
k
k
k
k
k
k
k
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2
1
2
22
21
1
12
11
2
1
2
22
21
1
12
11
2
1
2
22
21
1
12
11
pri čemu je varijanca glavne komponente
k
j
jednaka
j
(
j=1,...m
), a
kovarijance glavnih komponenata jednake su nuli.
Normiranjem glavnih komponenata
K
vrijednostima iz matrice
dobije se matrica standardiziranih glavnih komponenata
=
K
-1/2
=
Z X
-1/2
s varijancama jedan.
Dokaz:
Operacijom
K
T
K
n
-1
izračunava se matrica kovarijanci koje su dijagonalni
elementi varijance. Dakle,
K
T
K
n
-1
=
(Z X)
T
(Z X)
n
-1
=
X
T
Z
T
Z X
n
-1
=
X
T
R X
=
X
T
X
X
T
X
=
jer je
X
T
X = I
,
gdje je
I
matrica identiteta, a množenje bilo koje matrice matricom
identiteta ostavlja matricu nepromijenjenom. Dakle,
predstavlja dijagonalnu matricu
svojstvenih vrijednosti
j
u glavnoj dijagonali, koje su ujedno varijance glavnih
komponenata iz matrice
K
.
Time je dokazano da su vektori glavnih komponenata
k
j
ortogonalni i imaju varijance
j
.

Multivarijatne metode – Faktorska analiza
224
3.2.1.1. Kriteriji za odabir značajnog broja faktora
Već je rečeno da je cilj svake faktorske analize (pa i metode glavnih
komponenata) utvrditi manji broj faktora pomoću kojih je moguće što
bolje objasniti promatrani skup manifestnih varijabli. Broj
komponenata potrebnih za potpunu reprodukciju analiziranog skupa
manifestnih varijabli jednak je broju manifestnih varijabli sa
svojstvom
1
2
…
m
S obzirom na to da svaka sljedeća komponenta objašnjava sve manji
dio ukupne varijance, moguće je odabrati manji broj glavnih
komponenata koje objašnjavaju skup manifestnih varijabli. Zbog toga
je potrebno utvrditi kriterije za odabir manjeg broja glavnih
komponenata koje će bez većeg gubitka informacija dobro
reproducirati promatrani prostor manifestih varijabli. Postoji više
kriterija za odabir značajnog broja glavnih komponenata. U nastavku
će biti opisani samo najčešće korišteni kriteriji i oni koji su u većini
istraživanja
2
pokazali dobre karakteristike. To su
GK-kriterij
(Guttman i Kaiser),
PB-kriterij
(Štalec i Momirović, 1971) i
Scree-test
(Cattell, 1966).
GK-kriterij
Prema GK-kriteriju značajan broj glavnih komponenata određuje se
preko njihove varijance, odnosno preko svojstvenih vrijednosti
korelacijske matrice (
1,
2 ,
…,
m
). Značajnima se smatraju samo one
komponente čija je svojstvena vrijednost (varijanca) veća od ili je
jednaka jedan. Istraživanje Vesne Lužar pokazalo je da ovaj kriterij
daje maksimalan broj interpretabilnih komponenata te da se ne ponaša
konzistentno,
u svim slučajevima što često dovodi do
hiperfaktorizacije
3
(Lužar, 1976, prema Viskić-Štalec, 1991).
PB - kriterij
Pomoću ovog kriterija odabiru se glavne komponente dovoljne za
objašnjenje ukupne zajedničke varijance manifestnih varijabli. Pri
2
Jedno od istraživanja provela je V. Lužar (1976) koja je ispitivala osjetljivost različitih kriterija na tip,
distribuciju i varijancu pogreške, na temelju simulirajućeg eksperimenta.
3
daje više faktora nego ih stvarno postoji.
Multivarijatne metode – Faktorska analiza
225
Znanstveni članak J.Štaleca i K. Momirovića:
Ukupna količina valjane varijance kao osnov kriterija za određivanje broja
značajnih glavnih komponenata
objavljen je u prvom broja časopisa
KINEZIOLOGIJA
1971. godine.
tome je ukupna količina zajedničke varijance manifestnih varijabli
jednaka
)
(
2
U
I
trag
smc
,
gdje
smc
(kvadrat multiple korelacije) predstavlja zajednički dio
varijance svake varijable s preostalima iz promatranog skupa, odnosno
onaj dio ukupne varijance pojedine varijable koji je jednak
koeficijentu determinacije multiple korelacije pojedine varijable i svih
preostalih varijabli promatranog skupa,
I
matrica identiteta, a
U
2
matrica uniknih dijelova varijanci svake varijable koja se izračuna
operacijom
1
1
diag
)
(
2
R
U
Prema PB-kriteriju značajnim komponentama smatraju se one
komponente kojih je suma svojstvenih vrijednosti
j
, poredanih po
veličini, manja od
smc
. Autori smatraju da ovaj kriterij daje donju
granicu značajnih faktora te bolju interpretabilnost zadržanih
komponenata. U spomenutom istraživanju V. Lužar ističe da PB-
kriterij nije osjetljiv na tip distribucije rezultata entiteta u manifestnim
varijablama, veličinu i nenulte kovarijance varijabli pogrešaka, ali je
osjetljiv na singularne skupove varijabli u kojem slučaju

Multivarijatne metode – Faktorska analiza
227
3.2.1.2. Komunaliteti i unikviteti
Nakon odabira značajnog broja komponenata jednim od kriterija
dobije se reducirana matrica
H
sa
m
redaka (varijabli) i
k
stupaca
(komponenata), pri čemu je uvijek
k
m
. U daljnjem će se tekstu ta
matrica označavat također sa
H
.
mm
mk
1
m
m
1
k
1
1 1
h
.
.
.
h
.
.
h
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
h
.
.
.
h
.
.
h
H
Dakle, matrica
H
sadrži korelacije između
m
manifestnih varijabli i
k
značajnih glavnih komponenata. Kvadrirani elementi matrice
H
predstavljaju zajedničku varijancu svake manifestne varijable s
pojedinom glavnom komponentom. Stoga se operacijom
k
p
jk
j
j
jp
j
h
h
h
h
h
1
2
2
2
2
1
2
2
...
izračuna
komunalitet
manifestne varijable
j
. Komunaliteti predstav-
ljaju onaj dio ukupne varijance svake manifestne varijable koji je
moguće objasniti pomoću
k
značajnih komponenata, dok se ostali dio
varijance (dio koji nije moguće objasniti pomoću
k
značajnih
komponenata) naziva
unikvitet
(
u
j
2
), a izračuna se operacijom
2
j
2
j
h
1
u
,
jer je varijanca svake manifestne varijable jednaka jedan. Dakle,
varijancu svake manifestne varijable moguće je dekomponirati na
komunalitet
(
h
2
) i
unikvitet
(
u
2
).
1 = h
j
2
+ u
j
2
značajne glavne
komponente
glavne komponente
koje nisu značajne
Multivarijatne metode – Faktorska analiza
228
Korištenjem matrične algebre, operacijom
H
2
=
diag
(HH
T
)
dobije se dijagonalna matrica
komunaliteta
H
2
, a dijagonalna matrica
unikviteta
U
2
izračuna se operacijom
U
2
= I – H
2
3.1.2.3. Rotacije
Inicijalni koordinatni sustav, predstavljen matricom
H
, dobiven je
tako da prva glavna komponenta objasni najveći dio zajedničke
varijance analiziranog skupa manifestnih varijabli, druga, uz uvjet
ortogonalnosti, najviše preostale varijance itd. To znači da se prva
glavna komponenta ponaša kao generalni faktor promatranog prostora
manifestnih varijabli, dok ga druga obično diferencira u dvije grupe.
To pokazuje da, osim prve komponente koja se ponaša kao generalni
faktor, ostale komponente nije moguće smisleno interpretirati. Slika
3.2-2 prikazuje korelativne odnose između 6 manifestnih varijabli i
dviju značajnih glavnih komponenata.
Slika 3.2-3.
Geometrijski prikaz korelativnih odnosa 6 manifestnih varijabli i dviju značajnih
glavnih komponenata
Vidljivo je da je samo prvu glavnu komponentu moguće smisleno
interpretirati i to u slučajevima kada su sve manifestne varijable u
međusobno visokim korelacijama, a ostale glavne komponente nisu
značajne. Realnija i interpretabilnija solucija postiže se daljnjom
transformacijom inicijalnoga koordinatnog sustava u poziciju tzv.
jednostavne strukture
. Pojam jednostavne strukture potječe od
v
1
v
2
v
3
v
4
v
5
v
6
1
2

Multivarijatne metode – Faktorska analiza
230
S obzirom na to da je
T
ortonormirana matrica, komunaliteti varijabli
diag
(AA
T
)
=
diag
(HH
T
)
ne će se promijeniti.
Dakle, problem se svodi na izbor matrice
T
kojom će se transformirati
matrica
H
u matricu
A
. Matricu
T
moguće je odrediti uz definiranje
matematičkoga kriterija koji će osigurati dobivanje jednostavne
strukture (slika 3.2-4). Kriteriji za rotaciju su matematičke funkcije
kojima se maksimizira ili minimizira varijanca manifestnih varijabli i
faktora.
Slika 3.2-4.
Geometrijski prikaz korelativnih odnosa nekog skupa od 6 manifestnih varijabli i
dviju značajnih glavnih komponenata prije (
1
i
2
) i nakon ortogonalne rotacije (
1
i
2
)
Prema Fulgosiju (1984), najčešće korišten kriterij za ortogonalnu
rotaciju je
varimax
(Kaiser, 1958) kojim se maksimizira varijanca
faktora. Varijanca faktora
p
maksimizira se operacijom
Dokaz
:
AA
T
=
HT (HT)
T
=
H TT
T
H
T
=
HH
T
jer je
T
T
T
=
I
.
v
1
v
2
v
3
v
4
v
5
v
6
1
2
1
2
Multivarijatne metode – Faktorska analiza
231
2
m
1
j
2
m
1
j
2
jp
2
2
jp
p
m
a
a
m
v
,
gdje je
p=1,…,k
(
k -
broj značajnih
faktora)
j=1,…,m
(
m
- broj manife-
stnih varijabli).
Maksimiziranje svih faktora
postiže se maksimiziranjem
sume svih vrijednosti
v
p
k
1
p
p
v
v
,
Ovim postupkom se maksimi-
zira suma varijanci
k
stupaca
u matrici
A
.
mk
1
m
k
1
11
a
.
.
a
.
.
.
.
.
.
.
.
.
.
.
.
a
.
.
a
A
k
1
p
p
v
v
= v
1
. . . . . . . . v
k
2
m
1
j
2
m
1
j
2
1
j
2
2
1
j
1
m
a
a
m
v
Autor je primijetio da se tim postupkom ne postiže zadovoljavajuća
jednostavna struktura jer vrijednost
v
p
ovisi o komunalitetima varijabli
h
2
j
pa je i utjecaj određene manifestne varijable na dobivanje
jednostavne strukture zavisan od njezinog komunaliteta i to tako da

Multivarijatne metode – Faktorska analiza
233
Slika 3.2-5.
Geometrijski prikaz korelativnih odnosa nekog skupa od 6 manifestnih varijabli i
dviju značajnih glavnih komponenata prije (
1
i
2
) i nakon neortogonalne rotacije (
1
i
2
)
Matrica korelacija (
matrica strukture
) manifestnih varijabli i
transformiranih standardiziranih glavnih komponenata
F
dobije se
operacijom
F
=
Z
T
n
-1
,
odnosno,
F
=
H T
.
Matrica
A
(
matrica sklopa
), koja sadrži paralelne projekcije
(koordinate) manifestnih varijabli na transformirane komponente,
izračuna se operacijom
A
=
F M
-1
Isto tako je matricu strukture
F
moguće izračunati preko matrice
sklopa
A
i matrice korelacija između faktora
M
operacijom
1
2
v
1
v
2
v
3
2
1
v
4
v
5
v
6
Dokaz
:
F
=
Z
T
n
-1
=
Z
T
Z X
-1/2
T
n
-1
=
R X
-1/2
T
=
X
X
T
X
-1/2
T
=
X
1/2
T
=
H T
jer je
X
T
X
=
I
, a
-1/2
=
1/2
.
.
Multivarijatne metode – Faktorska analiza
234
F
=
A M
Transformacijsku matricu
T
za neortogonalnu rotaciju uz uvjet da je
diag
(T
T
T)=I
moguće je utvrditi pomoću Crawford-Fergusonove
funkcije (Crawford i Ferguson, 1970, prema Viskić-Štalec, 1991):
F
T
2
1
k
+
k
f(A)
= min
,
gdje
m
j
k
p
k
q
jq
jp
a
a
1
1
1
2
2
T
,
k
p
m
i
m
j
jq
ip
a
a
1
1
1
2
2
F
Izborom konstanti
k
1
i
k
2
moguće je definirati razne kriterije za
transformaciju:
k
1
= 1, k
2
= 0
-
oblimin,
k
1
= m –1 , k
2
= 1
-
kosokutni varimax,
k
1
= 2m – k, k
2
= k
-
kosokutni equamax,
k
1
= m –1, k
2
= k –1
-
obliparsimax,
k
1
= 0, k
2
= 1
-
obliparsifact
.
U tim transformacijama također je moguće primijeniti Kaiserov
postupak normalizacije.
Dakle, kao rezultat svake neortogonalne rotacije dobiju se tri matrice
rezultata:
A
- matrica koordinata ili paralelnih projekcija manifestnih varijabli
na transformirane faktore -
matrica sklopa
. Paralelne projekcije
predstavljaju vrijednosti koje odgovaraju udaljenosti od ishodišta do
mjesta koje se dobije povlačenjem paralela s faktorima do vrha
manifestne varijable (slika 3.2-6).
F
- matrica korelacija ili ortogonalnih projekcija manifestnih
varijabli na transformirane faktore -
matrica strukture
. Ortogonalne
projekcije predstavljaju vrijednosti koje odgovaraju udaljenosti od
ishodišta do točke dobivene povlačenjem okomica s vrha manifestne
varijable na faktore (slika 3.2-6).
M
- matrica korelacija između faktora.
p
q
i
j

Multivarijatne metode – Faktorska analiza
236
ortogonalne rotacije daju konačna rješenja, a neortogonalne ne zato
što:
…kod ortogonalnih solucija neophodno je da suma kvadrata faktorskih
opterećenja za svaku varijablu bude nakon rotacije jednaka sumi kvadrata
tih faktorskih opterećenja prije rotacije, dok kod kosokutnih rotacija toga
nema. To znači da nema tog ograničenja, pa je stoga moguće da suma
kvadrata faktorskih koeficijenata za istu varijablu bude različita nakon
rotacije od sume prije rotacije. Na taj način različiti kriteriji za jednostavnu
strukturu mogu kod kosokutnih transformacija dati različite solucije.
(Fulgosi, 1984: 224).
Nasuprot tome, Momirović ističe :
Iako su ortogonalni faktori znatno jednostavniji za statističke manipulacije,
takve su solucije u najvećem broju slučajeva artificijelne, jer je teško
zamisliti psihičke funkcionalne strukture, koje bi bile bez međusobnih
korelacija. Ortogonalni faktori mogu biti matematički, adekvatna solucija
problema predmeta mjerenja, ali takva solucija se rijetko kada dade
adekvatno psihologijski interpretirati. Osim toga sasvim precizno određenje
faktora nije moguće sa ortogonalnim strukturama. Zbog računskih razloga,
a i zbog toga što faktori, koji su u korelaciji, nameću pitanje faktora (obično
nazvanih drugog reda) koji su odgovorni za njihove korelacije, mnogi
faktoristi preferiraju ortogonalne solucije. Ali ako se faktori ne tretiraju kao
matematičke apstrakcije, već im se želi pridati psihološka egzistencija,
onda je nužno dopustiti da budu u bilo kakvim međusobnim korelacijama.”
(Momirović, 1966: 64.).
S kineziološkog stajališta, a na temelju mnogobrojnih dosadašnjih
istraživanja u kojima se utvrđivala latentna struktura antropoloških
karakterisika, moguće je zaključiti da su neortogonalne rotacije
prihvatljivije jer nije realno pretpostaviti da su sve antropološke
karakteristike
međusobno
nezavisne,
pa
se
ortogonalnim
transformacijama ne mogu dobiti realna rješenja. Osim toga, i
neortogonalnim rotacijama moguće je dobiti i ortogonalne faktore ako
analizirani podaci (manifestne varijable) to zahtijevaju. S obzirom na
to da se neortogonalnim rotacijama mogu dobiti faktori koji su
međusobno povezani, to omogućava “faktoriziranje” dobivenih
faktora i dobivanje faktora višeg reda koji su odgovorni za njihove
korelacije. Nameće se zaključak da, iako ne daju konačna rješenja te
su matematički i interpretativno složenije od ortogonalnih,
neortogonalnim rotacijama treba dati prednost jer ne podliježu
matematičkim restrikcijama (uvjet ortogonalnosti) pa omogućavaju,
za razliku od ortogonalnih, da se dobije jednostavnija struktura
faktora, a onda i realnija rješenja.
Multivarijatne metode – Faktorska analiza
237
3.2.1.4. Procjena rezultata entiteta u faktorima
Pomoću matrice paralelnih projekcija manifestnih varijabli na faktore
A
moguće je izračunati matricu standardiziranih regresijskih
koeficijenata manifestnih varijabli za procjenu rezultata entiteta u
faktorima. Matrica standardiziranih rezultata entiteta u skupu
manifestnih varijabli
Z
može se napisati kao produkt rezultata entiteta
u skupu faktora koji su odgovorni za kovariranje rezultata u
manifestnim varijablama
i matrice koeficijenata utjecaja svakog
pojedinog faktora na pojedinu manifestnu varijablu
A
Z
=
A
T
pa je po modelu najmanjih kvadrata moguće izračunati standardizirane
regresijske koeficijente manifestnih varijabli za procjenu rezultata
entiteta u faktorima
Z
=
A
T
/A
Z A
=
A
T
A
/
(
A
T
A
)
-1
ZA
(
A
T
A
)
-1
=
A
T
A
(
A
T
A
)
-1
S obzirom na to da je
A
T
A
(
A
T
A
)
-1
=
I
,
gdje je
I
matrica identiteta,
onda je
ZA(A
T
A)
-1
=
Dakle, standardizirani regresijski koeficijenti manifestnih varijabli za
procjenu rezultata entiteta u faktorima dobiju se operacijom
=
A(A
T
A)
-1
a rezultati entiteta u faktorima (
engl. factor scores
) operacijom
Z
=
.

Multivarijatne metode – Kanonička analiza
239
motorički status i skupa varijabli koje opisuju morfološki status
čovjeka ili pak skupa varijabli koje opisuju inicijalno i finalno stanje
treniranosti neke skupine entiteta itd. Dakle, kanonička analiza koristi
se u proučavanju odnosa između dvaju skupova varijabli.
Relacije između dvaju skupova varijabli utvrđuju se preko tzv.
parova
kanoničkih
faktora
koji
predstavljaju
linearne
kombinacije
(kompozite) varijabli jednoga i drugog skupa. Svaki par kanoničkih
faktora sastoji se od jednoga kanoničkog faktora iz prvoga i jednoga
kanoničkog faktora iz drugog skupa manifestnih varijabli. Pri tome je
prvi par kanoničkih faktora dobiven pod uvjetom da bude u najvećoj
mogućoj korelaciji. Za svaki sljedeći par kanoničkih faktora vrijedi
isto što i za prvi, ali pod uvjetom da ne smije biti u korelaciji ni s
jednim prethodno izvedenim parom kanoničkih faktora. Broj parova
kanoničkih faktora jednak je broju varijabli u manjem skupu varijabli.
Dakle, osnovni problem svodi se na pronalaženje odgovarajućih
koeficijenata (pondera) koji će osigurati najveću moguću korelaciju
između linearnih kompozita (kanoničkih faktora) koji pripadaju
dvama različitim skupovima varijabli.
Neka su
B
1
matrica podataka
n
entiteta opisanih s
k
, a
B
2
matrica
podataka
n
entiteta opisanih pomoću
m
kvantitativnih normalno
distribuiranih varijabli. Pri tome je
k > m
. Standardizacija podataka iz
matrica
B
1
i
B
2
dobije se kao
Z
1
=
B
c1
V
1
-1
Z
2
=
B
c2
V
2
-1
gdje su
B
c1
i
B
c2
matrice centrirani podataka, a
V
1
i
V
2
matrice
varijanci varijabli prvoga i drugog skupa.
Korelacijske matrice varijabli prvoga i drugog skupa su
R
11
=
Z
1
T
Z
1
n
-1
R
22
=
Z
2
T
Z
2
n
-1
,
a matrice kroskorelacija
R
12
=
Z
1
T
Z
2
n
-1
R
21
=
Z
2
T
Z
1
n
-1
,
pri čemu je
R
12
= R
21
T
, a R
21
=
R
12
T
.
Multivarijatne metode – Kanonička analiza
240
Potrebno je početne (manifestne) varijable transformirati u linearne
kompozite
1
=
Z
1
X
1
2
=
Z
2
X
2
za koje vrijede uvjeti
1
T
2
n
-1
=
R
c
i
1
T
1
n
-1
=
I
2
T
2
n
-1
=
I
,
gdje je
R
c
dijagonalna matrica maksimalno mogućih korelacija između
faktora koji čine par (za koje vrijedi
r
c1
r
c2
,…,r
cm
;
m
- broj varijabli u
manjem skupu) koje se zovu
kanoničke korelacije
, a istovremeno su
faktori izvan para međusobno ortogonalni, a
I
matrica identiteta, što
znači da su faktori unutar svakog skupa varijabli međusobno
ortogonalni.
Rješenje ovako postavljenog problema Hotelling (1936) svodi na
rješavanje skupa karakterističnih jednadžbi
(R
22
-1
R
21
R
11
-1
R
12
-
I ) X
2
= 0
,
uz uvjet da je
X
2
T
R
22
X
2
=
I
, gdje je
dijagonalna matrica svojstvenih
vrijednosti matrice, a
X
2
matrica desnih svojstvenih vektora matrice
(
R
22
-1
R
21
R
11
-1
R
12
).
Matrica svojstvenih vrijednosti
predstavlja kvadrate kanoničkih
korelacija (koeficijente determinacije kanoničkih korelacija, odnosno
proporcije zajedničke varijance dvaju kanoničkih faktora koji
pripadaju istom paru) pa je dijagonalna matrica kanoničkih korelacija
R
c
(za koje vrijedi
r
c1
r
c2
…
) jednaka
R
c
=
1/2
,
odnosno
R
c
=
1
T
2
n
-1
.
Dakle, svojstvene vrijednosti
predstavljaju proporciju zajedničke
varijance dvaju pripadajućih kanoničkih faktora. One ne govore o
količini varijance koju je objasnio neki kanonički faktor u bilo kojem

Multivarijatne metode – Kanonička analiza
242
Isto tako, moguće je izračunati i matrice kroskorelacija između
početnih varijabli jednog skupa s kanoničkim faktorima drugog skupa
F
12
=
Z
1
T
2
n
-1
F
21
=
Z
2
T
1
n
-1
=
Z
1
T
Z
2
X
2
n
-1
=
Z
2
T
Z
1
X
1
n
-1
=
R
12
X
2
=
R
21
X
1
Ako se suma kvadriranih korelacija u matricama
F
12
i
F
21
za svaki
kanonički faktor podijeli brojem manifestnih varijabli prvog
m
1
,
odnosno drugog
m
2
skupa, dobije se proporcija varijance svakog
faktora iz prvog skupa s varijablama iz drugog skupa, odnosno svakog
faktora iz drugog skupa s varijablama iz prvog skupa, a naziva se
redundancija
(
engl. redundancy
). Dakle, redundancija se interpretira
kao proporcija varijance prvog skupa varijabli koja se može objasniti
kanoničkim faktorima drugog skupa varijabli i obrnuto. Suma
redundantnih varijanci (od svakog kanoničkog faktora) daje podatak o
ukupnoj redundantnoj varijanci, odnosno o veličini varijance prvog
skupa varijabli koju je moguće procijeniti drugim skupom varijabli i
obrnuto. Zato se može koristiti kao pokazatelj moguće procjene
(rekonstrukcije) jednog skupa varijabli na temelju drugog skupa
varijabli.
Kanoničku analizu moguće je izvesti i pomoću glavnih komponenata
dobivenih faktorizacijom varijabli iz matrica
Z
1
i
Z
2
(Fulgosi, 1984;
Momirović, 1984).
Ako se spektralnom dekompozicijom korelacijskih matrica (v.
poglavlje 3.2, str. 219-223) prvoga i drugog skupa varijabli
R
11
=
X
1
1
X
1
T
R
22
=
X
2
2
X
2
T
dobiju matrice svojstvenih vektora
X
1
i
X
2
,
za koje vrijedi da je
X
1
T
X
1
=
I
i
X
2
T
X
2
=
I
s pripadajućim matricama svojstvenih vrijednosti
1
i
2
, onda je standardizirane glavne komponente prvog i drugog
skupa varijabli moguće dobiti operacijom
1
=
Z
1
X
1
1
-1/2
2
=
Z
2
X
2
2
-1/2
.
Operacijom
Q
=
2
T
1
n
-1
Multivarijatne metode – Kanonička analiza
243
izračuna se matrica kroskorelacija glavnih komponenata prvoga i
drugog skupa. Problem određivanja kanoničkih korelacija svodi se na
spektralnu dekompoziciju matrice
Q
T
Q
Q
T
Q = Y
2
Y
2
T
,
gdje je
Y
2
matrica svojstvenih vektora za koju vrijedi da je
Y
2
T
Y
2
=
I
dijagonalna matrica svojstvenih vrijednosti koje predstavljaju
kvadrate kanoničkih korelacija između ortogonalno transformiranih
glavnih komponenata prvoga i drugog skupa.
Dijagonalna matrica kanoničkih korelacija
R
c
(za koje vrijedi
r
c1
r
c2
,…,r
cm
) jednaka je
R
c
=
½
.
Koeficijenti za transformaciju standardiziranih glavnih komponenata
prvog skupa u kanoničke faktore dobiju se operacijom
Y
1
= QY
2
-½
.
Matrice
Y
1
i
Y
2
sadrže koeficijente kojima je moguće transformirati
standardizirane glavne komponente prvog i drugog skupa u kanoničke
faktore operacijom
1
=
1
Y
1
2
=
2
Y
2
.
Matrice korelacija između početnih varijabli i dobivenih kanoničkih
faktora (
F
1
i
F
2
) izračunaju se operacijama
F
1
=
Z
1
T
1
n
-1
F
2
=
Z
2
T
2
n
-1
,
a operacijom
F
12
=
Z
1
T
2
n
-1
F
21
=
Z
2
T
1
n
-1
izračunju se matrice kroskorelacija između manifestnih varijabli
jednog skupa i kanoničkih faktora drugog skupa.

Multivarijatne metode – Diskriminacijaka analiza
245
3.4
Diskriminacijska
analiza
Statistička značajnost razlika između dviju ili više grupa u jednoj ili
više varijabli vrlo se često utvrđuje u antropološkim istraživanjima.
Analize koje se koriste u tu svrhu moguće je razlikovati prema broju
grupa entiteta i broju varijabli:
t - test
se koristi za utvrđivanje statističke značajnosti razlika između
aritmetičkih sredina dviju nezavisnih grupa (različitih) ispitanika i
dviju zavisnih grupa (ista grupa ispitanika izmjerena istim testom u
dva mjerenja) te razlika aritmetičke sredine grupe i neke poznate
aritmetičke sredine ili populacijske aritmetičke sredine;
univarijatna analiza varijance
(
ANOVA
) koristi se za utvrđivanje
statističke značajnosti razlike dviju ili više grupa entiteta u jednoj
varijabli;
multivarijatna analiza varijance
(
MANOVA
) koristi se za
utvrđivanje statističke značajnosti razlika dviju ili više grupa
entiteta mjerenih u dvije ili više varijabli;
Multivarijatne metode – Diskriminacijaka analiza
246
diskriminacijska analiza
koristi se za utvrđivanje statističke
značajnosti razlika više grupa entiteta mjerenih u više varijabli, pri
čemu se utvrđuje koliko se grupe međusobno razlikuju i koliko
pojedine varijable pridonose toj razlici, a moguće je i prognozirati
pripadnost pojedinog entiteta grupi.
Prve dvije metode ubrajaju se u grupu
univarijatnih
, a druge dvije u
grupu
multivarijatnih metoda
1
.
3.4.1. Multivarijatna analiza varijance
Multivarijatna analiza varijance
koristi se za utvrđivanje statističke
značajnosti razlika dviju ili više grupa entiteta opisanih pomoću dvije
ili više varijabli. Univarijatna i multivarijatna analiza varijance
počivaju na istim logičkim načelima. Kako je već istaknuto (v.
poglavlje 2. 10, str. 150-159), položaj bilo kojeg entiteta može se
izraziti u obliku jednadžbe
)
x
x
(
)
x
x
(
)
x
x
(
g
g
gi
gi
,
gdje je
x
gi
rezultat entiteta
i
iz grupe
g
(
g=1,…,k
;
k-
broj grupa)
x
zajednička aritmetička sredina
x
g
aritmetička sredina grupe kojoj entitet pripada.
Isto vrijedi i za multivarijatnu analizu varijance, s tom razlikom što je
svaki entitet opisan pomoću više varijabli
)
(
)
(
)
(
g
g
gi
gi
m
m
m
x
m
x
,
gdje je
x
gi
vektor rezultata entiteta
i
iz grupe
g
(
g=1,…,k
;
k-
broj grupa) u
analiziranim varijablama
m
vektor aritmetičkih sredina u analiziranim varijablama za sve
grupe
m
g
vektor aritmetičkih sredina u analiziranim varijablama za grupu
kojoj entitet pripada.
1
Univarijatne metode analiziraju jednu varijablu, a multivarijatne više varijabli istovremeno.

Multivarijatne metode – Diskriminacijaka analiza
248
b
gi
vektor rezultata entiteta
i
iz grupe
g
u analiziranom skupu
varijabli
m
vektor aritmetičkih sredina za sve entitete,
dobije se
matrica suma kvadrata i kros produkata za total
.
Ako se matrica
T
podijeli brojem entiteta, dobije se
matrica
kovarijanci za total
.
C
=
D
T
D
n
-1
Isto se tako operacijom
m
g
=
B
g
T
1
g
n
g
-1
,
gdje je
g = 1,…,k
, a
1
g
vektor stupca sa
n
g
jedinica, izračuna
k
vektora
aritmetičkih sredina varijabli gdje se u obzir uzimaju samo entiteti iz
pojedine grupe (
n
g
).
Matrice odstupanja rezultata entiteta od centroida svake grupe
D
g
(odstupanja unutar grupa) dobiju se operacijom
D
g
=
B
g
-
1
g
m
g
T
,
a operacijom
W
g
=
D
g
T
D
g
matrice suma kvadrata i krosprodukata za svaku grupu
.
Sumacijom svih dobivenih matrica dobije se
matrica suma kvadrata i
krosprodukata unutar grupa
W
W
g
g
k
1
ili
T
g
g
g
g
m
b
m
b
W
i
i
)
)(
k
n
g
1
g
1
i
(
,
gdje je
k
broj grupa
n
g
broj entiteta u grupi
g
b
gi
vektor rezultata entiteta
i
iz grupe
g
u analiziranom skupu
varijabli
m
g
vektor aritmetičkih sredina za grupu
g
(kojoj entitet pripada).
Multivarijatne metode – Diskriminacijaka analiza
249
S obzirom na to da je
T
=
W
+
A
,
matrica suma kvadrata i krosprodukata između grupa
izračuna se
oduzimanjem matrica
T
i
W
A
=
T
-
W
ili
T
g
k
g
g
g
T
g
k
g
n
i
g
n
g
)
)(
(
)
)(
(
1
1
1
m
m
m
m
m
m
m
m
A
,
gdje je
k
broj grupa
n
g
broj entiteta u grupi
g
m
g
vektor aritmetičkih sredina za grupu
g
(kojoj entitet pripada)
m
vektor aritmetičkih sredina za sve entitete.
Statistička značajnost razlike između centroida grupa testira se
Willksovim testom, odnosno tzv.
Willksovom lambdom
)
det(
)
det(
T
W
w
.
Formula pokazuje da smanjenje odnosa između determinanti matrice
W
i
T
(ako se determinanta matrice
T
povećava u odnosu na
determinantu matrice
W
) prati povećanje vjerojatnosti s kojom se
odbacuje nulta hipoteza. Drugim riječima, ako se kovariranje unutar
grupa povećava u odnosu na totalno kovariranje, smanjuje se
vjerojatnost za statistički značajne razlike. Zbog vrlo složene
distribucije Wilksove lambde (
w
), izračunava se tzv.
aproksimativna
F-vrijednost
koja ima
F-distribuciju
(Rao, 1951,1952, prema
Momirović, Gredelj i Sirovicza,1977):
1
2
1/S
w
1/S
w
df
df
λ
λ
1
F
gdje je
5
1
k
m
4
1
k
m
s
2
2
2
2
,

Multivarijatne metode – Diskriminacijaka analiza
251
koja ima F-distribuciju sa stupnjevima slobode
df
1
= m
i
df
2
= (n
1
+ n
2
- m - 1),
pomoću koje je moguće testirati statističku značajnost razlika tih dviju
grupa.
3.4.2. Diskriminacijska analiza
Diskriminacijska analiza
je superiorna u odnosu na multivarijatnu
analizu varijance jer se njome dobiju informacije o tome koliko se
grupe međusobno razlikuju (položaji centroida grupa u prostoru
diskriminacijskih funkcija) i koliko pojedine varijable pridonose toj
razlici (matrica korelacija varijabli s diskriminacijskim funkcijama), a
moguće je i prognozirati pripadnost pojedinog entiteta grupi. Osnovni
zahtjevi od kojih se polazi u diskriminacijskoj analizi jesu
konstruiranje manjeg broja latentnih varijabli (koje se dobiju kao
linearne kombinacije originalnih varijabli, a zovu se diskriminacijske
funkcije) na temelju kojih je moguće najbolje opisati razlike među
analiziranim grupama. To je moguće ostvariti maksimiziranjem izraza
T
j
T
j
T
j
T
j
Wx
x
Ax
x
j
λ
,
odnosno, problem se može svesti na rješavanje
karakteristične
jednadžbe
(
W
-1
A
-
j
I
)
x
j
= 0
,
uz uvjet
j
=
max
i
x
T
j
x
j
=1
,
gdje je
W
matrica suma kvadrata i krosprodukata unutar grupa,
A
suma kvadrata i krosprodukata između grupa (v. prethodno poglavlje),
a
j=1,...,k-1
(
k -
broj grupa) označava svojstvene vrijednosti (
j
) i
njima pripadajuće svojstvene vektore (
x
j
) matrice
W
-1
A
.
Potrebno napomenuti da se svojstvenih vrijednosti i svojstvenih
vektora dobije onoliko koliko je grupa manje jedan ili ako je broj
varijabli manji od broja grupa, onda onoliko koliko je varijabli.
Multivarijatne metode – Diskriminacijaka analiza
252
Neka je skup od
n
entiteta, svrstanih u
k
grupa, opisan pomoću
m
kvantitativnih normalno distribuiranih varijabli. Za svaku grupu
formira se matrica podataka
B
g
= (b
fj
)
,
gdje je
g = 1,…,k
(
k
broj grupa),
f = 1,…,n
g
(
n
g
broj entiteta u grupi
g
),
j = 1,…,m
(
m
broj varijabli), a od svih matrica
B
g
formira se matrica
B
tako da se matrice
B
g
slože jedna ispod druge
B
= (b
ij
)
.
Matrica centriranih rezultata, odnosno odstupanja rezultata entiteta od
zajedničkog centroida dobije se operacijom
D
=
B
-
1m
T
,
gdje je
m
=
B
T
1
n
-1
vektor aritmetičkih sredina, a
1
vektor stupca sa
n
jedinica. Operacijom
=
D
X
1
mk
m1
1
1k
11
nm
n1
1m
11
1
nk
n1
1
1k
11
x
.
.
x
.
.
.
.
.
.
.
.
x
.
.
x
d
.
.
d
.
.
.
.
.
.
.
.
d
.
.
d
ψ
.
.
ψ
.
.
.
.
.
.
.
.
ψ
.
.
ψ
centrirani se rezultati entiteta iz matrice
D
transformiraju u tzv.
diskriminacijske
funkcije
.
Dijagonalna
matrica
varijanci
diskriminacijskih funkcija dobije se operacijom
=
T
n
-1
=
(
DX
)
T
D X
n
-1
=
X
T
D
T
D X
n
-1
=
X
T
C X
.
Normiranjem diskriminacijskih funkcija
vrijednostima iz matrice
dobije se matrica standardiziranih diskriminacijskih funkcija
=
-1/2
=
D X
-1/2
s varijancama jedan.

Multivarijatne metode – Diskriminacijaka analiza
254
F
=
R
1
mk
m1
1
1k
11
m1
12
1m
21
1
mk
m1
1
1k
11
β
.
.
β
.
.
.
.
.
.
.
.
β
.
.
β
1
.
.
r
.
1
.
.
.
.
1
r
r
.
r
1
f
.
.
f
.
.
.
.
.
.
.
.
f
.
.
f
Korelacije između početnih (originalnih) i diskriminacijskih funkcija
određuju strukturu, odnosno njihov sadržaj. Diskriminacijske funkcije
dobivene su kao linearne kombinacije analiziranih varijabli i to tako
da maksimalno razlikuju centroide grupa. Stoga se logično nameće
pitanje o prirodi njihovih relacija s onim iz čega su nastale.
Analizirane
varijable
nemaju
jednak
doprinos
formiranju
diskriminacijskih funkcija. Stoga korelacije analiziranih varijabli i
diskriminacijskih funkcija predstavljaju relativan doprinos, odnosno
proporcionalne
su
važnosti
svake
varijable
u
formiranju
diskriminacijskih funkcija, a time i razlikovanju analiziranih grupa.
Ako se od vektora aritmetičkih sredina svake pojedine grupe
(centroida grupa)
m
g
=
Z
g
T
1
g
n
g
-1
formira matrica centorida grupa (centroide grupa poredamo jedan do
drugoga tako da su u recima varijable, a u stupcima grupe), dobije se
matrica
M
, pomoću koje se operacijom
Dokaz:
F
=
Z
T
n
-1
=
Z
T
Z
n
-1
=
R
jer je
Z
T
Z
n
-1
=
R
matrica korelacija između početnih varijabli.
Multivarijatne metode – Diskriminacijaka analiza
255
=
T
M
mk
m1
1k
11
1m
-
k
11
-
k
1m
11
1k
-
k
1
-
k
1k
11
m
.
.
m
.
.
.
.
.
.
.
.
m
.
.
m
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
dobije matrica centroida grupa u prostoru standardiziranih
diskriminacijskih funkcija (slika 3.4-1).
Slika 3.4-1.
Koordinate centroida triju grupa u koordinatnom sustavu dviju
diskriminacijskih funkcija
Centroidi su aritmetičke sredine analiziranih grupa ispitanika u
koordinatnom sustavu diskriminacijskih funkcija te imaju važnu ulogu
pri interpretaciji rezultata diskriminacijske analize. Oni pokazuju
koliko se grupe međusobno razlikuju po svakoj diskriminacijskoj
funkciji. Tako, primjerice, na temelju slike 3.4-1, koja prikazuje
centroide triju grupa u koordinatnom sustavu dviju diskriminacijskih
funkcija, moguće je uočiti da se prva grupa znatno razlikuje od druge i
treće po prvoj diskriminacijskoj funkciji, dok druga diskriminacijaka
funkcija u velikoj mjeri razlikuje treću grupu u odnosu na prvu i
drugu, koje su po drugoj diskriminacijskoj funkciji vrlo slične.
Koeficijenti kanoničke diskriminacije
za svaku diskriminacijsku
varijablu izračunaju se operacijom
1
2
1
2
3

Multivarijatne metode – Diskriminacijaka analiza
257
k
broj grupa
q
broj diskriminacijskih funkcija kojih je
m
ili
k-1
, ovisno o tome
čega je manje
p
broj prethodno testiranih diskriminacijskih funkcija
j
svojstvene vrijednosti matrice
W
-1
A
.
Izračunate
2
-vrijednosti
imaju približno
2
-distribuciju
(tablica
D
str.
322) s brojem stupnjeva slobode
df = (m-p)(k-p-1).
Multivarijatne metode – Diskriminacijaka analiza
258

Kineziometrija – Osnovni kineziometrijski pojmovi
260
4.1
Osnovni
kineziometrijski
pojmovi
Kineziometrija
(grč.
kinezis
- kretanje,
metron -
mjera) je znanstvena
disciplina koja se bavi problemima mjerenja u kineziologiji.
Kineziologija je znanost čiji je cilj utvrditi zakonitosti upravljanog
procesa vježbanja i posljedice tih procesa na čovjekov organizam, a
predmet istraživanja, sažeto rečeno, utvrđivanje ciljeva nekog procesa
vježbanja, utvrđivanje stanja subjekta u relaciji s postavljenim
ciljevima te planiranje, programiranje, provođenje i kontrola procesa
vježbanja (Mraković, 1992). Za znanstveno istraživanje navedenih
problema, a to znači za utvrđivanje zakonitosti po kojima se odvija
neki trenažni proces, potrebno je imati odgovarajuće postupke koji
omogućavaju prikupljanje relevantnih podataka o stanju subjekta.
Upravo se tim problemima bavi kineziometrija; dakle, problemima
mjerenja, odnosno, konstrukcije i validacije mjernih instrumenata za
procjenu kinezioloških fenomena.
Kineziometrija – Osnovni kineziometrijski pojmovi
261
4.1.1. Mjerenje
Postoji puno različitih definicija mjerenja. Tako, primjerice, Guilford
(1968) mjerenjem smatra pridodavanje brojeva predmetima i
događajima u skladu s pravilima koja su logički ispravna. Nunnally
(1967) mjerenje definira kao skup pravila za pridruživanje brojeva
objektima da bi se predstavili kvantiteti atributa. Momirović (1988,
prema Momirović i sur., 1999) smatra mjerenje operacijom kojom se,
u skladu s nekim potpunim i točnim skupom pravila, omogućava
pridruživanje oznake ili broja koji se odnosi na neko određeno
svojstvo tako da se bilo koja dva objekta koja se po mjerenom
svojstvu razlikuju mogu razlikovati i bilo koja dva objekta koja su po
tom svojstvu identična, mogu smatrati identičnima. Viskić-Štalec
(1997) mjerenje definira kao operaciju kojom se nekom objektu
pridružuje oznaka ili numerička vrijednost koja odgovara razvijenosti
mjerene karakteristike, odnosno to je određivanje pozicije subjekta ili
objekta na nekoj od mjernih ljestvica. Prema navedenim definicijama
vidljivo je da je mjerenje postupak kojim se objektima (entitetima,
ispitanicima) pridružuju brojevi ili oznake prema određenim pravilima
u skladu s razvijenosti mjerenog svojstva (aributa, karakteristike,
obilježja) čime se postiže njegova kvantifikacija ili klasifikacija.
Moguće je razlikovati dvije vrste mjerenja. To su
direktno
(izravno,
neposredno) i
indirektno
(neizravno, posredno). U direktnom mjerenju
predmet mjerenja i mjerna jedinica imaju ista svojstva. Primjerice,
mjerenje prostornih obilježja (širina, dužina, visina) i mase nekog
objekta. Mjeri se uspoređivanjem mjerenog svojstva s određenom
veličinom tog istog svojstva koja se dogovorom odredi kao jedinica
mjere (npr. metar, milja, kilogram i sl.). Dakle, ako se masa nekog
tijela odredi kao mjerna jedinica, onda se njome može odrediti masa
bilo kojeg objekta. Za razliku od direktnog, u indirektnom mjerenju
predmet mjerenja i mjerna jedinica nemaju ista svojstva. Primjerice,
pri mjerenju elekričnog napona, temperature nekog objekta itd.
Veličina električnog napona mjeri se veličinom otklona kazaljke na
voltmetru, a temperatura nekog objekta mjeri se visinom stupca žive u
termometru. Dakle, veličina predmeta mjerenja određuje se pomoću
njegova utjecaja na druge objekte koji mijenja njihova svojstva, pa je
na temelju izazvanih promjenama moguće odrediti veličinu mjerenog
svojstva ako između predmeta mjerenja i izazvanih promjena postoji
neka stalna veza (relacija, odnos). Upravo takva mjerenja, dakle,
indirektna, susreću se u kineziologiji, ali i u ostalim antropološkim

Kineziometrija – Osnovni kineziometrijski pojmovi
263
4.1.2.3. Mjerilac
Mjerilac je osoba koja provodi mjerenje. S obzirom na to da je u sva
mjerenja u manjoj ili većoj mjeri uključen čovjek, pitanje je koliko su
dobiveni razultati mjerenja pod njegovim utjecajem, odnosno da li su
oni od njega nezavisni. Naime, svakim se mjerenjem teži objektivnosti
i nastoji se isključiti utjecaj mjerioca na rezultate mjerenja. Neki
mjerni instrument smatra se objektivnim ako različiti mjerioci, mjereći
iste ispitanike, dolaze do jednakih rezultata, a to se postiže
standardiziranim postupkom mjerenja. Problem objektivnosti mjerenja
posebno će se razmatrati u poglavlju 4.3. Metrijske karakteristike (str.
272-312).
4.1.2.4. Mjerne skale
Uspješnost mjerenja ovisi o stupnju podudarnosti između brojeva i
mjerenih svojstava. Prema Mejovšeku (2003), tri su bitna svojstva
brojeva koja to omogućavaju:
identitet
– svaki broj, kao i svako svojstvo objekta, ima svoj
identitet, tj. jedinstveni su i različiti od drugih objekata;
rang
– brojevi su uređeni po veličini pa se i objekti prema mjerenom
svojstvu mogu rangirati, odnosno poredati prema veličini mjerenog
svojstva;
aditivnost
– brojevi se mogu zbrajati. Zbroj dvaju brojeva uvijek je
neki jedinstveni broj. Svojstvo aditivnosti imaju ona obilježja
objekata koja se mogu podijeliti na potpuno jednake dijelove (među
kojima postoji jednak razmak). Primjerice, tjelesna visina i tjelesna
masa jer ih mjerimo mjernim jedinicama (npr. centimetri, grami)
koje imaju isti razmak.
Pri mjerenju bilo kojeg fenomena (pa tako i kineziološkog) koristimo
se nekom od sljedećih mjernih skala: nominalnom, ordinalnom,
intervalnom i omjernom skalom.
Nominalna skala
Ako neko obilježje objekta ima samo svojstvo
identiteta
, onda se
mjerenje provodi na
nominalnoj mjernoj skali.
Nominalna mjerna
skala nema kvantitativna svojstva niti kontinuitet, već se entiteti
razvrstavaju u određene kategorije ili klase, pri čemu se vodi računa
da su klase definirane jednoznačno, odnosno da svaki entitet može
Kineziometrija – Osnovni kineziometrijski pojmovi
264
pripadati samo jednoj klasi. Rezultat mjerenja je frekvencija objekata
koji pripadaju određenoj klasi (npr. muško-žensko, položili-pali itd.).
Za nominalnu skalu vrijede sljedeća pravila:
određuje se da li je
A=B
ili
A
B
ako je
A=B
, onda je i
B=A
ako je
A=B
, a
B=C
, tada je
A=C
.
Pri tome je poredak kategorija koje izražavaju odgovarajući oblik
mjerenog svojstva proizvoljan, odnosno oznake koje se pridružuju
objektima (koje mogu biti i brojevi) nemaju kvantitativno značenje
(ne izražavaju količinu mjerenog svojstva) i mogu se zamijeniti bilo
kojim drugim skupom oznaka. S obzirom na to da se radi o
nenumeričkoj (kvalitativnoj) skali, nikakve računske operacije nisu
dopuštene. To znači da ne postoji mogućnost invarijatne
transformacije
1
podataka dobivenih nominalnom skalom, osim da se
korištene oznake zamijene drugima, pri čemu se ne mijenja pripadnost
entiteta pojedinoj kategoriji.
Ordinalna skala
Ako mjereno obilježje objekta ima svojstvo
ranga
, onda se mjerenje
provodi na
ordinalnoj mjernoj skali
koja, za razliku od nominalne
mjerne skale, određuje rang, odnosno redoslijed vrijednosti. Ova
mjerna skala, pored toga što određuje pripadnost pojedinih objekata
nekoj klasi, određuje i njihov redoslijed, ali razlike između pojedinih
klasa (vrijednosti) nisu jednake. Dakle, njome je moguće utvrditi je li
neki objekt bolji od drugoga, ali ne i koliko je bolji (npr. redoslijed
trkača na cilju neke utrke, školske ocjene itd). Za ordinalnu skalu, uz
pravila koja su navedena za nominalnu skalu, vrijede i sljedeća
pravila:
ako je
A
B
, onda je
A>B
ili
A<B
ako je
A>B
, onda
B
A
ako je
A>B
, a
B>C
, tada je
A>C
.
Za invarijatne transformacije dobivenih podataka moguće je koristiti
one računske postupke koji ne mijenjaju rang, a to su sve monotone
transformacije
2
:
dodavanje i oduzimanje konstante
množenje i dijeljenje konstantom
eksponenciranje i logaritmiranje konstantnom bazom.
1
Invarijatne transformacije ne mijenjaju bitna svojstva skale.
2
Monotone transformacije imaju svojstvo stalnog porasta ili pada, odnosno ne mijenjaju smjer.

Kineziometrija – Osnovni kineziometrijski pojmovi
266
Omjerna skala
Osim svih svojstava intervalne mjerne skale,
omjerna skala
ima još i
apsolutnu nulu (potpuna odsutnost mjerenog svojstva), odnosno,
rezultati su izraženi od nulte vrijednosti pa jednaki brojčani odnosi
(omjeri) znače i jednake odnose u mjerenoj pojavi (npr. mjerenje
duljine, sile, vremena potrebnog za izvođenje neke aktivnosti). Za
omjernu skalu, uz pravila koja su navedena za prethodne skale, vrijedi
i pravilo:
nB
nA
B
A
Tako, primjerice, ako je ispitanik A u skoku udalj s mjesta postigao
rezultat 300 cm, možemo reći da je 1,5 puta bolji od ispitanika B čiji
je rezultat 200 cm (300/200=1,5). Pomnože li se rezultati ispitanika A
i B bilo kojom konstantom, omjer njihovih rezultata ostaje
nepromijenjen (2
300/2
150=1,5). Dakle, ova skala je invarijatna na
množenje bilo kojom pozitivnom konstantom, dok dodavanje ili
oduzimanje konstante nije dopušteno jer mijenja lokaciju nulte točke.
Tablica 4.1-1 sažeto prikazuje osnovna obilježja nominalne, ordinalne,
intervalne i omjerne skale.
Tablica 4.1-1.
Usporedba obilježja nominalne, ordinalne, intervalne i omjerne skale
NOMINALNA
ORDINALNA
INTERVALNA
OMJERNA
Klasifikacija
DA
DA
DA
DA
Rangiranje
NE
DA
DA
DA
Udaljenost među entitetima
NE
NE
DA
DA
Apsolutna veličina mjerenog svojstva
NE
NE
NE
DA
Empirijska svojstva
identitet
redoslijed
jednakosti
razlika
jednakosti
omjera
Invarijatne transformacije
zamjena
oznaka
sve monotone
transformacije
sve linearne
transformacije
množenje
pozitivnom
konstantom
Usporedbom navedenih obilježja moguće je uočiti da svaka sljedeća
skala (počevši od nominalne) ima sve kvalitetnija metrijska svojstva,
odnosno veću informacijsku vrijednost. Tako, primjerice, nominalna
skala omogućuje klasificiranje, ordinalna uz klasifikaciju omogućuje i
utvrđivanje redoslijeda, intervalna uz to i utvrđivanje razlika među
entitetima, dok omjerna, uz za sve navedeno, omogućuje utvrđivanje
apsolutne vrijednosti mjerenog svojstva entiteta.
Za mjerenje kinezioloških fenomena najčešće se koriste intervalna i
omjerna skala.
Kineziometrija – Konstrukcija mjernog instrumenta
267
4.2
Konstrukcija
mjernog instrumenta
Mjerni instrument
(test) je odgovarajući operator pomoću kojega se
određuje pozicija objekta mjerenja na nekoj mjernoj skali kojom se
procjenjuje predmet mjerenja. Konačni rezultat mjernog instrumenta
ukazuje na stupanj razvijenosti predmeta mjerenja. Konstrukcija
mjernog instrumenta vrlo je složen proces koji se odvija u pet koraka:
1.
definiranje predmeta mjerenja
2.
odabir odgovarajućeg tipa mjernog instrumenta
3.
izbor podražajnih situacija
4.
standardizacija mjernog postupka
5.
utvrđivanje metrijskih karakteristika.
4.2.1. Definiranje predmeta mjerenja
Svaki mjerni instrument koristi se za mjerenje nekog predmeta
mjerenja. U kineziologiji predmet mjerenja predstavljaju relevantni
kineziološki fenomeni. Primjerice, motoričke i funkcionalne
sposobnosti, morfološka obilježja, situacijska i natjecateljska
uspješnost u pojedinoj kineziološkoj aktivnosti, kvaliteta izvedbe
nekog tehničkog elementa itd. Zato konstrukcija mjernog instrumenta
započinje preciznim definiranjem predmeta mjerenja. Predmet
mjerenja najčešće je neki hipotetski konstrukt koji nije izravno

Kineziometrija – Konstrukcija mjernog instrumenta
269
kojim ćemo je indirektno procijeniti pomoću njenih
manifestacija
(npr. motoričkih aktivnosti: skokovi, bacanja, udarci..).
Takav pristup nužno nameće problem utvrđivanja pravog predmeta
mjerenja (valjanost mjernog instrumenta). Naime, uspješnost u nekoj
motoričkoj manifestaciji koju mjerimo nikad nije pod utjecajem samo
jednog faktora, nego većeg broja faktora pa se postavlja pitanje: Što je
pravi predmet mjerenja, tj. koju latentnu dimenziju procjenjujemo
nekim motoričkim testom? Problem valjanosti mjerenja bit će posebno
razmatran u poglavlju 4.3. Metrijske karakteristike (str. 306-312).
Ovisno o predmetu mjerenja, valja odabrati prikladan tip mjernog
instrumenta, odnosno način za operacionalizaciju odgovarajućeg
predmeta mjerenja.
4.2.2. Odabir odgovarajućeg tipa mjernog
instrumenta
Za procjenu relevantnih kinezioloških fenomena moguće je koristiti
nekoliko tipova mjernih instrumenata:
testovi tipa “papir-olovka”
– ubrajaju se u potpuno objektivne
mjerne instrumente jer postignuti rezultati ne ovise od pogrešci
mjerioca (ako je osposobljen za provođenje mjerenja), već isključivo
o ispitaniku. Takav tip mjernih instrumenata koristi se za utvrđivanje
kognitivnih sposobnosti, konativnih obilježja, stavova, socijalnog
statusa, prehrambenih navika itd.
aparatura za mjerenje
– u ovu skupinu mjernih instrumenata
ubrajaju se razna tehnička pomagala koja u postupku mjerenja
koristi mjerilac. To su, primjerice, instrumenti za mjerenje
morfoloških obilježja (antropometar, kaliper itd.), funkcionalnih
sposobnosti (spirometar, aparatura za mjerenje aerobnoga i
anaerobnoga
kapaciteta
itd.)
te
motoričkih
sposobnosti
(dinamometar za procjenu mišićne sile). Takav tip mjerenja je manje
objektivan od testova tipa “papir-olovka” jer dobiveni rezultati u
većoj mjeri zavise od obučenosti mjerilaca.
primjena vježbe (motoričkih zadataka)
– u ovu skupinu mjernih
instrumenata ubrajaju se različiti motorički zadaci kojima se u nekoj
poznatoj mjeri aktivira određena motorička sposobnost. Takav tip
Kineziometrija – Konstrukcija mjernog instrumenta
270
mjernih instrumenata najčešće se koristi za procjenu motoričkih
sposobnosti (primjerice, skok udalj s mjesta za procjenu eksplozivne
snage, okretnost na tlu za procjenu koordinacije itd). Za takav tip
mjernih instrumenata valja precizno definirati upute za izvođenje
zadatka, uvjete u kojima se zadatak izvodi, pomagala i način njihova
korištenja kako bi se minimizirale pogreške mjerenja.
subjektivna procjena mjerioca
– često se za procjenu nekih složenih
sposobnosti, znanja i vještina, odnosno kvalitete izvedbe koristi
subjektivna procjena kompetentnih mjerilaca (primjerice, u sportskoj
gimnastici, klizanju na ledu, skokovima u vodu itd.).
Većina mjerenja u antropološkim znanostima obavlja se pomoću
kompozitnih mjernih instrumenata
. Kompozitni mjerni instrument se
sastoji od većeg
čestica
(
engl. item
), a koje mogu biti: pitanja/zadaci
(papir-olovka), ponavljana mjerenja (aparatura, motorički zadaci) i
suci (subjektivna procjena). Tako dobiveni rezultati različitim se
statističkim postupcima kondenziraju, a daljnje obrade provode se na
kondenziranim rezultatima.
4.2.3. Izbor podražajnih situacija
Nakon preciznog definiranja predmeta mjerenja
i
odabira
odgovarajućeg tipa mjernog instrumenta valja proučiti u kojim
situacijama se manifestira predmet mjerenja, odnosno koje su to
aktivnosti u kojima se najbolje očituje predmet mjerenja. Stoga je
potrebno izvršiti klasifikaciju i selekciju podražajnih situacija koje su
simptomatske za odgovarajući predmet mjerenja. Tako, primjerice,
ako je predmet mjerenja neka kognitivna sposobnost, konativno
obilježje, stavovi, razina znanja iz nekog područja ili sl., moguće je
koristiti test tipa „papir-olovka“ koji će biti sastavljen od većeg broja
čestica. Kvaliteta mjernog instrumenta bit će determinirana izborom
čestica kojima se aktivira predmet mjerenja. Zato pri izboru čestica
treba voditi brigu o sljedećem:
čestice moraju biti kratko i jasno definirane
svaka čestica mora biti povezana s predmetom mjerenja
čestice moraju biti prilagođene ciljanoj populaciji ispitanika
čestice moraju varirati po težini i složenosti kako bi uspješno
razlikovale ispitanike po predmetu mjerenja.
Za procjenu nekih složenih sposobnosti, znanja i vještina (primjerice,
uspješnost u sportskoj gimnastici, klizanju na ledu, skokovima u vodu,

Kineziometrija – Konstrukcija mjernog instrumenta
272
4.2.5. Utvrđivanje metrijskih karakteristika
Nakon konstrukcije preliminarne forme mjernog instrumenta valja ga
empirijski provjeriti te tako doći do konačne verzije mjernog
instrumenta sa zadovoljavajućim metrijskim karakteristikama. Prvu
formu testa treba provjeriti na pilot-uzorku koji će po karakteristikama
biti sličan populaciji za koju se test konstruira. Time se dobije
empirijska osnova za tzv. analizu čestica
(
engl. item analysis
). Pod
analizom čestica podrazumijeva se niz postupaka pomoću kojih
procjenjujemo težinu i valjanost čestica.
Ako se radi o mjernom instrumentu tipa „papir-olovka“, težina čestica
se provjerava tzv.
indeksom lakoće (težine)
koji je pokazatelj
diskriminativnosti svake čestice. Indeks lakoće svake čestice
predstavlja proporciju ispitanika koji su taj zadatak uspješno riješili
(
p=u/n
, gdje je
u
broj ispitanika koji su uspješno riješili zadatak, a
n
ukupan broj ispitanika). Odgovarajućim izborom zadataka s obzirom
na njihovu težinu, moguće je utjecati na osjetljivost mjernog
instrumenta. Zadaci ne bi smjeli biti ni preteški ni prelagani jer bi u
tim slučajevima slabo razlikovali ispitanike. Stoga većina čestica treba
Primjer:
Naziv:
Skok udalj s mjesta
Šifra:
MFESDM
Tehnički opis:
Zatvorena prostorija najmanjih dimenzija 6x2 metra. Od zida se postave tanke
strunjače tako da ukupna duljina strunjača ne bude manja od 4,5 m. Strunjače su
fiksirane s jedne strane zidom, a s druge strane stopalima dvojice pomagača. Na
strunjači se označi početna (odskočna) linija 80 cm od zida. Od početne linije na
udaljnosti od 2 metra pa sve do 3,3 metra označe se svakih 5 cm paralelne linije duge
30 cm.
Opis mjernog
postupka:
Ispitanik stane bosim stopalima do samog ruba početne linije ležima prema zidu.
Zadatak je ispitanika sunožnim odrazom skočiti prema naprijed što je moguće dalje.
Zadatak je završen nakon što ispitanik izvede 4 uspješna skoka. Neuspješnim skokom
smatra se:
skok nakon dvostrukog odraza (poskoka) u mjestu prije skoka
skok nakon prestupa početne linije
skok koji nije izveden sunožnim odrazom
skok kojem prethodi dokorak
skok nakon kojeg ispitanik dodirne strunjaču iza peta
skok nakon kojeg ispitanik pri doskoku sjedne
Uputa ispitaniku:
Zadatak se demonstrira i objašnjava: „Vaš je zadatak da stanete iza početne linije i
sunožnim odrazom skočite što više možete prema naprijed. Doskok mora biti na dvije
noge. U slučaju neispravnog skoka, zadatak se ponavlja. Ako je zadatak jasan,
pripremite se za početak.“
Određivanje
rezultata:
Rezultat u testu izražava se u centimetrima, a određuje se kao aritmetička sredina 4
uspješna skoka.
Kineziometrija – Konstrukcija mjernog instrumenta
273
imati indeks lakoće koji se kreće oko
p=0,5
te podjednak i manji broj
čestica čiji je indeks lakoće manji i veći od
0,5
. Valjanost čestica
moguće je procijeniti kao prosječnu korelaciju između čestica. Što se
čestice međusobno više slažu, to im je veća količina zajedničke
varijance, odnosno čestice imaju više istog predmeta mjerenja.
Pomoću analize težine i valjanosti čestica biraju se čestice za konačni
oblik testa. Pravilnim izborom čestica utječemo na metrijske
karakteristike cijelog mjernog instrumenta. Primjerice, odgovarajućim
izborom i raspodjelom čestica s obzirom na indeks lakoće utječemo na
osjetljivost, dok korelacijom između čestica utječemo na pouzdanost i
dijagnostičku valjanost.
Nakon izrade konačnog oblika mjernog instrumenta na
reprezentativnim
se
uzorcima
ispitanika
utvrđuju metrijske
karakteristike. Metrijske karakteristike su: pouzdanost, objektivnost,
homogenost, valjanost i osjetljivost. Pri tome valja naglasiti da se
utvrđene metrijske karakteristike uvijek odnose na određenu
populaciju na čijim su reprezentativnim uzorcima utvrđene, a nikako
ne na sve ispitanike.

Kineziometrija – Metrijske karakteristike
275
mjerenja jer promjene koje ti faktori izazivaju nisu posljedica
promjene predmeta mjerenja. Upravo njihovim uzrocima i
posljedicama bavi se teorija pouzdanosti. U kineziološkim mjerenjima
pogreške mjerenja najčešće nastaju kao rezultat:
mjerenja različitih mjerilaca
različitih mjerenja istog mjerioca
variranja mjerene karakteristike u tijeku dana (primjerice, tjelesna
visina varira oko 1 cm u tijeku dana)
mjerenja različitom mjernom aparaturom (primjerice, nejednako
baždarena mjerna aparatura)
slučajnih pogrešaka pri primjeni bilo kojeg mjernog instrumenta.
Prema tome, na smanjenje pogreške mjerenja moguće je utjecati
dobrom uvježbanošću mjerilaca, pridržavanjem standardiziranog
postupka mjerenja, kvalitetnom mjernom opremom koja se redovito
baždari te provođenjem mjerenja u isto vrijeme ili u vrlo kratkom
vremenskom razmaku.
Da bi neki mjerni instrument bio iskoristiv u praksi, mora
zadovoljavati zahtjev za visokom pouzdanošću. Pouzdanost bilo kojeg
mjernog postupka moguće je odrediti na temelju
klasične teorije
mjerenja
(koje su utemeljitelji Spearman, Yule, Thurstone, Guilford i
dr.) i
Gutmanovog modela mjerenja
koji je izveden iz
Guttmanove
image teorije
(Guttman, 1953).
4.3.1.1. Klasični model mjerenja
Klasični model mjerenja izveden je na pretpostavci o postojanju tzv.
paralelnih testova
. Paralelnim testovima smatraju se mjerni postupci
koji u jednakom stupnju izazivaju i mjere isti predmet mjerenja, a to
znači da imaju jednake aritmetičke sredine, standardne devijacije i
interkorelacije (Guliksen, 1950, prema Mejovšek, 2003). To znači da,
kada bismo imali
m
paralelnih testova kojima bismo izmjerili
n
ispitanika i ako bi pouzdanost mjerenja bila maksimalna, odnosno
kada ne bi bilo nesistematskog varijabiliteta, tada bi rezultati
ispitanika u
m
paralelni testova bili jednaki. Nasuprot tome, ako
mjerenje nije potpuno pouzdano, rezultati ispitanika u
m
paralelnih
testova bit će manje ili više različiti, odnosno nesistematski će varirati
oko pravog rezultata. Dakle, ako
n
ispitanika izmjerimo skupom od
m
paralelnih testova, dobije se tablica 4.3-1.
Kineziometrija – Metrijske karakteristike
276
Tablica 4.3-1.
Bruto rezultati n ispitanika, izmjerenih pomoću
m
paralelnih testova,
dekomponirani prema klasičnoj teoriji mjerenja na komponentu pravih rezultata i komponentu
pogreške mjerenja
Paralelni testovi
Isp
1
2
. .
j
. .
m
X
s
a
x
a1
=t
a1
+e
a1
x
a2
=t
a2
+e
a2
. .
x
aj
=t
aj
+e
aj
. . x
am
=t
am
+e
am
x
a
s
a
b
x
b1
=t
b1
+e
b1
x
b2
=t
b2
+e
b2
. .
x
bj
=t
bj
+e
bj
. . x
bm
=t
bm
+e
bm
x
b
s
b
.
.
.
. .
.
. .
.
.
.
.
.
.
. .
.
. .
.
.
.
i
x
i1
=t
i1
+e
i1
x
i2
=t
i2
+e
i2
. .
x
ij
=t
ij
+e
ij
. .
x
im
=t
im
+e
im
x
i
s
i
.
.
.
. .
.
. .
.
.
.
.
.
.
. .
.
. .
.
.
.
n
x
n1
=t
n1
+e
n1
x
n2
=t
n2
+e
n2
. .
x
nj
=t
nj
+e
nj
. . x
nm
=t
nm
+e
nm
x
n
s
n
x
x
1
x
2
. .
x
j
. .
x
m
1
2
. .
j
. .
m
Osim toga, klasični model mjerenja temelji se na sljedećim
pretpostavkama:
razultat svakog mjerenja, tzv.
bruto rezultat
(
x
), ovisi o veličini
predmeta mjerenja, budući da u sebi sadrži veličinu predmeta
mjerenja, tj.
pravi rezultat
(
t
), i o
komponenti pogreške
(
e
) koja ga
nesistematski mijenja.
x = t + e
Pravi je rezultat (
t
) točni rezultat veličine predmeta mjerenja, a bilo
bi ga moguće dobiti kada na mjerenje osim predmeta mjerenja ne bi
utjecali drugi faktori, odnosno kada bi mjerenje bilo potpuno
pouzdano. Osim efekata pravog rezultata, bruto rezultat sadrži i
efekte pogreške
. Pogreška mjerenja (
e
) ovisi o djelovanju
nesistematskih, varijabilnih faktora.
predmet mjerenja je
stabilan
u vremenu; iz toga slijedi da će pravi
rezultat jednog ispitanika u paralelnim mjerenjima biti jednak.
t
a1
= t
a2
= ......= t
aj
= ......= t
am
t
b1
= t
b2
= ......= t
bj
= ......= t
bm
‘’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’
t
i1
= t
i2
= ......= t
ij
= ......= t
im
‘’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’’
t
n1
= t
n2
= ......= t
nj
= ......= t
nm

Kineziometrija – Metrijske karakteristike
278
Dakle, osnovna pretpostavka klasičnog modela mjerenja je da se
komponente pogrešaka mjerenja međusobno poništavaju, odnosno da
je aritmetička sredina rezultata nekog paralelnog testa, primijenjenog
na svim ispitanicima neke populacije jednaka aritmetičkoj sredini
pravih rezultata tog testa. Ta pretpostavka vrijedi i za aritmetičku
sredinu rezultata bilo kojeg ispitanika koji je izmjeren beskonačno
velikim brojem paralelnih testova. Iz toga slijedi važan zaključak za
praksu, a to je da se aritmetičkom sredinom većeg broja paralelnih
testova postiže bolja procjena pravog rezultata nego li primjenom bilo
kojeg pojedinačnog testa.
U skladu s time lako je uočiti da će aritmetičke sredine bruto rezultata,
koje su jednake u svim paralelnim testovima, biti jednake
aritmetičkim sredinama pravih rezultata svih paralelnih testova.
tm
tj
t
t
m
j
x
x
x
x
x
x
x
x
....
....
....
....
2
1
2
1
To je zato jer je aritmetička sredina nekog paralelnog testa
x
j
jednaka
jednostavnoj linearnoj kombinaciji aritmetičke sredine pravih
rezultata
x
tj
i aritmetičke sredine pogrešaka mjerenja
x
ej
tog testa.
ej
tj
j
x
x
x
Kako je
x
ej
=0,
dakle aritmetička sredina komponenata pogrešaka
nekog paralelnog testa
j
izračunata na svim ispitanicima neke
populacije jednaka nuli
,
slijedi da je
tj
j
x
x
.
Osim toga, a s obzirom na pretpostavku da komponente pogreške
mjerenja variraju posve slučajno, odnosno potpuno nesustavno,
moguće je zaključiti:
kovarijanca između varijabli pogrešaka bilo kojih dvaju paralelnih
testova bit će jednaka nuli
cov (e
j
, e
k
) = 0 (j
k)
kovarijanca između varijabli pogrešaka i varijabli pravih rezultata
istog paralelnog testa bit će jednaka nuli
cov (t
j
, e
j
) = 0
cov (t
k
, e
k
) = 0
Kineziometrija – Metrijske karakteristike
279
kovarijanca između varijabli pogrešaka jednog testa i varijabli
pravih rezultata nekog drugog paralelnog testa bit će jednaka nuli
cov (t
j
, e
k
) = 0
cov (t
k
, e
j
) = 0
.
Dakle, klasični model mjerenja pretpostavlja da su pogreške mjerenja
međusobno nezavisne, da su pravi rezultati i pogreške mjerenja istog
testa međusobno nezavisni te da su pravi rezultati jednog testa
nezavisni od pogrešaka mjerenja u drugom testu.
Isto kao i kod aritmetičkih sredina, i varijanca nekog paralelnog testa,
j
2
jednaka je jednostavnoj linernoj kombinaciji varijance pravih
rezultata
tj
2
i varijance pogrešaka mjerenja
ej
2
tog testa.
2
2
2
ej
tj
j
Dokaz:
Ako su
x
ij
= t
ij
+ e
ij
centrirani rezultati
n
ispitanika dobiveni primjenom
m
paralelnih testova,
tada se njihovim kvadriranjem dobije
x
ij
2
=(t
ij
+ e
ij
)
2
= t
ij
2
+ e
ij
2
+ 2t
ij
e
ij
.
Zbrojem rezultata svih ispitanika i dijeljenjem brojem ispitanika
n
dobije se
n
e
t
n
e
n
t
n
x
n
i
ij
ij
n
i
ij
n
i
ij
n
i
ij
1
1
2
1
2
1
2
2
.
Stoga proizlazi da je
2
2
2
ej
tj
j
jer je:
n
x
n
i
ij
j
1
2
2
- varijanca bruto rezultata paralelnog testa
j
,
n
t
n
i
ij
tj
1
2
2
- varijanca pravih rezultata paralelnog testa
j
,
n
e
n
i
ij
ej
1
2
2
- varijanca pogrešaka mjerenja paralelnog testa
j
,
0
n
e
t
n
1
i
ij
ij
- kovarijanca između pogrešaka mjerenja i pravih rezultata paralelnog testa
jednaka nuli.

Kineziometrija – Metrijske karakteristike
281
2
1
1
1
1
2
2
1
2
n
e
e
n
e
t
n
e
t
n
t
n
e
e
e
t
e
t
t
r
n
i
ik
ij
n
i
ik
i
n
i
ij
i
n
i
i
n
i
ik
ij
ik
i
ij
i
i
jk
S obzirom na to da je
tada proizlazi da je
tt
t
jk
r
r
2
2
,
gdje
2
t
varijanca pravih rezultata, a
2
varijanca bruto rezultata.
Dakle, korelacija dvaju paralelnih testova jednaka je omjeru varijance
pravih rezultata i varijance bruto rezultata, što predstavlja i formalnu
definiciju
koeficijenta pouzdanosti (r
tt
)
.
Kako je varijanca bruto rezultata u bilo kojem paralelnom testu
jednaka
2
2
2
e
t
,
onda je
2
2
2
e
t
,
pa je
2
2
e
2
2
e
2
2
2
t
tt
σ
σ
1
σ
σ
σ
σ
σ
r
.
Iz toga slijedi da je
tt
2
2
e
r
1
σ
σ
,
pa je
)
r
(1
σ
σ
tt
2
2
e
,
odnosno
)
r
(1
σ
σ
tt
e
,
a ako se radi o standardiziranim rezultatima, onda je
2
1
2
t
n
i
i
n
t
0
1
n
e
t
n
i
ij
i
0
1
n
e
t
n
i
ik
i
0
1
n
e
e
n
i
ik
ij
,
Kineziometrija – Metrijske karakteristike
282
)
r
(1
σ
tt
e
,
gdje
e
predstavlja
standardnu pogrešku mjerenja
, odnosno
standardnu devijaciju distribucije pogrešaka.
Upotreba standardne pogreške mjerenja u praktične svrhe temelji se
na njenoj interpretaciji pod
modelom
normalne distribucije
(budući da
su komponente pogreške slučajne varijable, normalno se
distribuiraju). Tako se standardna pogreška mjerenja koristi za
utvrđivanje granica intervala u kojem se s određenom vjerojatnošću
nalazi pravi rezultat (prava veličina predmeta mjerenja). O načinu na
koji će se vrijednost standardne pogreške mjerenja pribrojiti pravom
rezultatu ovisit će sigurnost tog zaključka, tj.
x
ij
+
e
-
omeđuje interval u kojemu se pravi rezultat nalazi s 68,27%
vjerojatnosti
x
ij
+2
e
- omeđuje interval u kojemu se pravi rezultat nalazi s
95,45% vjerojatnosti
x
ij
+3
e
- omeđuje interval u kojemu se pravi rezultat nalazi s
99,73% vjerojatnosti.
Lako je uočiti da postoji obrnuto proporcionalna veza između veličine
standardne pogreške mjerenja i koeficijenta pouzdanosti. Vrijednost
standardne pogreške mjerenja kreće se između
0
i
1
. Minimalna
vrijednost standardne pogreške mjerenja je
0
, što znači da je takav test
maksimalno pouzdan (koeficijent pouzdanosti iznosi
1
).
e
= 0
r
tt
= 1
Maksimalna vrijednost standardne pogreške mjerenja je
1
, što znači da
je test nepouzdan i da mu je veličina koeficijenta pouzdanosti jednaka
nuli.
e
= 1
r
tt
= 0
Međutim, valja istaknuti da se tako definiran koeficijent ne može
izračunati jer su varijance pravih rezultata i varijance pogreške
nepoznate. Stoga je koeficijent pouzdanosti moguće aproksimativno
odrediti na nekoliko načina, od kojih se u kineziološkim
istraživanjima najčešće koriste:
metoda test-retest
metoda tau-ekvivalentnih testova i
metoda interne konzistencije.

Kineziometrija – Metrijske karakteristike
284
Najjednostavniji način za izračunavanje ukupnog rezultata u nekom
kompozitnom testu jest Burtova metoda
jednostavne sumacije
(Burt,
1941, prema Momirović i suradnici, 1999). Ova metoda pretpostavlja
da sve čestice jednako sudjeluju u određivanju pravog predmeta
mjerenja te se ukupan rezultat u testu dobije jednostavnom linearnom
kombinacijom, odnosno zbrojem rezultata entiteta u česticama. Tako
dobivene rezultate moguće je podijeliti brojem čestica te ukupan
rezultat izraziti kao prosječan rezultat ispitanika u česticama.
Ako su rezultati
n
entiteta dobiveni primjenom nekog kompozitnog
mjernog instrumenta s
m
čestica, smješteni u matricu
B
tako da su
rezultati entiteta u redcima, tada je
b
=
B1
;
b’
=
B1
m
-1
gdje je
b
vektor sumiranih rezultata entiteta u česticama,
b’
vektor
prosječnih rezultata entiteta u česticama, a
1
sumacijski vektor s
m
jedinica. Operacijom
Z
=
(
B - PB
)
V
-1
,
gdje je
P=1
(
1
T
1
)
-1
1
T
, a
V
2
=
diag
C
dijagonalna matrica varijanci
čestica, jer je
C
=(
B
T
B
-
B
T
PB
)
n
-1
matrica kovarijanci čestica s
varijancama u dijagonali, dobije se transformacija varijabli iz
intaktne
realne metrike
u
standardiziranu realnu metriku
s očekivanim
vrijednostima
E(Z) = 0
, i
E(Z
2
) = 1
.
Prema klasičnom modelu mjerenja, koji smo već opisali, matricu
Z
možemo dekomponirati na matricu pravih rezultata
T
i matricu
pogrešaka mjerenja
E
Z
=
T
+
E
za koju vrijedi da je
R
=
Z
T
Z
n
-1
=
W
+
S
2
,
gdje je
W
matrica kovarijanci između varijabli pravih rezultata, a
S
2
dijagonalna matrica varijanci varijabli pogrešaka. Moguće je uočiti da
korelacije između varijabli dobivenih pomoću
m
paralelnih testova
ovise samo o pravim rezultatima u tim varijablama.
Kineziometrija – Metrijske karakteristike
285
Rezultati entiteta u česticama kondenziraju se operacijom
z
=
Z1
,
t
=
T1
,
e
=
E1
Uz prethodno navedene pretpostavke klasičnog modela mjerenja te uz
pretpostavku da su čestice testa strogo paralelne, a to znači da su
aritmetičke sredine, standardne devijacije čestica i korelacije između
čestica jednake, može se zaključiti da je varijanca kondenzirane
varijable jednaka
2
= m+(m
2
-m)r
,
varijanca pravih rezultata
t
2
= m
2
r
,
a varijanca pogrešaka mjerenja
e
2
= m(1- r)
.
Dokaz:
t
2
=
t
T
t
n
-1
=
(T1)
T
T1
n
-1
=
1
T
T
T
T1
n
-1
=
1
T
C1
=
1
T
(R-S
2
)1
= m
2
r
Dokaz:
e
2
=
e
T
e
n
-1
=
(E1)
T
E1
n
-1
=
1
T
E
T
E1
n
-1
=
1
T
S
2
1
=
1
T
S
2
1
=
m(1 - r)
Dokaz:
2
=
z
T
z
n
-1
=
(Z1)
T
Z1
n
-1
=
1
T
Z
T
Z1
n
-1
=
1
T
R1
=
m+(m
2
-m)r

Kineziometrija – Metrijske karakteristike
287
S obzirom na to da je pretpostavka o jednakosti svih korelacija između
čestica potpuno nerealna, obično se u račun uzima prosječna
korelacija između čestica
r
.
r
1)
(m
1
r
m
r
tt
Ako se u gornju formulu umjesto koeficijenta korelacije
r
uvrsti izraz
za njegovu procjenu putem varijance testa
1)
m(m
m
σ
r
2
,
moguće je doći do formule
R1
1
T
m
1
1
m
m
r
tt
koja se često koristi u praksi, a koja je ekvivalentna prethodnoj.
Izvod:
2
= m+(m
2
-m)r =m+mmr-mr=m(1+mr-r)=m(1+(m-1)r)
dijeljenjem cijelog izraza
sa
m
, dobije se
1)r
(m
1
m
σ
2
,
odnosno
1)r
(m
1
m
σ
2
.
Ako ovaj izraz
podijelimo sa
(m-1)
, dobije se
1)
m(m
m
σ
1
m
m
m
σ
1
m
m
m
m
σ
1
m
1
m
σ
r
2
2
2
2
.
Izvod:
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
tt
σ
m
1
1
m
m
σ
m
σ
1
m
m
1)
(m
σ
m)
m(σ
m
σ
1
m
m
σ
m
m
σ
m
1
m
m
σ
m
m
σ
m
m
1
m
m
σ
m
m
σ
1
1
m
m
σ
1)
m(m
m
σ
1)
(m
1
1)
m(m
m
σ
m
1)r
(m
1
mr
r
R1
1
T
m
1
1
m
m
jer je
2
=
1
T
R1
.
Kineziometrija – Metrijske karakteristike
288
Osim navedenih formula često se koristi i
Cronbachova formula
(Cronbach, 1951)
2
m
1
j
2
j
tt
σ
σ
1
1
m
m
r
koja, za razliku od prethodne formule, izračunava pouzdanost na
temelju originalnih rezultata.
Ako se destandardiziraju rezultati entiteta u česticama operacijom
X
=
ZS
,
gdje je
X
matrica centriranih rezultata entiteta u česticama, a
S
dijagonalna matrica standardnih devijacija čestica testa, vektor
ukupnih rezultata u testu izračuna se običnom sumacijom operacijom
x
=
X1
s varijancom
2
=
1
T
C1
,
gdje je
C=SRS
matrica kovarijanci rezultata u česticama testa, moguće
je uvidjeti da je
1
C
1
1
S
1
T
2
T
1
1
m
m
σ
σ
1
1
m
m
2
m
1
j
2
j
tt
r
.
Dokaz:
2
=
x
T
x
n
-1
=
(X1)
T
X1
n
-1
=
(ZS1)
T
ZS1
n
-1
=
1
T
SZ
T
ZS1
n
-1
=
1
T
SRS1
=
1
T
C1

Kineziometrija – Metrijske karakteristike
290
Transformacijom navedene
SB-formule
moguće je izračunati koliko
puta treba povećati broj čestica za dobivanje očekivane (željene)
pouzdanosti, operacijom
)
r
(1
r
)
r
(1
r
k
tt
xx
xx
tt
,
gdje je
r
tt
očekivani (željeni) koeficijent pouzdanosti
r
xx
koeficijent pouzdanosti postojećeg testa
k
koeficijent povećanja broja čestica.
Ukupni rezultat na nekom kompozitnom testu moguće je izračunati
prvom glavnom komponentom standardiziranih rezultata u česticama.
Metoda glavnih komponenata detaljno je opisana u poglavlju 3.2.
Faktorska analiza (str. 214-237). Osnovna ideja ove metode
(kondenzacije rezultata u česticama nekog kompozitnog testa) jest da
se linearnom kombinacijom rezultata entiteta u česticama dobije nova
varijabla koja će imati maksimalnu varijancu, odnosno osjetljivost,
operacijom
k
=
Zx
,
gdje je
k
T
k
n
-1
=
2
=
max,
a
x
T
x
=
1
.
Ovaj se problem rješava pomoću
karakteristične jednadžbe
(R -
I) x
=
0
.
Varijable matrice standardiziranih rezultata u česticama moguće je
transformirati na
prvu glavnu komponentu
operacijom
k
=
Z x
koja ima maksimalnu varijancu
=
2
=
k
T
k
n
-1
čija je mjera pouzdanosti jednaka
λ
1
1
1
m
m
α
.
Kineziometrija – Metrijske karakteristike
291
Mjeru pouzdanosti za ovako izračunat ukupan rezultat u nekom
kompozitnom testu predložili su Lord (1958) i, nezavisno od njega,
Kaiser i Caffrey (1965) te su utvrdili da se tim načinom kondenzacije
rezultata nekog kompozitnog testa postiže maksimalna pouzdanost
pod klasičnim modelom mjerenja. Međutim, iako postupak za
utvrđivanje ukupnog rezultata u testu prvom glavnom komponentom
osigurava, u pravilu, jednaku ili veću pouzdanost od metode
jednostavne sumacije, valja naglasiti da se tim postupkom neće postići
bitno veća pouzdanost u odnosu na metodu jednostavne sumacije ako
su čestice testa podjednakih aritmetičkih sredina, standardnih
devijacija i međusobnih korelacija.
Primjer:
10 ispitanika izmjereno je jednim testom motorike sa tri
čestice. U tablici se nalaze njihovi originalni (
x
1
, x
2
, x
3
) i
standardizirani rezultati u svakoj čestici (
z
1
, z
2
, z
3
), kao i ukupni
rezultati određeni metodom jednostavne sumacije originalnih (
x
) i
standardiziranih (
z
) rezultata te ukupni rezultati određeni prvom
glavnom komponentom (
k
1
). Za sve varijable izračunate su
aritmetičke sredine i varijance na temelju kojih je moguće izračunati
odgovarajuće koeficijente pouzdanosti.
ISP.
x
1
x
2
x
3
x
z
1
z
2
z
3
z
k
1
1
70
115
115
300
-1,249
0,454
0,398
-0,397
-0,046
2
150
145
142
437
1,894
1,874
1,870
5,638
2,078
3
100
120
122
342
-0,071
0,691
0,780
1,400
0,565
4
120
92
100
312
0,715
-0,634
-0,420
-0,339
-0,199
5
105
82
87
274
0,126
-1,107
-1,129
-2,110
-0,853
6
94
116
117
327
-0,306
0,502
0,507
0,702
0,308
7
120
100
105
325
0,715
-0,256
-0,147
0,312
0,061
8
60
70
76
206
-1,642
-1,675
-1,728
-5,046
-1,865
9
99
104
105
308
-0,110
-0,066
-0,147
-0,323
-0,119
10
100
110
108
318
-0,071
0,218
0,016
0,163
0,071
x 101,80 105,40
107,70
314,90
0
0
0
0
0
2
647,73 446,49
336,46
3301,21
1
1
1
7,180
2,420
Koeficijent pouzdanosti za ukupne rezultate dobivene metodom
jednostavne sumacije originalnih rezultata ispitanika u česticama
izračuna se prema
Cronbachovom koeficijentu pouzdanosti

Kineziometrija – Metrijske karakteristike
293
Znanstveni članak L. Guttmana:
Image Theory for the
Structure of Quantitative Variates,
objevljen je u časopisu
Psychometrika
1953. godine.
Ovo, naravno, ne vrijedi za sve testove koji se koriste u kineziološkim
istraživanjima i sportskoj praksi, a pogotovu ne za testove koji se
koriste za procjenu kognitivnih, konativnih i socioloških dimenzija
kod kojih se veća pouzdanost može postići nešto složenijim
postupcima za utvrđivanje ukupnog rezultata u testu koji počivaju na
Guttmanovu modelu mjerenja.
4.3.1.2. Guttmanov model mjerenja
Za razliku od klasičnog modela
mjerenja kod kojeg nije moguće
izračunati
prave
rezultate
i
pogreške mjerenja (jer je broj
nepoznanica uvijek veći od broja
jednadžbi),
Guttmanov model
mjerenja
dopušta izračunavanje
pravih rezultata i pogrešaka u
česticama nekog kompozitnog
mjernog instrumenta. Pored toga,
izračunavanje ukupnog rezultata
u
nekom
testu
pod
ovim
modelom ima u najgorem slučaju
jednaku ili veću pouzdanost od
one
koja
se
postiže
pod
klasičnim modelom mjerenja
nekog
kompozitnog
mjernog
instrumenta metodom interne
konzistencije (Momirović i sur.,
1999).
Guttmanov
model
mjerenja izveden je iz njegove
image teorije
(Guttman, 1953).
Louis Guttman je u članku
Image Theory for the Structure of
Quantitative Variates,
objavljenom u časopisu
Psychometrika
1953.
godine, predstavio image teoriju. Ova je teorija snažno utjecala ne
samo na razvoj teorije mjerenja već i na razvoju faktorske analize
1
pa
će u nastavku biti ukratko opisana.
1
Guttman je razvio jedan model fakotrske analize koji je nazvao
image analiza
, koja je detaljnije opisana
u knjigama: A. Fulgosi (1984). Faktorska analiza, Školska knjiga, Zagreb; N. Viskić-Štalec (1991).
Elementi faktorske analize. Fakultet za fizičku kulturu. Zagreb.
Kineziometrija – Metrijske karakteristike
294
Rezultat bilo kojeg entiteta u nekoj varijabli moguće je dekomponirati
na zavisni i nezavisni dio od preostalih varijabli iz promatranog skupa.
Stoga se može napisati da je
z
ij
= t
ij
+ e
ij
gdje je
z
ij
standardizirni rezultat entiteta
i
u varijabli
j
t
ij
rezultat entiteta
i
u varijabli
j
koji se može predvidjeti na temelju
ostalih varijabli iz promatranog skupa
e
ij
rezultat entiteta
i
u varijabli
j
koji se ne može predvidjeti na
temelju ostalih varijabli iz promatranog skupa.
Prema Gutmanovoj image teoriji
t
j
predstavlja
image
, a
e
j
antiimage
komponentu varijable
j
. Image i antiimage rezultate entiteta u svakoj
varijabli promatranog skupa moguće je izračunati serijom multiplih
regresijskih analiza (v. poglavlje 3.1) u kojima se svaka varijabla
tretira kao kriterijska, a preostale iz promatranog skupa kao
prediktorske.
Neka je iz neke populacije entiteta
P={e
i
;i=1,2,...,N}
slučajnim
odabirom dobiven uzorak
E={e
i
;i=1,2….,n}
te opisan uzorkom
varijabli (čestica)
V={v
j
;j=1,2…m}
, dobivenih primjenom nekog
kompozitnog mjernog instrumenta (testa)
T
.
Neka je
Z
matrica standardiziranih rezultata entiteta iz skupa
E
,
opisanih varijablama iz skupa
V
, a
z
j
vektor rezultata entiteta u
varijabli
j
te
Z
m-j
matrica rezultata entiteta opisanih sa
k
(
k=1...m-1,k
j
) varijabli izuzevši varijablu
j
. Operacijom
1
j
m
T
j
m
j
m
n
Z
Z
R
dobije se korelacijska matrica reda
m-1
iz koje je isključena varijabla
j
, a operacijom
1
n
j
T
j
m
j
z
Z
r
vektor korelacija varijable
j
s ostalih
k
varijabli. Vektor
standardiziranih regresijskih koeficijenata kojima se procjenjuje
varijabla
j
temeljem preostalih
k
varijabli, dobije se operacijom
j
1
j
m
j
r
R
β

Kineziometrija – Metrijske karakteristike
296
E
=
Z
-
T
=
Z
-
Z(I
-
U
2
R
-1
)
=
Z U
2
R
-1
,
a kovarijance između njih operacijom
Q
=
E
T
E
n
-1
=
U
2
R
-1
U
2
.
Za razliku od klasičnog modela mjerenja, kod kojega su kovarijance
varijabli pogrešaka mjerenja jednake nuli, u Gutmanovu modelu
mjerenja to nije slučaj.
Pored toga, u Gutmanovu modelu mjerenja važe sljedeći odnosi
između izmjerenih i pravih rezultata te pogrešaka mjerenja:
kovarijance između pravih rezultata i pogrešaka mjerenja različitih
čestica nisu jednaki nuli
T
T
E
n
-1
=
U
2
-
U
2
R
-1
U
2
,
dok su kovarijance pravih rezultata i pogrešaka mjerenja istih
(korespondentnih) čestica jednake nuli
diag(
T
T
E
n
-1
)= 0
kovarijance između izmjernih rezultata i pogrešaka mjerenja
različitih čestica jednake su nuli, dok su kovarijance izmjerenih
rezultata i pogrešaka mjerenja istih (korespondentnih) čestica
jednake varijancama varijabli pogrešaka mjerenja
Z
T
E
n
-1
=
U
2
kovarijance između izmjerenih rezultata i pravih rezultata različitih
čestica jednake su njihovim korelacijama, dok su kovarijance
između izmjerenih i pravih rezultata istih (korespodentnih) čestica
jednake koeficijentima determinacije multiple korelacije te čestice s
preostalim česticama, što predstavlja pravu varijancu svake čestice
Z
T
T
n
-1
=
R
-
U
2
.
Kineziometrija – Metrijske karakteristike
297
Tablica 4.3-2.
Usporedba klasičnog i Guttmanova modela mjerenja
KLASIČNI MODEL MJERENJA
GUTTMANOV MODEL MJERENJA
nije moguće izračunat prave rezultata mjerenja
moguće je izračunati prave rezultate mjerenja
kovarijance pogrešaka mjerenja različitih
čestica jednake su nuli
cov(e
j
,e
k
)=0
kovarijance pogrešaka mjerenja različitih
čestica nisu jednake nuli
cov(e
j
,e
k
)
0
kovarijance pravih rezultata i pogrešaka
mjerenja istih čestica jednake su nuli
cov(t
j
,e
j
)=0
kovarijance pravih rezultata i pogrešaka mjerenja
iste čestice jednake su nuli
cov(t
j
,e
j
)=0
kovarijance pravih rezultata i pogrešaka
mjerenja različitih čestica jednake su nuli
cov(t
j
,e
k
)=0
kovarijance pravih rezultata i pogrešaka mjerenja
različitih čestica nisu jednake nuli
cov(t
j
,e
k
)
0
kovarijance izmjerenih rezultata i pogrešaka
mjerenja istih čestica jednake su varijancama
pogrešaka mjerenja
cov(z
j
,e
j
)=u
j
2
kovarijance između izmjerenih rezultata i
pogrešaka mjerenja različitih čestica jednake su
nuli
cov(z
j
,e
k
)=0
kovarijance izmjerenih i pravih rezultata i istih
čestica jednake su koeficijentima determinacije,
odnosno njihovim pravim varijancama
cov(z
j
,t
j
)=
j
2
kovarijance između izmjerenih i pravih rezultata
različitih čestica jednake su njhovim korelacijama
cov(z
j
,t
k
)=r
jk
Usporedbom klasičnog i Gutmanova modela mjerenja (tablica 4.3-2)
moguće je zaključiti:
Guttmanov model omogućava izračunavanje pravih rezultata i
pogrešaka mjerenja, dok klasični to ne omogućava
klasični model mjerenja pretpostavlja nezavisnost pogrešaka
mjerenja, dok Gutmanov ne
u klasičnom, kao i Guttmanovu modelu pravi rezultati i pogreške
mjerenja istih čestica međusobno su nezavisne
klasični model mjerenja pretpostavlja nezavisnost pravih rezultata i
pogrešaka mjerenja različitih čestica, dok Gutmanov ne.
Osim toga, u Guttmanovu modelu:
kovarijance izmjerenih rezultata i pogrešaka mjerenja istih čestica
jednake su varijancama pogrešaka mjerenja, odnosno uniknim
(rezidualni ili nezavisni) dijelovima varijanci svake čestice s
preostalim česticama testa
kovarijance između izmjerenih rezultata i pogrešaka mjerenja
različitih čestica jednake su nuli
kovarijance izmjerenih i pravih rezultata istih čestica jednake su
koeficijentima determinacije multiple korelacije svake čestice s
prestalima iz promatranog skupa

Kineziometrija – Metrijske karakteristike
299
diag
C
h
= U
-2
.
Univerzalna metrika je invarijantna na promjene u skaliranju varijabli
te predstavlja najpovoljniji oblik transformacije rezultata u česticama
nekog testa jer optimalno ponderira rezultate u česticama
(proporcionalno faktorskoj valjanosti čestica), čime se ukupni rezultat
u testu izračunava s maksimalnom pouzdanošću (Momirović i sur.,
1999).
Ukupan rezultat u nekom kompozitnom testu koji ima maksimalnu
pouzdanost odredi se kao prva glavna komponenta čestica
transformiranih u Harrisovu metriku
h
=
ZU
-1
y
,
gdje je
h
T
h
n
-1
=
=
max,
a
y
T
y
=
1
.
Ovaj se problem rješava pomoću
karakteristične jednadžbe
(C
h
-
I) y
=
0
,
gdje je
y
prvi svojstveni vektor, a
prva svojstvena vrijednost matrice
kovarijanci
C
h
.
Za ovaj način utvrđivanja ukupnog razultata predloženo je nakoliko
koeficijenata pouzdanosti:
Guttman-Nicewanderov koeficijent pouzdanosti (Guttman, 1945;
Nicewander, 1975)
1
1
6
.
Ovaj koeficijent, iako izveden pod pretpostavkom da se test sastoji
od beskonačnog broja čestica, može se smatrati stvarnom mjerom
pouzdanosti ako test ima velik broj čestica, što je gotovo uvijek
slučaj kod psihologijskih mjernih instrumenata. Međutim, mjerni
instrumenti koji se koriste za mjerenje kinezioloških fenomena
nemaju tako velik broj čestica pa se može dogoditi da se dobije
pouzdanost niža od one koja se dobije pod klasičnim modelom
mjerenja.
Kineziometrija – Metrijske karakteristike
300
Donja granica pouzdanosti (Momirović i Dobrić, 1977)
2
1
1
1
Gornja granica pouzdanosti (Zakrajšek, Momirović i Dobrić, 1977)
2
2
1
1
Prema Momiroviću i suradnicima (1999) ovaj koeficijent može
poslužiti za otkrivanje loših testova. Ako su vrijednosti ovog
koeficijenta niže od 0,90, tada se test s velikom sigurnošću može
smatrati nepouzdanim.
Momirovićeva donja granica pouzdanosti (Momirović, 1975),
izračunata na temelju omjera prve svojstvene vrijednosti matrice
kovarijanci varijabli transformiranih u image metriku (
) i prve
svojstvene vrijednosti matrice korelacija između čestica (
)
.
Momirović i suradnici (1999) smatraju da se ovaj koeficijent može
smatrati donjom granicom pouzdanosti i da stvarna pouzdanost
testa može biti znatno viših vrijednosti, a nikako nižih. Stoga, ako
su vrijednosti ovog koeficijenta visoke, test je sigurno pouzdan, ali
ako su vrijednosti ovog koeficijenta niske, test ne mora biti slabo
pouzdan.
Na kraju je moguće zaključiti da je za većinu kompozitnih mjernih
instrumenata koji se koriste u procjeni kinezioloških fenomena
(primjerice, antropometrijske i motoričke dimenzije), kod kojih su
čestice ponovljena mjerenja (što osigurava veliku sličnost aritmetičkih
sredina, standardnih devijacija i korelacija između čestica), opravdano
određivanje ukupnog rezultata u testu na najjednostavniji načina -
jednostavnim
zbrajanjem
rezultata
u
česticama,
odnosno
izračunavanjem aritmetičke sredine jer tako dobiveni rezultati nemaju
bitno manju pouzdanost u odnosu na znatno složenije postupke (prvu

Kineziometrija – Metrijske karakteristike
302
4.2.3. Homogenost
Homogenost
je svojstvo kompozitnih testova koje pokazuje koliko
rezultati ispitanika u svim česticama zavise od istog predmeta
mjerenja ili identične kombinacije različitih predmeta mjerenja.
Homogenost, kao metrijska karakteristika, ima važnu ulogu pri
opisivanju mjernih instrumenata jer o njoj ovisi dijagnostička
vrijednost testa. Naime, ako je neki test homogen to znači da se o
predmetu mjerenja jednoznačno može zaključivati, odnosno, ako je
test heterogen, usprkos mogućoj pragmatičnoj valjanosti, nije moguće
utvrditi u kojem omjeru različite sposobnosti ili osobine ispitanika
utječu na rezultat u testu. Stoga je, usprkos manjoj ekonomičnosti, u
praksi bolje koristiti više homogenih testova za predikciju neke
složene kriterijske varijable nego jedan heterogen test. To stoga jer je
moguće precizno utvrditi strukturu čimbenika odgovornih za
uspješnosti u kriterijskoj varijabli, odnosno moguće je doznati zašto
netko postiže bolje, a netko lošije rezultate u kriterijskoj varijabli, što
te testove čini upotrebljivima u dijagnostičke svrhe. Postoji više mjera
homogenosti kompozitnih testova od kojih će u ovoj knjizi biti
opisane sljedeće mjere:
prosječna korelacija između čestica
mjera homogenosti testa koja se temelji na broju glavnih
komponenata s pozitivnim koeficijentima pouzdanosti (Momirović i
Gredelj, 1980)
mjera homogenosti određena kao relativna vrijednost varijance prve
glavne komponente čestica transformiranih u image oblik
(Momirović, 1977).
Koeficijent homogenosti izveden na temelju prosječne korelacije
između čestica
Ova se mjera temelji na sasvim jasnoj pretpostavci da će korelacija
između čestica biti veća što čestice više procjenjuju isti predmet
mjerenja, odnosno korelacije između čestica bit će bliže nuli ako
čestice mjere više međusobno nezavisnih predmeta mjerenja.
Neka je
B
matrica u kojoj su rezultati
n
entiteta izmjereni nekim
kompozitnim testom sa
m
čestica
B
=
(b
ij
)
Matrica standardiziranih rezultata
Z
dobije se operacijom
Kineziometrija – Metrijske karakteristike
303
Z
=
(
B - PB
)
V
-1
,
gdje je
P
=
1(1
T
1)
-1
1
T
, a
V
2
=
diagC
dijagonalna matrica varijanci
čestica dobivena iz matrice kovarijanci čestica
C
=
(B
T
B-B
T
PB)
n
-1
.
Matrica korelacije između čestica dobije se operacijom
R
=
Z
T
Z
n
-1
pa se koeficijent homogenosti izračuna kao procječna korelacija
između čestica operacijom
m
m
r
h
2
1
I)1
(R
1
T
,
gdje je
1
sumacijski vektor sa
m
jedinica, a
I
matrica identiteta reda
m
.
Osnovni nedostatak ovako definiranog koeficijenta homogenosti jest u
tome što on u stvari, kao i koeficijent pouzdanosti, zavisi od varijance
greške te ga je teško razlikovati od koeficijenta pouzdanosti. Stoga je
predloženo više drugih koeficijenata homogenosti. Jedna jednostavna i
od pouzdanosti manje zavisna mjera utvrđuje se pomoću broja
svojstvenih vrijednosti korelacijske matrice većih od
1
.
Mjera homogenosti testa koja se temelji na broju glavnih
komponenata s pozitivnim koeficijentima pouzdanosti
Ova mjera homogenosti nekog testa određuje se na temelju broja
glavnih komponenata s pozitivnim koeficijentima pouzdanosti.
Rješavanjem
karakteristične jednadžbe korelacijske matrice
R
(
R
-
I
)
X =
0
dobije se matrica svojstvenih vektora
X
, za koju vrijedi da je
X
T
X
=
XX
T
=
I
, te dijagonalna matrica svojstvenih vrijednost
koje
predstavljaju varijance glavnih komponenata, za koje vrijedi da je
1
2
…
j
…
m
i
1
+
2
+ ……+
j
+…+
m
= m
,
a čija se pouzdanost utvrđuje Kaiser-Caffreyevim koeficijentom

Kineziometrija – Metrijske karakteristike
305
Neka je
R
matrica korelacija između varijabli-čestica nekog
kompozitnog mjernog instrumenta, onda je
1
1
2
)
diag
(
R
U
matrica uniknih varijanci svake varijable-čestice. Tada je matrica
pravih rezultata (image)
T
=
Z (I
-
U
2
R
-1
)
,
a matrica kovarijance između njih
G
=
T
T
T
n
-1
.
Ukupna varijanca pravih rezultata je
m
j
m
j
u
m
trag
trag
v
1
2
)
(
U
I
G
,
gdje su
u
j
2
(j=1...m)
unikne varijance čestica.
Ako se glavni predmet mjerenja odredi kao prva glavna komponenta
pravih rezultata (čestica transformiranih u image oblik), tada se
homogenost testa može izraziti formulom
v
h
3
,
gdje je
prva svojstvena vrijednosti matrice
G
koja je ujedno i varijanca
prve glavne komponente pravih rezultata, a
v
ukupna varijanca pravih rezultata.
Ovako definirana mjera homogenosti nije zavisna od pouzdanosti
(pogrešaka mjerenja) jer je dobivena na pravim rezultatima testa.
Osim toga, ona pokazuje koliki dio ukupne varijance iscrpljuje glavni
predmet mjerenja testa (određen prvom glavnom komponentom).
Tako, primjerice, test je potpuno homogen ako prva glavna
komponenta obuhvaća ukupnu varijancu testa (
h
3
= 1
jer je
= v
), a
što je test heterogeniji, to će
biti manja od
v
, a
h
3
će težiti nuli.
Kineziometrija – Metrijske karakteristike
306
4.3.4. Osjetljivost
Osjetljivost
predstavlja svojstvo mjernog instrumenta da uspješno
razlikuje ispitanike po predmetu mjerenja. Ako, primjerice, nekim
mjernim instrumentom dobijemo identične rezultate dvaju ispitanika,
to ne mora značiti i jednak stupanj razvijenosti predmeta mjerenja, već
može biti i znak slabije osjetljivosti mjernog instrumenta. Isto tako,
rezultat nula u broju zgibova ne mora značiti potpunu odsutnost
predmeta mjerenja (repetitivne snage), već je uzrok tome vjerojatno
slaba osjetljivost mjernog instrumenta, tj. njegova neprimjerenost
određenoj populaciji. To se često događa kada se neki mjerni
instrument konstruriran za selekcioniranu populaciju (vrhunski
sportaši), a primjenjuje se na neselekcioniranoj populaciji kojoj
instrument nije težinski primjeren.
Osjetljivost kineziologijskih mjernih instrumenta procjenjuje se na
temelju mjera disperzije (v. poglavlje 2.4.2, str. 74-86 i oblika
distribucije rezultata (v. poglavlja 2.4.3, str. 86-88 i 2.4.4, str. 88-89).
Slika 4.3-2 prikazuje distribucije rezultata ispitanika čiji je predmet
mjerenja procijenjen trima različitim testovima. Lako je uvidjeti da je
varijabilnost rezultata najveća u prvom testu, manja u drugom, a
najmanja u trećem. Stoga nije teško zaključiti da je prvi test
najosjetljiviji, drugi nešto manje, dok je treći test najmanje osjetljiv.
Slika 4.3-2.
Tri distribucije s različitom varijabilnosti rezultata
Ako se, primjerice, predmet mjerenja u populaciji normalno
distribuira, a rezultati dobiveni primjenom nekog mjernog instrumenta
1. test
2. test
3. test

Kineziometrija – Metrijske karakteristike
308
4.3.5. Valjanost
S obzirom na to da se mjerni instrumenti konstruiraju zato da
procjenjuju određeni predmet mjerenja koji može biti relativno
jednostavan (npr. neko morfološko obilježje), ali i vrlo složen (npr.
neka motorička sposobnost), postavlja se pitanje što u stvari određeni
mjerni instrument mjeri, odnosno kakva mu je
valjanost
.
S obzirom na cilj mjerenja, valjanost mjernih instrumenata možemo
promatrati sa dva osnovna stajališta:
Ako je cilj mjerenja utvrđivanje stanja, odnosno razine pojedinih
antropoloških obilježja nekog ispitanika, tada se radi o tzv.
dijagnostičkoj valjanosti
.
Ako je cilj mjerenja prognozirati uspješnost u nekoj aktivnosti na
temelju rezultata prikupljenih nekim mjernim instrumentom, tada se
radi o tzv.
pragmatičnoj
ili
prognostičkoj
valjanosti
.
4.3.5.1. Dijagnostička valjanost
Dijagnostičkoj valjanosti je osnovni cilj utvrditi što određeni test
mjeri, odnosno koji mu je predmet mjerenja. Prema načinu
utvrđivanja, moguće je razlikovati dva osnovna tipa dijagnostičke
valjanosti. To su
apriorna
i
faktorska
valjanost.
Apriorna valjanost
Kod
apriorne valjanosti
zaključivanje o predmetu mjerenja temelji se
na logičkoj analizi postupka mjerenja i testovnog sadržaja koji dovodi
do odgovarajuće reakcije ispitanika, što može sugerirati aktiviranje
neke hipotetske latentne dimenzije (predmeta mjerenja). Prema tome,
apriorna valjanost nije proizvod eksperimentalne provjere, pa se ni ne
izražava konkretnim koeficijentom valjanosti. Stoga se apriorna
valjanost obično koristi za postavljanje hipoteze o predmetu mjerenja
koja se potvrđuje ili opovrgava eksperimentalnom provjerom.
Kineziometrija – Metrijske karakteristike
309
Faktorska valjanost
Faktorska valjanost
nastoji utvrditi koji se predmet mjerenja ispituje
određenim mjernim instrumentom, odnosno u kojoj mjeri svaki od
njegovih faktora uvjetuje varijabilnost dobivenih rezultata. S obzirom
na to da se u pravilu jednim mjernim instrumentom želi procijeniti
jedan faktor, onda se faktorskom valjanošću utvrđuje koliko neki test
dobro mjeri onaj faktor za čije je mjerenje konstruiran. Kod faktorske
valjanosti zaključivanje o predmetu mjerenja temelji se na rezultatima
faktorske analize, odnosno eksperimentalno se utvrđuje kolikom
proporcijom neki faktor sudjeluje u varijanci rezultata testa.
Kako je već ranije rečeno, na rezultat dobiven mjerenjem nekog
entiteta
i
utječe veći broj čimbenika (faktora). To znači da rezultati
prikupljeni mjerenjem predstavljaju nesavršenu funkciju pravog
predmeta mjerenja i pogreške mjerenja. Stoga se svaki
izmjereni
rezultat
(
x
i
) može dekomponirati na tzv.
pravi rezultat
(
t
i
) i
pogrešku
mjerenja
(
e
i
).
x
i
= t
i
+ e
i
.
Ova pretpostavka je osnova teorije pouzdanosti, dok se teorija
faktorske valjanosti temelji na pretpostavci da pravi rezultat mjerenja
t
ne mora biti pod utjecajem samo jednog faktora, već može biti
determiniran većim brojem faktora, budući da se vrlo rijetko nekim
mjernim instrumentom mjeri učinak samo jednog izoliranog faktora.
Zato se pravi rezultat nekog entiteta
t
i
može predstaviti kao zbroj ili
jednostavna linearna kombinacija
k
faktora (
f
i1
+ f
i2
+…+ f
ik
), koji se
javljaju i u drugim testovima, i jednog specifičnog faktora koji je
karakterističan samo za određeni test (
f
s
)
t
i
= f
i1
+ f
i2
+…+ f
ik
+ f
is
.
Međutim, opravdana je pretpostavka da različiti faktori nejadnako
utječu na konačan rezultat. Stoga je u formulu moguće uvesti
koeficijente utjecaja svakog faktora na konačan rezultat
t
i
= a
1
f
i1
+ a
2
f
i2
+…+ a
k
f
ik
+ a
s
f
is
,
gdje su
a
j
(j=1,...,k)
koeficijenti relativnog utjecaja nekog faktora
j
na
na pravi rezultat. Prema tome, svaki izmjereni rezultat
x
i
može se

Kineziometrija – Metrijske karakteristike
311
Tako se pokazateljima faktorske valjanosti mogu smatrati veličine
komponenata komunaliteta jer svaka komponenta komunaliteta
predstavlja
koeficijent
determinacije
(
r
2
)
,
odnosno
kvadrat
koeficijenta korelacije pojedine varijable (testa) s pojedinim faktorom.
To se utvrđuje različitim modelima
faktorske analize
(v. poglavlje 3.2.
str. 214-237). Dakle, faktorska valjanost nekog novokonstruiranog
testa utvrđuje se korelacijom nekog testa s faktorima koji su definirani
kao linearne kombinacije rezultata većeg broja testova za koje se
pretpostavlja da imaju isti predmet mjerenja kao taj konkretni test.
Kvadrat dobivene korelacije, tj. koeficijent determinacije, govori o
veličini varijance rezultata testa koja se može pripisati djelovanju
zajedničkog faktora. Oduzimanjem komunaliteta od vrijednosti
1
dobije se unikvitet koji predstavlja proporciju dijela ukupne varijance
koji otpada na varijancu pogreške i specifični faktor tog testa. Što je
korelacija testa s faktorom za koji je test konstruiran veća, a manja sa
svim drugim faktorima, test je valjaniji te je moguće zaključiti da
dobro procjenjuje željeni predmet mjerenja.
4.3.5.2. Pragmatička valjanost
Pragmatička ili prognostička valjanost
nekog testa pokazuje koliko
uspješno, odnosno s kolikom sigurnošću možemo predvidjeti uspjeh u
nekoj praktičnoj aktivnosti na temelju rezultata tog testa. Primjerice,
kakva je mogućnost prognoziranja uspjeha u nekoj atletskoj disciplini
(npr. trčanju na 100 m) na temelju rezultata dobivenih upotrebom
nekog testa (npr. skoka udalj s mjesta). Dakle, problem pragmatičke
valjanosti svodi se na utvrđivanje neke mjere povezanosti između
varijable dobivene mjerenjem određene skupine entiteta nekim testom
(prediktorska ili nezavisna varijabla) i varijable koja opisuje
uspješnost tih entiteta u nekoj aktivnosti (kriterijska ili zavisna
varijabla). U kineziološkim istraživanjima, kriterijske i prediktorske
varijable mogu biti
jednodimenzionalne
i
višedimenzionalne
. Osim
toga mogu biti procijenjene nekom
kvalitativnom
ili
kvantitativnom
mjernom skalom. Upravo o navedenim karakteristikama varijabli ovisi
način utvrđivanja pragmatičke valjanosti. Stoga je moguće utvrđivati
pragmatičku valjanost:
jednog testa za jednodimenzionalni kvantitativni kriterij
skupa testova za jednodimenzionalni kvantitativni kriterij
skupa testova za višedimenzionalni kvantitativni kriterij
jednog testa za jednodimenzionalni kvalitativni kriterij
skupa testova za jednodimenzionalni kvalitativni kriterij.
Kineziometrija – Metrijske karakteristike
312
Pramatička valjanost jednog testa za jednodimenzionalni
kvantitativni kriterij
Ako uspješnost u nekoj aktivnosti izrazimo jednom kvantitativnom
varijablom, onda je pragmatičku valjanost jednog testa (čiji su
rezultati dobiveni na intervalnoj i omjernoj mjernoj ljestvici) moguće
utvrditi pomoću
jednostavne regresijske analize
(v. poglavlje 3.1.1,
str. 185-198), odnosno
Pearsonovim koeficijentom korelacije
(v.
poglavlje 2.11, str. 160-180). Međutim, uspješnost u većini
kinezioloških aktivnosti zavisi od većeg broja čimbenika, pa se vrlo
rijetko događa da jedan test ima zadovoljavajuću pragmatičku
valjanost. Stoga se češće utvrđuje pragmatička valjanost skupa testova
za neku kriterijsku aktivnost.
Pragmatička valjanost skupa testova za jednodimenzionalni
kvantitativni kriterij
Ako uspješnost ispitanika u nekoj aktivnosti izrazimo jednom
kvantitativnom varijablom, onda je pragmatičku valjanost skupa
testova (čiji su su rezultati dobiveni na intervalnoj i omjernoj mjernoj
ljestvici) moguće utvrditi
višestrukom regresijskom analizom
(v.
poglavlje 3.1.2, str. 199-204). Kao mjera pragmatičke valjanosti skupa
testova koristi se
multipla korelacija
, dok
standardizirani regresijski
koeficijenti
predstavljaju mjere pragmatičke valjanosti pojedinog testa.
Valja istaknuti da je koeficijent multiple korelacije uvijek jednak ili
veći od bilo kojega koeficijenta valjanosti pojedinog testa. Osim toga,
multipla korelacija bit će veća što su korelacije između testova
(prediktora) i kriterija veće, a interkorelacije između testova manje. To
je logično jer testovi koji su u međusobno niskim korelacijama, imaju
različitu faktorsku strukturu, odnosno faktori koji određuju uspjeh u
tim testovima ne postoje u drugima pa time imaju veću mogućnost
utjecaja na kriterijsku varijablu.
Pragmatičku valjanost skupa testova za višedimenzionalni
kvantitativni kriterij
Za adekvatnu procjenu uspješnosti u nekim kompleksnim
kineziološkim aktivnostima (primjerice, košarka, odbojka, rukomet
itd.) potrebno je uključiti veći broj kriterijskih varijabli (primjerice,
uspješnost košarkaša moguće je opisati pomoću većeg broja varijabli
kao što su: šuterska uspješnost, skakačka uspješnost u obrani i napadu,

Kineziometrija – Metrijske karakteristike
314
diskriminacijskim funkcijama). Mjeru pragmatičke valjanosti svake
diskriminacijske
funkcije
predstavlja
koeficijent
kanoničke
diskriminacije, dok se pragmatička valjanost pojedinog testa
procjenjuje putem njegove korelacije s diskriminacijskim funkcijama.
Tablice
317
Tablica B.
Kritične vrijednosti t-distribucije
df
t
0,05
t
0,01
1
12,706
63,657
2
4,303
9,925
3
3,182
5,841
4
2,776
4,604
5
2,571
4,032
6
2,447
3,707
7
2,365
3,499
8
2,306
3,355
9
2,262
3,250
10
2,228
3,169
11
2,201
3,106
12
2,179
3,055
13
2,160
3,012
14
2,145
2,977
15
2,131
2,947
16
2,120
2,921
17
2,110
2,898
18
2,101
2,878
19
2,093
2,861
20
2,086
2,845
21
2,080
2,831
22
2,074
2,819
23
2,069
2,807
24
2,064
2,797
25
2,060
2,787
26
2,056
2,779
27
2,052
2,771
28
2,048
2,763
29
2,045
2,756
30
2,042
2,750
31
2,040
2,744
32
2,037
2,738
33
2,035
2,733
34
2,032
2,728
35
2,030
2,724
36
2,028
2,719
37
2,026
2,715
38
2,024
2,712
39
2,023
2,708
40
2,021
2,704
45
2,014
2,690
50
2,009
2,678
55
2,004
2,668
60
2,000
2,660
65
1,997
2,654
70
1,994
2,648
80
1,990
2,639
90
1,987
2,632
100
1,984
2,626
1,960
2,576
t – distribucija
Tablice
318
Tablica C.
Kritične vrijednosti F - distribucije za razinu značajnosti 0,05
df
1
- stupnjevi slobode u stupcima,
df
2
– stupnjevi slobode u redcima
1
2
3
4
5
6
7
8
9
10
2
18,51
19,00
19,16
19,25
19,30
19,33
19,35
19,37
19,38
19,40
3
10,13
9,55
9,28
9,12
9,01
8,94
8,89
8,85
8,81
8,79
4
7,71
6,94
6,59
6,39
6,26
6,16
6,09
6,04
6,00
5,96
5
6,61
5,79
5,41
5,19
5,05
4,95
4,88
4,82
4,77
4,74
6
5,99
5,14
4,76
4,53
4,39
4,28
4,21
4,15
4,10
4,06
7
5,59
4,74
4,35
4,12
3,97
3,87
3,79
3,73
3,68
3,64
8
5,32
4,46
4,07
3,84
3,69
3,58
3,50
3,44
3,39
3,35
9
5,12
4,26
3,86
3,63
3,48
3,37
3,29
3,23
3,18
3,14
10
4,96
4,10
3,71
3,48
3,33
3,22
3,14
3,07
3,02
2,98
11
4,84
3,98
3,59
3,36
3,20
3,09
3,01
2,95
2,90
2,85
12
4-75
3,89
3,49
3,26
3,11
3,00
2,91
2,85
2,80
2,75
13
4,67
3,81
3,41
3,18
3,03
2,92
2,83
2,77
2,71
2,67
14
4,60
3,74
3,34
3,11
2,96
2,85
2,76
2,70
2,65
2,60
15
4,54
3,68
3,29
3,06
2,90
2,79
2,71
2,64
2,59
2,54
16
4,49
3,63
3,24
3,01
2,85
2,74
2,66
2,59
2,54
2,49
17
4,45
3,59
3,20
2,96
2,81
2,70
2,61
2,55
2,49
2,45
18
4,41
3,55
3,16
2,93
2,77
2,66
2,58
2,51
2,46
2,41
19
4,38
3,52
3,13
2,90
2,74
2,63
2,54
2,48
2,42
2,38
20
4,35
3,49
3,10
2,87
2,71
2,60
2,51
2,45
2,39
2,35
21
4,32
3,47
3,07
2,84
2,68
2,57
2,49
2,42
2,37
2,32
22
4,30
3,44
3,05
2,82
2,66
2,55
2,46
2,40
2,34
2,30
23
4,28
3,42
3,03
2,80
2,64
2,53
2,44
2,37
2,32
2,27
24
4,26
3,40
3,01
2,78
2,62
2,51
2,42
2,36
2,30
2,25
25
4,24
3,39
2,99
2,76
2,60
2,49
2,40
2,34
2,28
2,24
26
4,23
3,37
2,98
2,74
2,59
2,47
2,39
2,32
2,27
2,22
27
4,21
3,35
2,96
2,73
2,57
2,46
2,37
2,31
2,25
2,20
28
4,20
3,34
2,95
2,7
2,56
2,45
2,36
2,29
2,24
2,19
29
4,18
3,33
2,93
2,70
2,55
2,43
2,35
2,28
2,22
2,18
30
4,17
3,32
2,92
2,69
2,53
2,42
2,33
2,27
2,21
2,16
40
4,08
3,23
2,84
2,61
2,45
2,34
2,25
2,18
2,12
2,08
60
4,00
3,15
2,76
2,53
2,37
2,25
2,17
2,10
2,04
1,99
120
3,92
3,07
2,68
2,45
2,29
2,17
2,09
2,02
1,96
1,91
3,84
3,00
2,60
2,37
2,21
2,10
2,01
1,94
1,88
1,83
F – distribucija

Tablice
320
Tablica C.
Kritične vrijednosti F - distribucije za razinu značajnosti 0,05 (nastavak 2)
df
1
- stupnjevi slobode u stupcima
df
2
– stupnjevi slobode u recima
1
2
3
4
5
6
7
8
9
10
2
98,50
99,00
99,17
99,25
99,30
99,33
99,36
99,37
99,39
99,40
3
34,12
30,82
29,46
28,71
28,24
27,91
27,67
27,49
27,35
27,23
4
21,20
18,00
16,69
15,98
15,52
15,21
14,98
14,80
14,66
14,55
5
16,26
13,27
12,06
11,39
10,97
10,67
10,46
10,29
10,16
10,05
6
13,75
10,92
9,78
9,15
8,75
8,47
8,26
8,10
7,98
7,87
7
12,25
9,55
8,45
7,85
7,46
7,19
6,99
6,84
6,72
6,62
8
11,26
8,65
7,59
7,01
6,63
6,37
6,18
6,03
5,91
5,81
9
10,56
8,02
6,99
6,42
6,06
5,80
5,61
5,47
5,35
5,26
10
10,04
7,56
6,55
5,99
5,64
5,39
5,20
5,06
4,94
4,85
11
9,65
7,21
6,22
5,67
5,32
5,07
4,89
4,74
4,63
4,54
12
9,33
6,93
5,95
5,41
5,06
4,82
4,64
4,50
4,39
4,30
13
9,07
6,70
5,74
5,21
4,86
4,62
4,44
4,30
4,19
4,10
14
8,86
6,51
5,56
5,04
4,69
4,46
4,28
4,14
4,03
3,94
15
8,68
6,36
5,42
4,89
4,56
4,32
4,14
4,00
3,89
3,80
16
8,53
6,23
5,29
4,77
4,44
4,20
4,03
3,89
3,78
3,69
17
8,40
6,11
5,18
4,67
4,34
4,10
3,93
3,79
3,68
3,59
18
8,29
6,01
5,09
4,58
4,25
4,01
3,84
3,71
3,60
3,51
19
8,18
5,93
5,01
4,50
4,17
3,94
3,77
3,63
3,52
3,43
20
8,10
5,85
4,94
4,43
4,10
3,87
3,70
3,56
3,46
3,37
21
8,02
5,78
4,87
4,37
4,04
3,81
3,64
3,5'
3,40
3,31
22
7,95
5,72
4,82
4,31
3,99
3,76
3,59
3,45
3,35
3,26
23
7,88
5,66
4,76
4,26
3,94
3,71
3,54
3,41
3,30
3,21
24
7,82
5,61
4,72
4,22
3,90
3,67
3,50
3,36
3,26
3,17
25
7,77
5,57
4,68
4,18
3,85
3,63
3,46
3,32
3,22
3,13
26
7,72
5,53
4,64
4,14
3,82
3,59
3,42
3,29
3,18
3,09
27
7,68
5,49
4,60
4,11
3,78
3,56
3,39
3,26
3,15
3,06
28
7,64
5,45
4,57
4,07
3,75
3,53
3,36
3,23
3,12
3,03
29
7,60
5,42
4,54
4,04
3,73
3,50
3,33
3,20
3,09
3,00
30
7,56
5,39
4,51
4,02
3,70
3,47
3,30
3,17
3,07
2,98
40
7,31
5,18
4,31
3,83
3,51
3,29
3,12
2,99
2,89
2,80
60
7,08
4,98
4,13
3,65
3,34
3,12
2,95
2,82
2,72
2,63
120
6,85
4,79
3,95
3,48
3,17
2,96
2,79
2,66
2,56
2,47
6,63
4,61
3,78
3,32
3,02
2,80
2,64
2,51
2,41
2,32
F – distribucija
Tablice
321
Tablica C.
Kritične vrijednosti F - distribucije za razinu značajnosti 0,05 (nastavak 3)
df
1
- stupnjevi slobode u stupcima
df
2
– stupnjevi slobode u recima
12
15
20
24
30
40
60
120
2
99,42
9943
99,45
99,46
9947
99,47
99,48
99,49
99,50
3
27,05
26,87
26,69
26,60
26,50
26,41
26,32
26,22
26,13
4
14,37
14,20
14,02
13,93
13,84
13,75
13,65
13,56
13,46
5
9,89
9,72
9,55
9,47
9,38
9,29
9,20
9,11
9,02
6
7,72
7,56
7,40
7,31
7,23
7,14
7,06
6,97
6,88
7
6,47
6,31
6,16
6,07
5,99
5,91
5,82
5,74
5,65
8
5,67
5,52
5,36
5,28
5,20
5,12
5,03
4,95
4,86
9
5,11
4,96
4,81
4,73
4,65
4,57
4,48
4,40
4,31
10
4,71
4,56
4,41
4,33
4,25
4,17
4,08
4,00
3,91
11
4,40
4,25
4,10
4,02
3,94
3,86
3,78
3,69
3,60
12
4,16
4,01
3,86
3,78
3,70
3,62
3,54
3,45
3,36
13
3,96
3,82
3,66
3,59
3,51
3,43
3,34
3,25
3,17
14
3,80
3,66
3,51
3,43
3,35
3,27
3,38
3,09
3,00
15
3,67
3,52
3,37
3,29
3,21
3,13
3,05
2,96
2,87
16
3,55
3,41
3,26
3,18
3,10
3,02
2,93
2,84
2,75
17
3,46
3,31
3,16
3,08
3,00
2,92
2,83
2,75
2,65
18
3,37
3,23
3,08
3,00
2,92
2,84
2,75
2,66
2,57
19
3,30
3,15
3,00
2,92
2,84
2,76
2,67
2,58
2,49
20
3,23
3,09
2,94
2,86
2,78
2,69
2,61
2,52
2,42
21
3,17
3,03
2,88
2,80
2,72
2,64
2,55
2,46
2,36
22
3,12
2,98
2,83
2,75
2,67
2,58
2,50
2,40
2,31
23
3,07
2,93
2,78
2,70
2,62
2,54
2,45
2,35
2,26
24
3,03
2,89
2,74
2,66
2,58
2,49
2,40
2,31
2,21
25
2,99
2,85
2,70
2,62
2,54
2,45
2,36
2,27
2,17
26
2,96
2,81
2,66
2,58
2,50
2,42
2,33
2,23
2,33
27
2,93
2,78
2,63
2,55
2,47
2,38
2,29
2,20
2,10
28
2,90
2,75
2,60
2,52
2,44
2,35
2,26
2,17
2,06
29
2,87
2,73
2,57
2,49
2,41
2,33
2,23
2,14
2,03
30
2,84
2,70
2,55
2,47
2,39
2,30
2,21
2,11
2,01
40
2,66
2,52
2,37
2,29
2,20
2,11
2,02
1,92
1,80
60
2,50
2,35
2,20
2,12
2,03
1,94
1,84
1,73
1,60
120
2,34
2,19
2,03
1,95
1,86
1,76
1,66
1,53
1,38
2,18
2,04
1,88
1,79
1,70
1,59
1,47
3,32
3,00
F – distribucija

Tablice
323
Tablica E.
Kritične vrijednost u K-S testu
n
p=0,05
p=0,01
1
0,975
0,995
2
0,842
0,929
3
0,708
0,829
4
0,624
0,734
5
0,563
0,669
6
0,519
0,617
7
0,483
0,576
8
0,454
0,542
9
0,430
0,513
10
0,409
0,486
11
0,391
0,468
12
0,375
0,449
13
0,361
0,432
4
14
0,349
0,418
15
0,338
0,404
16
0,327
0,392
17
0,318
0,381
18
0,309
0,371
19
0,301
0,361
20
0,294
0,352
21
0,287
0,344
22
0,281
0,337
23
0,275
0,330
24
0,269
0,323
25
0,264
0,317
26
0,259
0,311
27
0,254
0,305
28
0,250
0,300
29
0,246
0,295
30
0,242
0,290
35
0,224
0,269
40
0,210
0,252
45
0,198
0,238
2
50
0,188
0,226
55
0,180
0,216
60
0,172
0,207
65
0,166
0,199
70
0,160
0,192
75
0,154
0,185
80
0,150
0,179
85
0,145
0,174
90
0,141
0,169
95
0,137
0,165
100
0,134
0,161
Tablice
324
Tablica F.
Kritične vrijednost koeficijenta korelacije r
df = n-2
p=0,05
p=0,01
3
0,878
0,959
4
0,811
0,917
5
0,754
0,874
6
0,707
0,834
7
0,666
0,798
8
0,632
0,765
9
0,602
0,735
10
0,576
0,708
11
0,553
0,684
12
0,532
0,661
13
0,514
0,641
14
0,497
0,623
15
0,482
0,606
16
0,468
0,590
17
0,456
0,575
18
0,444
0,561
19
0,433
0,549
20
0,423
0,537
21
0,413
0,526
22
0,404
0,515
23
0,396
0,505
24
0,388
0,496
25
0,381
0,487
26
0,374
0,478
27
0,367
0,470
28
0,361
0,463
29
0,355
0,456
30
0,349
0,449
35
0,325
0,418
40
0,304
0,393
45
0,288
0,372
50
0,273
0,354
60
0,250
0,325
70
0,232
0,302
80
0,217
0,283
90
0,205
0,267
100
0,195
0,254
125
0,174
0,228
150
0,159
0,208
200
0,138
0,181
300
0,113
0,148
400
0,098
0,128
500
0,088
0,115
1000
0,062
0,081

Literatura
326
13.
Durbin, J. & G.S. Watson (1951). Testing for Serial Correlation in Last
Squares Regression. Biometrika, 37, 409 – 428; 38, 159 – 178.
14.
Eckart, C. & G. Young (1936). The aproximation of one matrix by another
of lower rank. Psychometrika, 1(2), 211-218.
15.
Fulgosi, A. (1984). Faktorska analiza. Zagreb: Školska knjiga.
16.
Galton, F. (1888). Co-relations and their measurement, chiefly from
anthropometric data. Proceedings of the Royal Society 45: 135-145.
17.
Gjenero, I. i V. Vojvodić-Rosenzwieg (2000). Linearna algebra. Zagreb:
Hrvatska zajednica računovođa i financijskih djelatnika.
18.
Guilford, J. P. (1968). Osnove psihološke i pedagoške statistike. Beograd:
Savremena administracija.
19.
Guliksen, H. (1950). Theory of mental tests. New York: Wiley.
20.
Guttman, L. (1953). Image theory for the structure of quantitative variates.
Psychometrika, 18, 277-296.
21.
Harris, C. W. & H. F. Kaiser (1964). Oblique factor analytic solutions by
orthogonal transformations. Psychometrika, 29 (4), 347-362.
22.
Harman, H. H. (1960). Modern factor analysis. Chicago: University of
Chicago Press.
23.
Hotelling, H. (1931). The generalization of Student’s ratio, Annals of
Mathematical Statistics, 2, 360-378.
24.
Hotelling, H. (1933). Analysis of a complex of statistical variables into
principal componentes. Journal of Educational Psychology, 24, 417-441;
498-520.
25.
Hotelling, H. (1936). Relations between two sets variates. Biometrika, 28,
321-377.
26.
Ivanković, D., J. Božikov, J. Kern, B. Kopjar, G. Luković, S. Vuletić
(1989). Osnove statističke analize za medicinare. Zagreb: Medicinski
fakultet.
27.
Johnson, R. M. (1963). On a theorem stated by Eckart and Young.
Psychometrika, 28 (1), 259-263.
28.
Kaiser, H.F. (1958). The varimax criterion for analytic rotation in factor
analysis. Psychometrika, 25, 187-200.
Literatura
327
29.
Kaiser, H. F. & J. Caffrey (1965). Alpha factor analysis. Psychometrika,
30, 1-44.
30.
Kendall, M. G. (1975). Rank correlation methods (4th ed.). London:
Griffin.
31.
Krković, A. (1978). Elementi psihometrije 1. Zagreb: Filozofski fakultet.
32.
Krković, A., K. Momirović, B. Petz (1966). Odabrana poglavlja iz
psihometrije i neparametrijske statistike. Zagreb: Društvo psihologa
Hrvatske, Republički zavod za zapošljavanje.
33.
Kolesarić, V. i B. Petz (1999). Statistički rječnik. Jastrebarsko: Naklada
Slap.
34.
Larsen, W. A., & S. J. McCleary (1972). The use of partial residual plots
in regression analysis. Technometrics, 14, 781-790.
35.
Lilliefors, H. W. (1967). On the Kolmogorov-Smirnov test for normality
with mean and variance unknown. Journal of the American Statistical
Association, 64, 399-402.
36.
Lord, F. M. (1958). Same relations between Guttman’s principal
components of scale analysis and other psychometric theory. Psyhometrika
23,291-296.
37.
Lužar, V. (1976). Utjecaj raspona i razdiobe pogreške na određivanje broja
značajnih glavnih komponenata. (Magistarski rad). Zagreb: Elektrotehnički
fakultet.
38.
Marušić, M., M. Petrovečki, J. Petrak, A. Marušić (2000). Uvod u
znanstveni rad u medicini (2. izd.). Zagreb: Medicinska naklada.
39.
Mejovšek, M. (2003). Uvod u metode znanstvenog istraživanja u
društvenim i humanističkim znanostima. Jastrebarsko: Naklada Slap.
40.
Milas, G. (2005). Istraživačke metode u psihologiji i drugim društvenim
znanostima. Jastrebarsko: Naklada Slap.
41.
Momirović, K. (1977). Dvije alternativne definicije homogenosti mjernog
instrumenta. Psihologija, 1, 87-90.
42.
Momirović, K. (1984). Kvantitativne metode za programiranje i kontrolu
treninga. Zagreb: Fakultet za fizičku kulturu.
43.
Momirović, K., J. Štalec, F. Prot, K. Bosnar, N. Viskić-Štalec, L. Pavičić,
V. Dobrić (1984). Kompjuterski programi za klasifikaciju, selekciju,
programiranje i kontrolu treninga. Zagreb: Fakultet za fizičku kulturu.

Literatura
329
59.
Rao, C. R. (1965). Linear statistical inference and its applications. New
York: Wiley.
60.
Simonić, A. (1999). Znanost - najveća avantura i izazov ljudskog roda.
Rijeka: Vitagraf.
61.
Spearman, C. (1904). General intelligence, objectively determined and
measured. American Journal of Psychology, 15: 201-293
62.
Student (1908). The Probable Error of Mean. Biometrika, 6, 1-25.
63.
Šošić, I. (2004). Primijenjena statistika. Zagreg: Školska knjiga.
64.
Šošić, I. i V. Sedar (1992). Uvod u statistiku. Zagreb: Školska knjiga.
65.
Štalec, J. i K. Momirović (1971). Ukupna količina valjane varijance kao
osnov kriterija za određivanje broja značajnih glavnih komponenata.
Kineziologija, 1(1), 79-81.
66.
Thurstone, L. L. (1931). Multiple factor analysis. Psychological Review,
38, 406-427.
67.
Thurstone, L. L. (1938). Primary mental abilities. Chicago: University of
Chicago.
68.
Thurstone, L. L. (1947). Multiple factor analysis. Chicago: University of
Chicago.
69.
Vasilj, Đ. (2000). Biometrika i eksperimentiranje u bilinogojstvu. Zagreb:
Hrvatsko agronomsko društvo.
70.
Viskić - Štalec, N. (1991). Elementi faktorske analize. Zagreb: Fakultet za
fizičku kulturu.
71.
Viskić-Štalec, N.(1987). Usporedba različitih komponentnih i faktorskih
tehnika u određivanju latentnih motoričkih dimenzija. (Disertacija) Zagreb:
Fakultet za fizičku kulturu Sveučilišta u Zagrebu.
72.
Viskić-Štalec, N. (1997). Osnove statistike i kineziometrije. U D.
Milanović (ur.), Priručnik za sportske trenere (str. 349-432). Zagreb:
Fakultet za fizičku kulturu.
73.
Yule, G. U. (1897). On the theory of correlation. Journal of the Royal
Statistical Society, 60, 812-854.
Kazalo pojmova
330
Kazalo pojmova
A
alternativna hipoteza, 136
analiza čestica, 272
analiza kovarijance, 213
analiza varijance (ANOVA), 150
antiimage varijabla, 294
apriorna valjanost, 308
apsolutna nula, 265
aritmetička sredina, 64
autokorelacija, 208
B
Bartlettov
2
-test, 244
binomna distribucija, 100
bruto rezultat, 276
C
centralni granični teorem, 127
centroid, 247, 254
Cochran-Coxova metoda, 42
Cronbachov koeficijent pouzdanosti, 288
D
deskriptivna statistika, 41
deskriptivni pokazatelji, 63
determinanta matrice, 24
dijagnostička valjanost, 308
dijagonalna matrica, 15
direktno mjerenje, 261
diskretna varijabla, 48
diskretne distribucije, 99
diskriminacijska analiza, 251
diskriminacijska funkcija, 252
distribucija frekvencija, 58
donja granica pouzdanosti, 300
Durbin-Watsonov test, 209
E
eksplorativna primjena, 218
elementarni događaj, 91
empirijske distribucije, 90
entitet, 45
euklidska udaljenost, 22
F
faktorska analiza, 214
faktorska valjanost, 309
faktorski model, 218
F-distribucija, 109
G
generalne image transformacije, 212
generalni linearni model, 217
GK-kriterij, 224
gornja granica pouzdanosti, 300
grafikon redaka, 55
grafikon stupaca, 55
grupiranje podataka, 52
Guttman-Nicewanderov koef. pouzd.,299
Guttmanov model mjerenja, 293
H
Hadamarovo množenje, 19
Harrisova metrika, 298
- distribucija, 110
hipoteze, 135
histogram frekvencija, 59
homogenost, 302
Hotellingova T
2
- vrijednost, 250
I
image torija, 293
image varijabla, 294
indeks korelacije, 169
indeks lakoće (težine), 272
indirektno mjerenje, 261
inferencijalna statistika, 42, 135
interkvartil, 76
interval razreda, 60
intervalna skala, 265
intervalni uzorak, 47
inverz matrice, 27
J
jednadžba pravca, 186
jednodimenzionalno grupiranje, 53
jednostavna linearna kombinacija, 24
jednostavna sumacija, 284
jednostavni slučajni uzorak, 46
jedostavna struktura, 228
K
Kaiser-Caffreyev koef. pouzdanosti, 291
kanonička analiza, 238
kanonička korelacija, 240
kanonički faktori, 239
karakteristična jednadžba, 221
keficijent determinacije, 168
kineziološka informatika, 9
kineziološka metodologija, 9
kineziološka statistika, 9
kineziometrija, 9, 260
klasični model mjerenja, 275
kodiranje podataka, 52
koeficijent kanoničke diskriminacije, 256

Kazalo pojmova
332
podatak, 44
pogreška tipa I (alfa), 136
pogreška tipa II (beta), 136
Poissonova distribucija, 102
poligon frekvencija, 59
populacija (univerzum) varijabli, 49
populacija entiteta, 45
potpuna negativna korelacija, 165
potpuna pozitivna korelacija, 165
pouzdanost, 274
pozitivno asimetrična distribucija, 87
pragmatička valjanost, 311
pravi rezultat, 276
pravilo kombinacija, 97
pravilo množenja, 91
pravilo permutacija, 92
pravilo varijacija, 95
prediktorska varijabla, 185
predmet mjerenja, 262
prigodni uzorak, 46
princip parsimonije, 214
produkt-moment koef. korelacije, 161
prognozirana suma kvadrata, 193
prostor elementarnih događaja, 91
prvi (donji) kvartil, 76
pseudoinverz matrice, 31
R
rang matrice, 32
redundancija, 242
regresijska analiza, 182
regresijska funkcija, 183
regularna matrica, 30
relativna frekvencija, 54
relativne rezidualne vrijednosti, 191
rezidualna suma kvadrata, 193
rezidualne vrijednosti, 191
S
sampling distribucija, 125
scree plot, 226
scree test, 226
silazno sortiranje, 56
simetrična matrica, 14
singularna matrica, 30
sistematske pogreške, 274
skalarna matrica, 15
slučajni uzorak, 46
sortiranje podataka, 56
Spearman-Brownov koef. pouzd., 286
spektralna dekompozicija, 221
split-half metoda, 289
središnje mjere, 63
stadnardna pogreška mjerenja, 282
standardizacija podataka, 114
standardizirani diskrimin. koef., 253
standardizirani regresijski koef., 202
standardna devijacija, 77
standardna pogreška aritm. sredine, 128
standardna pogreška prognoze, 193
standardna pogreška razlika, 139
statistički značajna razlika, 137
statistika, 40
stratificirani uzorak, 47
struktura kanoničkih faktora, 241
strukturni krug, 56
supresori, 203
svojstvene vrijednost, 35
svojstveni vektori, 35
T
tablica podataka, 51
t-distribucija, 107
teoretske distribucije, 90
teorija vjerojatnosti, 91
totalni raspon rezultata, 57, 76
trag matrice, 20
transponirana matrica, 14
treći (gornji) kvartil, 76
t-test, 137
t-test za nezavisne uzorke, 137
t-test za zavisne uzorke, 145
U
ukupna suma kvadrata, 193
uniformna distribucija, 99
unikviteti, 227
univarijatna analiza varijance, 150
univarijatne metode, 42
uzlazno sortiranje, 56
uzorak entiteta, 46
uzorak varijabli, 49
V
valjanost, 308
varijabla, 47
varijanca, 77
varijanca reziualnih rezultata, 193
varimax, 230
vektor, 13
vektor retka, 13
vektor stupca, 13
višedimenzionalno grupiranje, 53
vjerojatnost, 98
Z
zavisna (kriterijska) varijabla, 48, 185
zbrajanje matrica, 16
z-vrijednost, 114
Pojmovnik
333
Pojmovnik
A
1.
analiza kovarijance
(engl.
analysis of covariance,
ANCOVA) - analiza
varijance ili diskriminacijska analiza izvedena tako da se iz analiziranog skupa
varijabli parcijalizira utjecaj nekog drugog skupa varijabli koji ima logički
status smetnji (Momirović, Gredelj i Sirovicza, 1977).
2.
analiza čestica
(engl.
item analysis
) - postupci kojima se procjenjuje težina
(npr. indeksom lakoće) i valjanost (npr. prosječnom korelacijom između
čestica) čestica kako bi se došlo do konačnog oblika testa.
3.
apriorna valjanost
(engl.
a priori validity
) - oblik dijagnostičke valjanosti kod
koje se zaključivanje o predmetu mjerenja temelji na logičkoj analizi postupka
mjerenja i testovnog sadržaja koji dovodi do odgovarajuće reakcije ispitanika,
što može sugerirati aktiviranje neke hipotetske latentne dimenzije (predmeta
mjerenja). Apriorna valjanost nije proizvod eksperimentalne provjere, pa se
obično koristi za postavljanje hipoteze o predmetu mjerenja koja se potvrđuje ili
opovrgava eksperimentalnom provjerom.
4.
apsolutna nula (
engl.
absolute zero point
) - potpuna odsutnost mjerenog
svojstva.
5.
aritmetička sredina
ili
prosječna vrijednost
(engl.
mean
) - mjera centralne
tendencije koja se izračunava kao omjer zbroja svih vrijednosti neke varijable i
ukupnog broja entiteta.
n
x
x
n
i
i
1
gdje je
i = 1,…,n,
a
n
predstavlja broj entiteta.
B
6.
binomna distribucija
(engl.
binomial distribution
) - diskretna teoretska
distribucija. Slučajna varijabla
x
ima
binomnu distribuciju
s parametrima
n
i
p
ako je
x
n
x
x
n
x
q
p
x
n
x
n
q
p
x
n
x
f
)!
(
!
!
)
(
,
gdje je
f(x)
vjerojatnost
x
za uspješne ishode od
n
svih mogućih ishoda koje
može imati slučajna varijabla
x
,
p
vjerojatnost uspješnog ishoda, a
q
vjerojatnost neuspješnog ishoda (
q=1- p
).
Binomna distribucija za n = 10 i p = q = 0,5

Pojmovnik
335
mjerenog svojstva s određenom veličinom tog istog svojstva koja se dogovorom
odredi kao jedinica mjere (npr. metar, milja, kilogram i sl.).
16.
diskretna varijabla
(engl.
discrete variable
) - kvantitativna varijabla kod koje
su vrijednosti mjerenog svojstva određene cijelim brojem. Dobiva se postupkom
prebrojavanja (npr. broj sklekova, broj skokova u obrani i napadu...).
17.
diskriminacijska analiza
(engl.
discriminant analysis
) - multivarijatna metoda
kojom se utvrđuje statistička značajnost razlika među više grupa entiteta
mjerenih u više varijabli, pri čemu se utvrđuje koliko se grupe međusobno
razlikuju i koliko pojedine varijable pridonose toj razlici, a moguće je i
prognozirati pripadnost pojedinog entiteta grupi.
18.
diskriminacijska funkcija
(engl.
discriminant function
) - latentna varijabla
koja se dobije linearnom kombinacijom manifestnih varijabli u okviru
diskrimainacijske analize i to tako da maksimalno razlikuje analizirane grupe
entiteta.
19.
distribucija frekvencija
(engl.
frequency distribution
) - uređeni niz
kvantitativnih vrijednosti s pripadajućim frekvencijama.
20.
Durbin-Watsonov test
(engl.
Durbin-Watson test
) - test za testiranje
(utvrđivanje statističke značajnosti) autokorelacija rezidualnih odstupanja prvog
reda.
E
21.
elementarni događaj
- svaki od
n
mogućih ishoda nekog eksperimenta,
odnosno
realizacije nekog slučajnog događaja
(primjerice, bacanje na koš s
linije slobodnih bacanja, bacanje igraće kocke, bacanje novčića…).
22.
empirijska distribucija
(engl.
empirical distribution
) - distribucija
eksperimentalno prikupljenih podataka.
23.
entitet
(engl.
entity
) - jedinka nekog skupa osoba, objekata, stvari, pojava,
procesa itd., nositelj informacija koje je moguće prikupiti nekim postupkom
mjerenja. U kineziološkim istraživanjima entiteti su najčešće ljudi, ali mogu biti
i sportske ekipe, tehnički elementi, zadaci u igri itd.
24.
euklidska udaljenost
(engl.
euclidean distance
) - udaljenost između dva
vektora (
a
i
b
) istog reda koja se izračuna kao norma razlike dvaju vektora.
2
1
2
/
1
)
(
b
a
i
n
i
i
T
b
a
d
b
a
b
a
F
25.
faktorska analiza
(engl.
factor analysis
) - zajedničko ime za više metoda
kojima je zajednički cilj kondenzacija većeg broja manifestnih varijabli, među
kojima postoji povezanost (korelacija), na manji broj latentnih dimenzija ili
faktora.
Manifestne varijable
dobivene su mjerenjem, dok
latentne dimenzije
Pojmovnik
336
nisu izravno mjerljive postojećim mjernim instrumentima, već se dobivaju
linearnom kombinacijom manifestnih varijabli.
26.
faktorska valjanost
(engl.
factor validity
) - oblik dijagnostičke valjanosti kod
koje se eksperimentalno (faktorskom analizom) utvrđuje što je predmet
mjerenja određenog mjernog instrumenta, odnosno, u kojoj mjeri svaki od
njegovih faktora uvjetuje varijabilnost dobivenih rezultata.
27.
F-distribucija
(engl.
F-distribution
) - kontinuirana teoretska distribucija.
Slučajna kontinuirana varijabla
F
ima
F-distribuciju s parametrom
df
1
i
df
2
ako
je
2
/
)
df
df
(
2
1
1
)
2
/
df
(
2
df
2
1
2
1
2
1
2
1
1
1
F
df
df
1
F
df
df
2
df
2
df
2
df
df
)
F
(
f
gdje su
df
1
i
df
2
stupnjevi slobode (
df
1
=1,2,…i df
2
=1,2,…
), a
gama funkcija.
F-distribucija za df
1
= 5, df
2
= 5 i za df
1
= 10, df
2
= 10
G
28.
GK-kriterij
(engl.
Guttman-Kaiser criterion
) - kriterij za odabir značajnog
broja glavnih komponenata. Prema GK-kriteriju značajanima se smatraju samo
one komponente čija je svojstvena vrijednost (varijanca) veća od ili je jednaka
jedan.
29.
grafikon retka
(engl.
horizontal bar/column graph
) -
površinski grafikon koji
se crta u pravokutnom koordinatnom sustavu. Na osi
y
nalaze se kategorije, a na
osi
x
nalaze se frekvencije. Pravokutnici su jednakih osnovica (visina), a duljina
im je određena pripadajućom frekvencijom.
Grafikon redaka
Grafikon retka
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
df
1
=5
df
2
=5
df
1
=10
df
2
=10
0
5
10
15
20
25
30
nedovoljan
dovoljan
dobar
vrlo dobar
odličan

Pojmovnik
338
F
re
k
v
e
n
c
ij
a
0
5
10
15
20
25
30
35
120
140
160
180
200
220
gdje je
1
1
2
)
diag
(
R
U
matrica uniknih dijelove varijanci svake čestice s
preostalim varijablama iz promatranog skupa. Harrisova ili univerzalna metrika
invarijantna je na promjene u skaliranju varijabli te predstavlja najpovoljniji
oblik transformacije rezultata u česticama nekog testa jer optimalno ponderira
rezultate u česticama (proporcionalno faktorskoj valjanosti čestica), čime se
ukupni rezultat u testu izračunava s maksimalnom pouzdanošću (Momirović i
sur., 1999).
36.
hipoteza
(engl.
hypothesis
) - predpostavka koja se provjerava pomoću
odgovarajućeg statističkog testa, pri čemu se odluka o prihvaćanju ili
neprihvaćanju nulte/alternativne hipoteze donosi uz određenu pogrešku. Nulta
hipoteza se postavlja niječno (primjerice, nije nađena statistički značajna razlika
između aritmetičkih sredina grupe A i B), dok se alternativna hipoteza
suprotstavlja (proturječi) nultoj hipotezi (primjerice, razlika između aritmetičkih
sredina grupe A i B statistički je značajna).
37.
2
-distribucija
(engl.
chi-square distribution
) - kontinuirana teoretska
distribucija. Slučajna varijabla
x
ima
2
-distribuciju s parametrom
df
ako je
2
/
1
2
/
2
/
2
/
2
1
)
(
x
df
df
e
x
df
x
f
,
gdje je
df
broj stupnjeva slobode (
df = 1,2,…
),
gama funkcija,
e
=2,71828.
0,00
0,02
0,04
0,06
0,08
0,10
0,12
0,14
0,16
0,18
0,20
0
2
4
6
8
10
12
14
16
18
20
22
24
2
- distribucija za broj stupnjeva slobode df=5
38.
histogram frekvencija
(engl.
frequency
histogram
) - površinski grafički prikaz
distribucije frekvencija crta se tako da osnovicu pravokutnika određuje interval
razreda, a visinu frekvencija pojedinog razreda.
Histogram frekvencija s 5 razreda
39.
homogenost
(engl.
homogeneity
) - metrijska karakteristika koja pokazuje
koliko rezultati ispitanika u svim česticama zavise od istog predmeta mjerenja
ili identične kombinacije različitih predmeta mjerenja.
Pojmovnik
339
40.
Hotellingov T
2
test
(engl.
Hotelling’s T
2
test
) - multivarijatni test kojim se
utvrđuje statistička značajnost razlika između dviju grupa. Bazira se na
multivarijatnom testiranju razlika između aritmetičkih sredina dviju grupa na
osnovi matrice unutargrupnih kovarijanci.
2
2
1
2
1
2
d
n
n
n
n
T
gdje je
d
2
= (
m
1
–
m
2
)
T
C
-1
(
m
1
– m
2
)
euklidska udaljenost između vektora
aritmetičkih sredina (centroida) prve i druge grupe
,
m
1
i
m
2
centroidi prve i
druge grupe,
C
zajednička matrica kovarijanci,
n
1
i
n
2
broj entiteta u prvoj i
drugoj grupi. Zbog složenosti distribucija T
2
-vrijednosti transformira se
formulom (Rao, 1952)
2
2
1
2
1
T
)
2
n
n
(
m
1
m
n
n
F
koja ima F-distribuciju sa stupnjevima slobode
df
1
= m
i
df
2
= (n
1
+ n
2
- m - 1),
pomoću koje je moguće testirati statističku značajnost razlika tih dviju grupa.
I
41.
indirektno mjerenje
(engl.
indirect measurement
) - mjerenje u kojem predmet
mjerenja i mjerna jedinica nemaju ista svojstva (npr. mjerenje elekričnog
napona, temperature nekog objekta...). Kod indirektnog mjerenja veličina
predmeta mjerenja određuje se pomoću njegova utjecaja na druge objekte koji
mijenja njihova svojstva, pa je na temelju izazvanih promjena moguće odrediti
veličinu mjerenog svojstva ako između predmeta mjerenja i izazvanih promjena
postoji neka stalna veza (relacija, odnos).
42.
inferencijalna statistika
(engl.
inferential statistics
)
- statistički postupci
kojima se, na temelju rezultata dobivenih na uzorku s oslanjanjem na teoriju
vjerojatnosti proširuju, zaključci na populaciju koje je uzorak reprezentant. U
ovu skupinu statističkih metoda ubrajaju se
t
-test, univarijatna analiza varijance,
multivarijatna analiza varijance, postupci za testiranje statističke značajnosti
koeficijenta korelacije, multiple korelacije, kanoničke korelacije, regresijskih
koeficijenata itd.
43.
interkvartil
(engl.
interquartile range
) - mjera varijablinosti koja se izračunava
kao razlika između trećeg i prvog kvartila, a predstavlja raspon rezultata
preostalih 50% članova nakon što se izuzmu prva i zadnja četvrtina članova
sortiranog niza.
Prvi kvartil
je vrijednost koja uređeni niz podataka dijeli na 1/4
članova s manjom ili jednakom vrijednosti, odnosno 3/4 članova s većom ili
jednakom vrijednosti, a
treći kvartil
je vrijednost koja uređeni niz podataka
dijeli na 3/4 članova s manjom ili jednakom vrijednosti, odnosno 1/4 članova s
većom ili jednakom vrijednosti.
44.
intervalna skala
(engl.
interval scale
) - ima kvantitativna svojstva i kontinuitet.
Osim što utvrđuju redoslijed, intervali uzduž skale su jednaki (ekvidistantni), a
nulta vrijednost je određena dogovorom (primjerice, kod mjerenja temperature u

Pojmovnik
341
52.
kanonička korelacija
(engl.
canonical correlation
) - maksimalno moguća
korelacija između faktora koji čine jedan kanonički par.
53.
kanonički faktori
(engl.
canonical factors
) - predstavljaju linearne kombinacije
(kompozite) varijabli jednoga i drugog skupa. Svaki par kanoničkih faktora
sastoji se od jednoga kanoničkog faktora iz prvoga i jednoga kanoničkog
faktora iz drugog skupa manifestnih varijabli. Pri tome je prvi par kanoničkih
faktora dobiven pod uvjetom da bude u najvećoj mogućoj korelaciji. Za svaki
sljedeći par kanoničkih faktora vrijedi isto što i za prvi, ali pod uvjetom da ne
smije biti u korelaciji ni s jednim prethodno izvedenim parom kanoničkih
faktora. Broj parova kanoničkih faktora jednak je broju varijabli u manjem
skupu.
54.
koeficijent determinacije
(engl.
determination coefficient
) - predstavlja
proporciju zajedničkog varijabiliteta dviju varijabli.
= r
2
gdje je
r
koeficijent korelacije.
Koeficijent determinacije pomnožen sa
100
daje postotak kojim se može
predviđati rezultat u jednoj varijabli ako nam je poznat rezultat u drugoj
varijabli.
55.
kineziološka informatika
- proučava mogućnosti primjene elektroničkih
računala za analizu podataka u kineziološkim istraživanjima te u pojedinim
područjima primijenjene kineziologije (Mraković, 1992).
56.
kineziološka metodologija
- predstavlja međuzavisni skup disciplina koje
proučavaju principe, sustave i postupke mjerenja, prikupljanja i obrade
podataka i upotrebe elektroničkih računala u rješavanju tipičnih kinezioloških
problema. To su:
kineziometrija
,
kineziološka statistika
i
kineziološka
informatika
(Mraković, 1992).
57.
kineziološka statistika
- proučava metode za transformaciju prikupljenih
podataka u oblik koji omogućava jasnije prikazivanje i interpretaciju te
testiranje postavljenih hipoteza u području kineziologije.
58.
kineziometrija
- proučava probleme mjerenja, odnosno, konstrukcije i
evaluacije mjernih instrumenata za procjenu kinezioloških fenomena.
59.
klasični model mjerenja
- izveden je na pretpostavci o postojanju tzv.
paralelnih testova
(mjerni postupci koji u jednakom stupnju izazivaju i mjere
isti predmet mjerenja, a to znači da imaju jednake aritmetičke sredine,
standardne devijacije i interkorelacije). Klasični model mjerenja polazi od
pretpostavki da su pogreške mjerenja međusobno nezavisne, da su pravi
rezultati i pogreške mjerenja istog testa međusobno nezavisni te da su pravi
rezultati jednog testa nezavisni od pogrešaka mjerenja u drugom testu.
60.
koeficijent kanoničke diskriminacije
- predstavlja korelaciju između
diskriminacijske funkcije i binarne varijable kojom je određena pripadnost
pojedinog entiteta grupi. Veći koeficijent kanoničke diskriminacije znači veće
Pojmovnik
342
mogućnosti razlikovanja grupa na temelju pripadajuće diskriminacijske
funkcije.
61.
koeficijent pouzdanosti
(engl.
reliability coefficient
) - formalno predstavlja
korelaciju između dva paralelna testa, odnosno omjer varijance pravih rezultata
i varijance bruto rezultata.
2
2
t
tt
r
gdje je
2
t
varijanca pravih rezultata, a
2
varijanca bruto rezultata.
Tako definiran koeficijent ne može se izračunati jer su varijance pravih
rezultata i varijance pogreške nepoznate pa se koeficijent pouzdanosti
aproksimativno određuje
metodom test-retest
,
metodom tau-ekvivalentnih
testova
i
metodom interne konzistencije
.
62.
koeficijent varijabilnosti
(engl.
variability coefficient
) - relativna mjera
disperzije ili varijabilnosti koja pokazuje koliki postotak vrijednosti aritmetičke
sredine iznosi standardna devijacija.
100
x
σ
V
gdje je
standardna devijacija,
x
aritmetička sredina
63.
Kolmogorov - Smirnovljev test
(engl.
Kolmogorov - Smirnov test
) - statistički
postupak za utvrđivanje normaliteta neke empirijske distribucije. Temelji se na
usporedbi empirijskih relativnih kumulativnih frekvencija i teoretskih relativnih
kumulativnih frekvencija.
64.
komponentni model
(engl.
principal components
) - jedan od najčešće
korištenih modela faktorske analize koji je predložio je Harold Hotelling 1933.
godine. Ovim modelom se iz skupa manifestnih varijabli utvrđuju linearno
nezavisne komponente na temelju nereducirane korelacijske matrice (u glavnoj
dijagonali su jedinice), što omogućava objašnjenje ukupne varijance analizira-
nog skupa manifestnih varijabli pomoću dobivenih komponenata. Pri tome se
postiže da prva ekstrahirana komponenta objašnjava maksimalno moguć dio
ukupne varijance, druga maksimalno moguć dio preostale varijance itd. Takav
postupak omogućava da svaka sljedeća komponenta objašnjava manju
proporciju varijance od prethodno ekstrahirane komponente pa se minimalnim
brojem komponenata može objasniti maksimalna količina ukupne varijance
manifestnih varijabli.
65.
kompozitni mjerni instrument
(engl.
composite measuring instrument
) -
mjerni instrument koji se sastoji od više čestica (pitanja, zadataka, ponovljanih
mjerenja).
66.
komunalitet
(engl.
communaliti
) - dio ukupne varijance manifestne varijable
koji je moguće objasniti pomoću značajnih komponenata.
67.
kontinuirana varijabla
(engl.
continuons variable
) - može poprimiti bilo koju
numeričku vrijednost.

Pojmovnik
344
77.
metodologija
(engl.
methodology
)
-
sustav pravila na temelju kojih se provode
istraživački postupci, izgrađuju teorije i obavlja njihova provjera, a cilj joj je
opis i analiza temeljnih metoda što se koriste u različitim znanstvenim
disciplinama, upoznavanje s njihovim prednostima i ograničenjima,
pretpostavkama na kojima počivaju i mogućim ishodima njihove upotrebe
(Milas, 2005).
78.
metrijske karakteristike
(engl.
metric characteristics
) - svojstva mjernog
instrumenta. To su: pouzdanost, objektivnost, homogenost, osjetljivost i
valjanost.
79.
mjere centralne tendencije
(engl.
measures of central tendency
) - despriptivni
pokazatelji čije je zajedničko obilježje da svaka od njih predstavlja jednu
vrijednost koja bi trebala biti dobra zamjena za skup svih pojedinačnih
vrijednosti, odnosno njihov najbolji reprezentant. To su:
aritmetička sredina
,
geometrijska sredina
,
harmonijska sredina
,
mod
i
medijan
. S obzirom na
prirodu varijabli, u kineziološkim istraživanjima najčešće se koriste aritmetička
sredina, mod i medijan, dok se ostale mjere centralne tendencije rijetko
primjenuju.
80.
mjere varijabilnosti ili disperzije
(engl.
measures of variability or dispersion
)
- deskriptivni pokazatelji kojima procjenjujemo raspršenje rezultata oko neke
središnje vrijednosti (najčešće aritmetičke sredine). Za opis disperzije varijabli u
kineziološkim istraživanjima najčešće se koriste
totalni raspon
,
interkvartil
,
varijanca
i
standardna devijacija
.
81.
mjerenje
(engl.
measurement
) - postupak kojim se objektima (entitetima,
ispitanicima) pridružuju brojevi ili oznake prema određenim pravilima u skladu
s razvijenosti mjerenog svojstva (aributa, karakteristike, obilježja) čime se
postiže njegova kvantifikacija ili klasifikacija.
82.
mjerne skale
(engl.
measurement scales
) - određene su svojstvima brojčanog
sustava koja određuju pravila pridjeljivanja brojeva pojavama. Ta su pravila:
određivanje identiteta (nominalna skala), određivanje redoslijeda (ordinalna
skala), utvrđivanje razlika (intervalna skala) i utvrđivanje omjera (omjerna
skala). Ovim pravilima ujedno je određena i razina mjerenja koja je definirana
dopustivim transformacijama koje skalu ostavljaju invarijatnom. Drugačije
rečeno, skalu definira mogućnost manipuliranja brojčanim vrijednostima koje
neće promijeniti empirijske informacije dobivene transponiranjem mjerenih
pojava u vrijednost skale (Kolesarić i Petz, 1999).
83.
mjerni instrument ili test
(engl.
measuring instrument
) - odgovarajući operator
pomoću kojega se određuje pozicija objekta mjerenja na nekoj mjernoj skali
kojom se procjenjuje predmet mjerenja. Konačni rezultat mjernog instrumenta
ukazuje na stupanj razvijenosti predmeta mjerenja.
Pojmovnik
345
84.
mod ili dominantna vrijednost
(engl.
mode
) - vrijednost kvalitativne ili
kvantitativne varijable koja se najčešće pojavljuje, odnosno koja je najveće
frekvencije.
85.
Momirovićeva donja granica pouzdanosti
– izračuna se kao omjer prve
svojstvene vrijednosti matrice kovarijanci varijabli transformiranih u image
metriku (
) i prve svojstvene vrijednosti matrice korelacija između čestica (
)
Ako su vrijednosti ovog koeficijenta visoke, test je sigurno pouzdan, ali ako su
vrijednosti ovog koeficijenta niske, test ne mora biti slabo pouzdan (Momirović i
sur., 1999).
86.
multipla korelacija
(engl.
multiple correlation
) - predstavlja mjeru povezanosti
skupa nezavisnih varijabli i zavisne varijable.
87.
multivarijatna analiza varijance
(engl
. multivariate analysis of variance,
MANOVA) - statistička metoda za utvrđivanje statističke značajnosti razlika
dviju ili više grupa entiteta mjerenih u dvije ili više varijabli.
88.
multivarijatne metode
(engl.
multivariate methods
) -
statističke metode koje se
koriste za istovremenu analizu podataka dviju ili više varijabli uz uvažavanje
njihova
međusobna
odnosa
(faktorska
analiza,
regresijska
analiza,
diskriminacijska analiza…).
N
89.
asimetrična distribucija
(engl.
asimmetrical distribution
)
-
distribucija kod
koje je grupiranje entiteta u zoni viših (negativno asimetrična distribucija) ili
nižih (pozitivno asimetrična distribucija) vrijednosti.
Negativno asimetrična distribucija Pozitivno asimetrična distribucija
90.
neortogonalna rotacija
(engl.
non-orthogonal rotation
) - transformacija
inicijalnoga koordinatnog sustava bez zadržavanja ortogonalnosti između
faktora.

Pojmovnik
347
98.
objektivnost
(engl.
objectivity
) - mjerna karakteristika kojom se određuje
nezavisnost rezultata mjerenja od mjerioca. Postupak mjerenja smatra se
objektivnim ako različiti mjerioci, mjereći iste ispitanike, dolaze do istih
rezultata. Što je veći stupanj slaganja između rezultata ispitanika koje su dobili
različiti mjerioci, to je objektivnost mjerenja veća.
99.
omjerna skala
(engl.
ratio scale
) - uza sva svojstva intervalne mjerne skale,
ima još i apsolutnu nulu (potpuna odsutnost mjerenog svojstva), odnosno,
rezultati su izraženi od nulte vrijednosti pa jednaki brojčani odnosi (omjeri)
znače i jednake odnose u mjerenoj pojavi (npr. mjerenje duljine, sile, vremena
potrebnog za izvođenje neke aktivnosti).
100.
ordinalna skala
(engl.
ordinal scale
) - pored toga što određuje pripadnost
pojedinih objekata nekoj klasi (nominalna skala), određuje i njihov redoslijed,
ali razlike između pojedinih klasa (vrijednosti) nisu jednake. Dakle, njome je
moguće utvrditi je li neki objekt bolji od drugoga, ali ne i koliko je bolji (npr.
redoslijed trkača na cilju neke utrke, školske ocjene itd).
101.
ortogonalna rotacija
(engl.
orthogonal rotation
) - transformacija inicijalnoga
koordinatnog sustava uz zadržavanje ortogonalnosti između faktora.
102.
osjetljivost
(engl.
sensitivity
) - predstavlja svojstvo mjernog instrumenta da
uspješno razlikuje ispitanike po predmetu mjerenja.
P
103.
paralelni testovi
(engl.
parallel tests
) - mjerni postupci koji u jednakom stupnju
izazivaju i mjere isti predmet mjerenja, a to znači da imaju jednake aritmetičke
sredine, standardne devijacije i interkorelacije (Guliksen, 1950, prema
Mejovšek, 2003).
104.
parametrijske metode
(engl.
parametrics methods
) - koriste se za obradu
normalno distribuiranih podataka, prikupljenih na kvantitativnim mjernim
ljestvicama, kod kojih je moguće utvrđivati statističke parametre (npr.
t
-test,
univarijatna analiza varijance, mutlivarijatna analiza varijance, regresijska
analiza itd.)
105.
parcijalna korelacija
(engl.
partial correlation
) - predstavlja stupanj
povezanosti između dvije varijable iz kojega je isključen utjecaj jedne ili više
ostalih varijabli.
)
r
)(1
r
(1
r
r
r
r
2
yz
2
xz
yz
xz
xy
xy/z
gdje je
r
yx/z
koeficijent parcijalne korelacije između varijabli
x
i
y
,
r
yx
koeficijent korelacije između varijabli
x
i
y
,
r
xz
koeficijent korelacije između
varijabli
x
i
z
,
r
yz
koeficijent korelacije između varijabli
y
i
z
.
Pojmovnik
348
106.
parcijalni koeficijent determinacije
(engl.
partial determination coefficient
) -
proporcija zajedničke varijance pojedine nezavisne i zavisne varijable.
107.
PB-kriterij
(engl.
PB-criterion
) kriterij za odabiri značajnog broja glavnih
komponenata. Prema PB-kriteriju značajnim komponentama smatraju se one
komponente kojih je suma svojstvenih vrijednosti
j
, poredanih po veličini,
manja od
smc
.
)
(
2
U
I
trag
smc
gdje
smc
(kvadrat multiple korelacije) predstavlja zajednički dio varijance
svake varijable s preostalima iz promatranog skupa,
I
matrica identiteta, a
U
2
matrica uniknih dijelova varijanci svake varijable koja se izračuna operacijom
1
1
diag
)
(
2
R
U
108.
podatak
(engl.
data
) - određena kvantitativna ili kvalitativna vrijednost kojom
je opisano određeno obilježje nekog objekta, stvari, osobe, pojave, procesa…,
odnosno, entiteta.
109.
pogreška tipa I ili
(engl.
type I error or
error
) - pogreška koju činimo kad
odbacimo nultu hipotezu, a ona je točna.
110.
pogreška tipa II ili
(engl.
type II error or
error
) - pogreška koju činimo
kad prihvatimo nultu hipotezu, a ona nije točna.
111.
Poissonova distribucija
(engl.
Poisson distribution
) - diskretna teoretska
distribucija koja aproksimira
binomnu distribuciju
za velike vrijednosti
n
(npr.
n>50
) i male vrijednosti
p
(npr.
p<0,05
), pa predstavlja njen ekstreman slučaj.
Naziva se i
distribucijom rijetkih događaja
. Ako se
= n
p
tretira kao
konstanta, jer
n
teži beskonačnom (
n
), a
p
nuli (
p
0
), onda je vjerojatnost
nekog događaja
x
jednaka
e
x
x
p
x
!
)
(
,
gdje je
p(x)
vjerojatnost događaja
x = 0,1,..,n, e
baza prirodnog logaritma (
e
=2,71828
),
=n
p
parametar
Poissonove distribucije
(
n -
ukupan broj opažanja,
entiteta, događaja, eksperimenata, a
p -
vjerojatnost povoljnog ishoda,
događaja).
0,00
0,10
0,20
0,30
0,40
0,50
0,60
0,70
0,80
0,90
1,00
0
1
2
3
4
5
6
7
8
9
10
x
p(x)
Poissonova distribucija za vrijednost parametra
=3.

Pojmovnik
350
123.
relativna frekvencija
(engl.
relative frequency
) - izračuna se kao omjer
frekvencije određene kategorije
f
g
i zbroja frekvencija svih kategorija
n
(ukupnog broja entiteta).
n
f
p
g
g
;
100
n
f
%
g
g
124.
rezidualne vrijednosti
(engl.
residual values
) - odstupanja izmjerenih
vrijednosti zavisne varijable
y
i
od prognoziranih vrijednosti
y
i
’
.
'
i
i
i
y
y
e
125.
rezidualna suma kvadrata
(engl.
residual sum of squares
) - suma kvadratnih
odstupanja izmjerenih vrijednosti zavisne varijable
y
i
od prognoziranih
vrijednosti
y
i
’
.
r
ss
=
n
i
i
y
y
1
2
)
'
(
S
126.
sampling distribucija
(engl.
sampling distribution
) - distribucija vjerojatnosti
prema kojoj varira neki statistički parametar (npr. aritmetička sredina, varijanca,
koeficijent korelacije...) izračunat iz velikog broja slučajnih uzoraka iste
veličine. Ako iz neke populacije entiteta odaberemo sve moguće uzorke iste
veličine te za svaki uzorak izračunamo parametar
’
, dobit ćemo neku
distribuciju po kojoj će parametri
’
varirati. S obzirom na to da su uzorci birani
slučajno, i vrijednosti parametra
’
slučajno će varirati, odnosno činit će
slučajnu varijablu koja će imati neku od teoretskih distribucija vjerojatnosti
(
Gaussova, t-distribucija, F-distribucija...
)
.
127.
scree test
(engl.
scree test
) - Cattellov način određivanja broja značajnih
komponenata. Subjektivnom procjenom odredi se točka poslije koje se
svojstvene vrijednosti smanjuju u skladu s blagim linearnim trendom pomoću
grafičkog prikaza svojstvenih vrijednosti korelacijske matrice (
scree plot
).
Scree plot – grafikon svojstvenih vrijednosti korelacijske matrice
128.
sistematske pogreške
(engl.
sistematic errors
) - pogreške mjerenja koje nastaju
utjecajem sistematskih faktora koji izazivaju stalni porast ili pad rezultata
(primjerice, učenje, umor, razvoj itd.).
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
4,50
4,20
2,97
1,25
0,25
0,15
0,11
0,08
0,04
0,02
1
2
3
4
5
6
7
8
9
Pojmovnik
351
129.
slučajni uzorak
(engl.
rendom sample
) - uzorak biran tako da svakom entitetu
populacije osiguramo jednaku vjerojatnost izbora.
130.
Spearman-Brownov koeficijent pouzdanosti
(engl.
Spearman-Brown’s
reliability coefficient
) - koeficijent pouzdanosti koji se izračunava u okviru
metode interne konzistencije pod klasičnim modelom mjerenja kad se
kondenzacija (procjena pravih rezultata) izvodi metodom jednostavne sumacije
(zbrojem ili aritmetičkom sredinom) standardiziranih rezultata ispitanika u
česticama.
R1
1
T
m
1
1
m
m
r
tt
gdje je
m
broj čestica,
R
matrica korelacija između čestica, a
1
sumacijski
vektor sa
m
jedinica.
131.
split-half metoda
(engl.
split-half method
) - metoda za utvrđivanje pouzdanosti
kod koje se kompozitni test dijeli na dva jednaka dijela, i to najčešće metodom
longitudinalnog rascjepa (sve neparne čestice čine prvi dio testa, a sve parne
drugi dio). Na taj se način test svodi na dvije čestice (
m=2
), pa se pouzdanost
izračunava Spearman-Brownovom formulom za dvije čestice
r
1
2r
r
tt
gdje je
r
korelacija između prvog i drugog dijela testa.
132.
standardna pogreška mjerenja
(engl.
standard error of measurement
) -
standardna devijacija pogrešaka mjerenja.
)
r
(1
σ
σ
tt
e
gdje je
standardna devijacija bruto rezultata, a
r
tt
koeficijent pouzdanosti.
133.
standardizirani regresijski koeficijent
(engl.
standardized regression
coefficient
) - predstavlja prosječnu veličinu promjene zavisne varijable izraženu
u dijelovima standardne devijacije za jedinični porast standardizirane vrijednosti
nezavisne varijable
z
j
,
uz uvjet da su vrijednosti preostalih nezavisnih varijabli
konstantne. Budući da su standardizirani regresijski koeficijenati izračunati na
standardiziranim varijablama, oni predstavljaju relativan doprinos svake
nezavisne varijable prognozi zavisne varijable pa se smatraju koeficijentima
utjecaja.
134.
standardna devijacija
(engl.
standard deviation
) - mjera disperzije ili
varijablinosti podataka koja se izračunava kao korijen iz varijance, odnosno,
korijen iz prosječnog kvadratnog odstupanja rezultata entiteta od aritmetičke
sredine
1
n
)
x
x
(
s
n
1
i
2
i
gdje je
i = 1,…,n,
a
n
broj entiteta uzorka.

Pojmovnik
353
T
141.
t-distribucija
(engl.
t-distribution
) - kontinuirana teoretska distribucija.
Slučajna varijabla
t
ima
Studentovu t-distribuciju
s parametrom
df
ako je
2
1
2
1
2
2
1
)
(
df
df
t
df
df
df
t
f
gdje je
df
broj stupnjeva slobode (
df=1,2…
),
gama funkcija,
=3.14459...
t-distribucija za df=5
142.
teoretske distribucije
(engl
. distribution functions
) - matematičke funkcije koje
omogućavaju utvrđivanje vjerojatnosti nekog slučajnog događaja u zadanim
uvjetima. Moguće je razlikovati diskretne (uniformna distribucija, binomna
distribucija, Poissonova distribucija) i kontinuirane (normalna distribucija, t-
distribucija, F-distribucija,
2
-distribucija) teoretske distribucije.
143.
totalni raspon
(engl.
range
) - najjednostavnija mjera varijabilnosti. Utvrđuje se
kao razlika između maksimalne (
x
max
) i minimalne (
x
min
) vrijednosti.
min
max
tot
x
x
R
144.
treći (gornji) kvartil
(engl.
upper quartiles
) - vrijednost koja uređeni niz
podataka dijeli na 3/4 članova s manjom ili jednakom vrijednosti, odnosno 1/4
članova s većom ili jednakom vrijednosti.
145.
t-test
(engl.
t-test
) - statistički postupak kojim se utvrđuje statistička značajnost
razlike aritmetičkih sredina dvaju uzoraka (
t-test za nezavisne uzorke
),
statistička značajnost razlike aritmetičkih sredina jednog uzorka mjerenog u
dvije vremenske točke (
t-test za zavisne uzorke
) te statistička značajnost razlike
aritmetičke sredine nekog uzorka u odnosu na neku unaprijed poznatu
aritmetičku sredinu.
0
,0
0
,1
0
,2
0
,3
0
,4
0
,5
-3
-2
-1
0
1
2
3
2,57
95 %
df=5
Pojmovnik
354
U
146.
uniformna distribucija
(engl.
uniform distribution
) - diskretna teoretska
distribucija Slučajna varijabla
x
ima uniformnu distribuciju ako je vjerojatnost
bilo koje njene vrijednosti (elementarnog događaja) u skupu od
n
elementarnih
događaja jednaka
n
1
)
x
(
p
,
gdje je
p(x)
vjerojatnost elementarnog događaja
x = 1,..,n
,
n
ukupan broj
vrijednosti koje može imati slučajna varijabla
x
.
Uniformna distribucija
147.
unikvitet
(engl.
uniquety
) - dio varijance manifestne varijable koji nije moguće
objasniti značajnim brojem glavnih komponenata.
148.
univarijatna analiza varijance
(engl
. analysis of variance,
ANOVA) - metoda
za utvrđivanje statističke značajnosti razlika između aritmetičkih sredina dviju
ili više grupa u određenoj varijabli.
149.
univarijatne metode
(engl.
univariate methods
) - statističke metode kojima se
analiziraju podaci jedne varijable (
t
-test, univarijatna analiza varijance...).
150.
uzorak entiteta
(engl.
sample of entities
) - podskup entiteta
izabran iz
populacije u skladu s nekim pravilom, a s ciljem da je što bolje reprezentira.
151.
uzorak varijabli
(engl.
sample of variables
) - podskup varijabli
izabran na
temelju neke teorije iz populacije varijabli.
152.
uzorkovanje
(engl.
sampling
) - postupak kojim se iz populacije bira uzorak
entiteta.
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
1
2
3
4
5
6
x
p(x)

356
O autoru
Dražan Dizdar
rođen je 27. 04. 1967. godine u
Drnišu, oženjen, otac troje djece, Hrvat,
državljanin Republike Hrvatske. Osnovnu školu
završio je u Oklaju, a srednju u Tehničkom
školskom centru u Zadru. Fakultet za fizičku
kulturu u Zagrebu upisao je 1989. godine, a
diplomirao 1994. godine radom:
Kompjutorski
program za definiranje kinezioloških operatora
za poboljšanje funkcionalnih sposobnosti i
redukciju potkožnog masnog tkiva
. Iste godine uposlen je na Fakultetu
za fizičku kulturu Sveučilišta u Zagrebu kao mlađi asistent na
predmetu Kvantitativne metode te je upisao poslijediplomski studij za
znanstveno usavršavanje u području kineziologije. Magistarski rad
pod naslovom:
Vrednovanje jednog metodološkog postupka za
prognoziranje rezultata u nekim sportovima
obranio je 1997. godine te
stekao zvanje asistenta na predmetu Kvantitativne metode. Godine
2002. obranio je doktorsku disertaciju pod naslovom:
Vrednovanje
skupa metoda za procjenu stvarne kvalitete košarkaša
na
Kineziološkom fakultetu u Zagrebu te stekao zvanje višeg asistenta na
predmetu Kvantitativne metode. Dana 2. 12. 2003. godine izabran je u
znanstveno-nastavno zvanje docenta, a 15.03.2007. godine u
znanstveno zvanje višeg znanstvenog suradnika za područje
društvenih znanosti – polje odgojnih znanosti, te 18. 05. 2007. godine
u zvanje izvarednog profesora za područje društvenih znanosti, polje
odgojnih znanosti, grana kineziologija, predmet Kvantitativne metode
na Kineziološkom fakultetu Sveučilišta u Zagrebu. Dana 10. 10.2011.
godine izabran je znanstveno zvanje znanstvenog savjetnika u
znanstvenom području društvenih znanosti - polje kineziologija.
Aktivno sudjeluje u realizaciji znanstvenih projekata (kao voditelj i
suradnik) financiranih od Ministarstvo znanosti i tehnologije
Republike Hrvatske, odnosno Ministarstvo znanosti, obrazovanja i
športa. Do sada je objavio 42 znanstvena i 5 stručnih radova. Autor je
1 sveučilišnog udžbenika te koautor 3 priručnika i 3 knjige. Radovi
pristupnika do sada su citirani 193 puta (H index = 7) prema
SCOPUS-u. Od 1994. aktivno sudjeluje u nastavi sveučilišnog studija
na Kineziološkom fakultetu u Zagrebu na predmetu Kvantitativne
metode, doktorskog studija na predmetima Metode analize podataka i
Kineziometrija te stručnog studija na predmetu Osnove statistike i
kineziometrije.