1
Nezavisni Univerzitet Banja Luka
STATISTIKA
Dr.sc.Branka Marković
2
1.UVOD
1.1.Pojam i zadaća statistike
Sam naziv potiče od novolatinskog
ratio status
i italijanskog ekvivalenta
ragione di stato
-
državni interes, te izvedenice
statista
-osoba vješta u vođenju državnih poslova.
Značenje pojma
statistika se mjenjalo sa vremenom.Danas se pod statistikom podrazumjeva:
1.Nauka o prikupljanju brojčanih podataka različite vrste , o njihovom uređenju, metodama
analize i tumačenju
2.Skup uređenih brojčanih podataka o različitim prirodnim i društvenim pojavama, koje
prikupljaju i objavljuju statističke , stručne ,naučno-istraživačke i druge ustanove.
Predmet statistike
sastoji se u donošenju odluka brojčane prirode o nepoznatim
karakteristikama skupa na osnovu rezultata izučavanja varijacija.Statistički podaci su
mnogobrojni.Pomoću statističkih metoda oni se redukuju sa ciljem da se isključe nevažne, a
izdvoje zančajne informacije o pojavi koju oni predstavljaju.Podaci su posmatrana
kvalitativna i kavntitativna obilježja objekata, osoba,pojava odnosno elemenata statističkog
skupa.
Obilježje
je svojstvo po kome se jedinice skupova razlikuju ili jedna drugoj liče.Ona se
pojavljuju u više oblika(modaliteta), pa se pojam obilježja izjednačuje s pojmom varijable.
Statistička analiza
, statističke informacije, analitičke metode i modeli osnova su svake
empirijske analize prirodnih i društvenih pojava.Metodama se procjenjuju nepoznati
parametri modela osnovnih skupova ili testiraju hipoteze o njima.Statističke metode služe u
postupcima predviđanja, kontroli proizvodnih procesa, poslovnom odlučivanju.Statistički
podaci dio su velikog skupa informacija kojima je izloženo moderno društvo.
Statistika kao naučnoanalitička metoda istraživanja pojava i procesa dijeli se na deskriptivnu i
inferencijalnu (analitičku, induktivnu, matematičku)statistiku.
Deskriptivna statistika
se bavi prikupljanjem podataka, njihovim grupiranjem, tabelarnim i
grafičkim prikazivanjem ,izračunavanjem različitih brojčanih pokazatelja koji izražavaju
karakteristike promatrane pojave. Svi se rezultati odnose samo na analiziani skup podataka .U
deskriptivnu statistiku ubrajaju se postupci analize nizova i specifičnih mjera npr.srednje
vrijednosti, mjere disperzije mjere asimetrije itd.

4
intervalu.Primjer:popis stanovništva tačno u ponoć 31.12.2012. godine i on se definiše u tačno
određenom trenu, dok se proizvodnja električne energije definiše u određenom razdoblju.
Statistički skup čiji elementi zadovoljavaju spomenute definicije je
homogen.
Samo takvi
skupovi mogu biti predmet statističke analize.
Statistički skup ćemo upoznati ako upoznamo njegove jedinice, a njih ćemo upoznati ukoliko
upoznamo njihova obilježja(svojstva).Pod statističkim obilježjem podrazumjevamo ona opšta
svojstva jedinica skupa po kojima se međusobno razlikujuSvaka jedinica ima više
obilježja.Primjer:jedinica „zaposlena osoba“ ima ova obilježja .pol;kvalifikaciju;dob;dužina
staža;mjesto i vrsta zaposlenja itd.
Često je nemoguće, vršiti statističku analizu na čitavom statističkom skupu. Zbog toga se vrlo
često iz čitavog statističkog skupa vrši izbor nekih elemenata skupa na kojima se sprovodi
dalja statistička analiza, koja rezultira određenim kvantitativnim zaključcima koji važe za
čitav statistički skup. Podskup statističkog skupa dobijen izborom nekih njegovih elemenata
zove se
uzorak.
Obim uzorka je uvijek manji od obima osnovnog skupa.
1.3.Vrste obilježja i njihova svojstva
Svojstvo po kome se jedinice skupa razlikuju ili sliče nazivaju se obilježje.U pravilu ona se
javljaju u dva ili više oblika(modaliteta).Svojstva elemenata statističkog skupa se
mjere.Mjerenjem se smatra pridruživanje brojeva ili oznaka jedinicama statističkog skupa
prema određenom pravilu.Pravila pridruživanja data su
mjernim skalama(nivo
mjerenja)
.Razlikuju se četiri vrste mjernih skala:
nominalna,ordinalna, intervalna i
numerička(racio).
Nominalna skala
je data u obliku nenumeričkog skupa tj. liste naziva(atributa, kategorija,
slovnih oznaka..).Našla je primjenu na podatke koji su razvrstani u različite kategorije u svrhu
identifikacije.Redosljed je utvrđen , najčešće abecednim redom Primjeri: imena, marke,
bračno stanje.Tim se kategorijama mogu pridružiti numeričke vrijednosti,ali nisu dopuštene
nikakve brojčane operacije.
Nominalna obilježja se dijele na:
atributivna i geografska
.Atributivno obilježje je svojstvo
jedinice statističkog skupa koje se izražava opisno tj. riječima.Primjer: pol, narodnost,
5
zanimanje , uzrok smrti itd.Geografsko(prostorno) obilježje označava mjesto s kojim je
jedinica u nekoj vezi.Primjer: mjesto rođenja; mjesto stalnog boravka;mjesto zaposlenja itd.
Ordinalna skala
pridružuje brojeve, slovne oznake ili simbole elementima skupa prema
stepenu intenziteta nekog svojstva.Ima primjenu na podatke koji se razvrstavaju u kategorije
koje se mogu rangirati, tj. poredati.Primjer: rangiranje izvrstan, zadovoljavajući, loš. Mogu im
se pridružiti brojčane vrijednosti koje ima smisla upoređivati, ali nisu dopuštene brojčane
operacije.Pošto se mogu podaci rangirati(poredati) prema stepanu svog intenziteta pri tome se
ordinalno obilježje zove još i obilježje ranga.
Intervalna skala
je skala kod koje se pridružuju brojevi mjernim svojstvima elemenata.Kod
njih znamo redosljed i razliku između brojeva na skali, jer je kod tih skala definisana razlika
jednaka na svakom dijelu skale.Primjer: temperaturna skala.Za intervalnu skalu je
karakteristično što je položaj nule i mjerne jedinice određene dogovorom.
Omjerna skala
se sastoji od brojeva za koje vrijedi da njihove jednake razlike predstavljaju
jednake razlike mjernog svojstva.Primjenjuje se na podatke koji se mogu rangirati, imaju sva
svojstva intervalnih skala i za koje imaju smisla sve osnovne aritmetičke operacije.Primjer:
dužina, težina, zapremina itd.
Vrijednosti koje su pridružene elementima pomoću omjerne skale nazivaju se
vrijednostima
numeričkog obilježja
Ako se numeričko obilježje može izraziti samo cijelim brojevima onda
se takvo obilježje naziva
diskretno ili diskontinuirano.
Primjer: broj zaposlenih u radnji.Ako se
numeričko obilježje može izraziti i cjelim i decimalnim brojem , kao primjer:težina, dužina ,
visina, tada se takvo numeričko obilježje naziva
kontinuirano
numeričko obilježje.
Statistička obilježja se mogu podjeliti na
kvalitativna i kvantitativna
statistička obilježja.
Kvalitativna (kategorijska) obilježja su ona obilježja koja ne mogu poprimati brojčane
vrijednosti,ali mogu biti razvrstana u dvije ili više nebrojčanih kategorija.U ovu grupu
obilježja ubrajamo statistička obilježja mjerena nominalnoj i ordinalnoj skali.
Kvantitativna obilježjaje obilježja koja imaju brojčanu (numeričku) vrijednost.Takve
karakteristike imaju obilježja mjerena intervalnom i omjernom skalom.
1.4. Izvori podataka
7
Za brojčano izražavanje odnosa između obilježja, do sada smo upotrebljavali postotke, u tu
svrhu primjenjuje se
relativna frekvencija,
a ona je odnos apsolutne frekvencije tog obilježja i
zbira svih apsolutnih frekvencija.Relativna frekvencija se označava sa
p
i
.
p
i
=
f
i
N
i=1,2.....k
Zbir frekvencija mora biti jednak 1.
U statističkoj analizi nominalnih nizova koriste se i relativne frekvencije.
Relativna frekvencija je relativni broj koji pokazuje udio grupe podataka u
ukupnom broju podataka
Nominalni nizovi
nastaje grupisanjem podataka prema modalitetima nominalnog
obilježja.Pošto se nominalna obilježja dijele na atributivna i geografska to se u nizovi dijele
na atributivne i geografske.Kod ovih nizova primjenjuju se apsolutne i relativne frekvencije.
Nominalni nizovi se prikazuju pomoću tabela i grafikona.Svaka statistička tabela nastaje od
horizontalnih i vertikalnih crta.U predkoloni se navodi naziv obilježja i njegovi modaliteti ,a u
zaglavlju je opis sadržaja kolone.Statističkom tabelom povećava se preglednost grupisanih
podataka.Nominalne nizove grafički
prikazujemo korištenjem površinskog
grafikona(stubčasti grafikon).Mogu biti uspravni ili položeni stubci.Stubci su jednakih baza ,
pa se poređenjem njihovih visina mogu vidjeti razlike frekvencija u odnosu na pojedine oblike
obilježja. U istu svrhu može se koristiti i kružni dijagram.
Kod stubčastog dijagramana horizontalnoj osi nanosi se vrijednost obilježja X.Kod grafikona
apsolutnih frekvencija na Y osi se nanose vrijednosti odgovarajućih frekvencija obilježja X, i
konstruišu se pravougaonici iznad vrijednosti na X osi sa visinama jednakim frekvencijama.
Geografski nizovi prikazuju se osim grafikonom i kartogramima, pri čemu se geografska
obilježja prikazuju geometrijskim likovima..Grafičko i statističko prikazivanje predstavlja
sredstvo deskriptivne statistike.
Redosljedni(ordinalni) niz
nastaje grupisanjem elemenata osnovnog skupa prema stepenu
intenziteta svojstav.I u ovom kao i u prethodnom nizu skup od N podataka dijeli se na k
podskupova, koji se međusobno ne poklapaju.Apsolutna frekvencija f
r
i
predstavlja broj
elemenata osnovnog skupa s oblicima ranga
r
i
.
R
elativna frekvencija p(
r
i
) je odnos apsolutne frekvencije i zbira apsolutnih frekvencija.
8
Prikazivanje redosljednog niza se vrši tabelarno i grafički.Za tebelarno prikazivanje služi
kombinovana tabela, čiji sadržaj zavisi od oblika dviju ili više obilježja.Za grafičko
prikazivanje koristi se površinski grafikon jednostavnih stubaca i kružni dijagram.
Numerički nizovi
nastaju uređenjem vrijednosti kvantitativnog obilježja.Najjednostavniji
način uređivanja vrijednosti tog obilježja sastoji se u nizanju po veličini.Ako su pojedinačne
vrijednosti obilježja x:
x
1
;
;
x
2
;......
x
N ,
pri čemu vrijedi
x
i
≤ x
i
+
1
, i=1,2,...,N-1
Kada je N veliki broj, uređivanje pojedinačnih vrijednosti je otežano,zbog toga se mora
izvršiti grupisanje podataka.
Grupisanjem podataka nastaje distribucija frekvencija.Funkciju
koja svakom obilježju xi pridružuje odgovarajuću frekvenciju fi ; i = 1......; k, nazivamo
funkcijom distribucije frekvencije.(
x
i
,
f
i
).
Relativna frekvencija p(
x
i
) dobije se dijeljenjem i-te
apsolutne frekvencije zbirom apsolutnih frekvencija :
p
i
=
f
i
N
;
i=
1,2,3...k
Relativna frekvencija numeričkog niza je broj koji se nalazi između nule i jedan, a zbir im je
uvijek jedan.
Oblici u kojima se pojavljuje numeričko obilježje razlikuju se međusobno prema načinu na
koji se ono može mjeriti , jer se numeričko obilježje izražava brojem.Vrijednosti
kontinuiranog obilježja
se grupišu na osnovu razreda.Te se grupe nazivaju
razredi ili
klase
.Apsolutna frekvencija razreda je broj podataka razvrstan u dati razred.
Svaki razred ima donju i gornju granicu.Donja granica
i
-tog razreda označava se sa
L
1
i
a
gornje sa
L
2
i
pa je
i
–ti razred dat izrazom:
L
1
i
≤ x
i
<
L
2
i
i=
1,2....,k
Distribucija frekvencija kontinuiranog numeričkog obilježja je skup parova razreda i
pridruženih frekvencija.

10
Šema br.4: Prikaz numeričkog obilježja
Ako su date pojedinačne vrijednosti numeričkog obilježja x, i ako ih je mali broj, prikladan je
grafički prikaz pomoću tačaka.
_
.
___
.._
___________________
....
_________
.._
___________________
10 15 60 80 Plata(u hiljadama din.)
Šema br. 5:Prikaz numeričkog niza pomoću tačaka
Osim dijagramima s tačkama pojedinačni podaci o vrijednostima numeričkog obilježja
prikazuju se S_L dijagramom, on je specifična vrsta histograma.
Distribucija frekvencija grafički se prikazuje
linijskim i površinskim grafikonom
, odnosno
histogramom.Linijski grafikon konstruiše se u pravougaonom koordinatnom sistemu.Na osi
apscise nalazi se aritmetičko mjerilo za obilježje X, a na osi ordinata mjerilo
frekvencije.Ukoliko izvršimo spajanje tačaka , koordinate kojih su vrijednosti x i pripadajućih
frekvencija tada ćemo dobiti
poligon frekvencija.Histogram j
e površinski grafikon koji se
konstruiše u pravougaonom sistemu s artimetičkim mjerilima na osi.Umjesto crta
upotrebljavaju se pravougaonici.Pravougaonici se oslanjaju na os apscise, na kojoj se nalazi
aritmetičko mjerilo za vrijednosti X, a visina pravougaonika određena je frekvencijom.
Numerička obilježja
grupisani podaci
distribucija
frekvencija
kumulativni niz
Negrupisani podaci
S-L dijagram
dijagram tačaka
11
broj garnitura 5
0
1
2
3
4
5
6
7
8
9
10
Šema br 6: histogram frekvencija
broj garnitura
Category 2
Category 3
Category 4
0
2
4
6
8
10
broj dana
Šema br.7: poligon frekvencija
Kumulativni niz
distribucije frekvencija „manje od“ ili empirijska funkcija distribucije nastaje
postepenim sabiranjem frekvencija.Sabirati se mogu apsolutne i relativne frekvencije.
Kumulativni niz „manji od“ prikazuje se za diskontinuirano obilježje stepenastim grafikonom,
a za kontinuirano linijskim grafikonom.
Primjer 1.
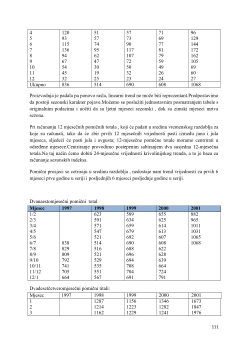
Anketirana je populacija od 50 studenata o broju položenih ispita
i tjelesnoj težini. Dobijeni su sledeći rezultati:
a) broj položenih ispita:
7 4 12 3 7 8 6 5 9 9 10

13
Interval
težine(kg)
Apsolutna
frekvencija
f
i
Relativna
frekvencija
p
i
Kumulativna
frekvencija
≤
50-60
2
2/50
2
60-70
14
14/50
16
70-80
13
13/50
29
80-90
9
9/50
38
90-100
6
6/50
44
100-110
4
4/50
48
110-120
2
2/50
50
∑
50
1
Numeričkim metodama deskriptivne statistike dolazi se do određenih pokazatelja i
dalje redukcije informacija.Pokazatelji kojima se opisuje gomilanje podataka oko neke
vrijednosti nazivaju se
srednjim vrijednostima ili mjerama centralne tendencije.
Stepen
varijabilnosti podataka mjeri se
mjerama disperzije(raspršenosti)
.Način
raspoređivanja u odnosu na neku vrijednost
mjerama asimetrije
.Oblik rasporeda
podataka mjeri se
mjerama zaobljenosti
.Gomilanje podataka , njihova raspršenost,
način i oblik raspoređivanja karakteritike su pojava što ih podaci
predstavljaju.Brojčane vrijednosti pokazatelja tih karakteristika izračunate za
populaciju nazivaju se
parametrima.
1.2.SREDNJE VRIJEDNOSTI NUMERIČKOG NIZA
U praksi se vrlo često javlja problem kvalitetnoga prezentovanja velikih nizova podataka
kvalitativnih ili kvantitativnih obilježja vezanih za relativno velike statističke skupove
(npr.cjelokupno stanovništvo nekoga grada/
države
). I dok je u slučaju kvalitativnih obilježja
najbolji mogući rezultat tablični ili grafički prikaz podataka, za kvantitativna se obilježja
uvode posebni numerički pokazatelji, i to su tzv.
srednje vrijednosti
.
Srednja vrijednost
je konstanta čiji je cilj na što reprezentativniji način predstavi niz
varijabilnih podataka numeričkog niza. U pravilu je riječ o vrijednosti oko koje se ''gomila''
većina podataka numeričkog niza, pa se zato naziva i
mjera središnje
(
centralne
)
tendencije
.
Što je više podataka ''nagomilano'' oko pojedine srednje vrijednosti, njezina će
reprezentativnost biti bolja.Postoji više vrsta srednjih vrijednosti a dijele se na
potpune i
14
položajne
.Podjela je izvršena s obzirom da li se pri računanju pojedinih srednjih vrijednosti
pojavljuju svi članovi numeričkog niza ili samo dio tih članova.
U
potpune srednje vrijednosti
ubrajamo aritmetičku sredinu, geometrijsku sredinu i
harmonijsku sredinu. U računanju tih vrijednosti koriste se
svi
elementi numeričkoga niza. U
položajne srednje vrijednosti
ubrajamo medijan i mod. Njihova je vrijednost određena
položajem
unutar numeričkog niza, pa u njihovu računanju ne učestvuju svi elementi
numeričkoga niza.
Osnovne vrste srednjih vrijednosti su
aritmeti
c
ka sredina
,
geometrijska sredina
,
harmonijska
sredina
,
medijan
i
mod
. Vrlo je važno istaknuti da je primjena svake pojedine vrste srednje
vrijednosti odredena
karakterom
(
svojstvima
) promatranog kvantitativnoga obilježja, pa ne
postoji ''univerzalna'' srednja vrijednost koja će dovoljno reprezentativno opisati
bilo koji
numerički niz podataka. U praksi se ovo pravilo često vrlo neopravdano zanemaruje, pa se za
spomenutu ''univerzalnu'' srednju vrijednost, zbog relativno jednostavnoga načina
računanja,uzima aritmetička sredina.
Istaknimo da svaku od navedenih srednjih vrijednosti možemo računati iz negrupiranih
(''sirovih'') i grupiranih podataka. Zajednička karakteristika svih takvih računa je da su
vrijednosti dobivene obračunom iz grupiranih podataka nepreciznije od vrijednosti dobivenih
obračunom iz negrupiranih podataka, naročito ako su podaci grupirani u razrede relativno
velikih širina.
1.2.1.Aritmetička sredina
Aritmeti
č
ka sredina
(oznake:
X
)
je najraširenija i najčešće korištena srednja
vrijednost.Aritmetička sredina dobije se tako da se suma podijeli s ukupnim
brojem
elemenata
numeričkoga niza.Postoji nekoliko različitih vrsta aritmetičkih sredina. Najpoznatija i
najraširenija je
jednostavna aritmetička sredina
. Za njezino je izračunavanje potrebno zadati
konačan
niz
negrupiranih
numeričkih podataka
x
1
; x
2
....
x
i
Tada se jednostavna aritmetička
sredina računa pomoću formule:
X
=
x
1
+
x
2
+
x
3
…. x
N
N
Ili kraće
X
=
∑
I
=
1
N
x
i
N

16
X
=
7
x
0
+
12
x
1
+
17
x
2
+
25
x
3
+
21
x
4
+
18
x
5
100
=3,61
Dobiveni rezultat obično interpretiramo ovako:
Prosje
č
an broj položenih jednosemestralnih
ispita po jednom studentu približno iznosi
3.61 Ovdje treba pripaziti i na red riječi u rečenici:
prilog
prosječno
uvijek dolazi neposredno ispred velicine na koju se odnosi.
Primjer 4
.Visina igrača jednog košarkaškog tima iznosi u centrimetrima 195, 180, 190, 202,
205, 201, 198, 199, 200, 204. Naći prosečnu visinu igrača.
Rešenje:
Aritmetička sredina može se računati i ukoliko su, umjesto, apsolutnih zadane odgovarajuće
relativne frekvencije. Radi jednostavnosti, pretpostavimo da su relativne frekvencije iskazane
u postotcima. Formalno, ako su
x
1
; x
2
....
x
i
vrijednosti
kvantitativnoga obilježja, a
p
1
;
p
2
..
p
k
njima odgovarajuće
relativne
frekvencije
iskazane u postotcima
, onda se vagana aritmetička
sredina računa pomoću izraza:
X
=
∑
i
=
1
k
p
i x
i
Raširenost primjene aritmeričke sredine je karakteristika njenih svojstava. Osnovna svojstva
aritmetičke sredine koja se mogu koristiti pri gruboj procjeni je li izračunata aritmetička
sredina dobar reprezentant numeričkog niza.
Svojstvo 1.
Svaka
podjela u kojoj su vrijednosti obilježja pridružene elementima skupa
natemelju
intervalne
ili
omjerne
skale ima aritmeticku sredinu.
Svojstvo 2.
Pri izracunu aritmetičke sredine niza numeričkih podataka obuhvaćene su sve
vrijednosti numeričkoga niza.
Svojstvo 3.
Svaki numerički niz ima
tačno jednu
aritmeticku sredinu.
Svojstvo 4.
Aritmeticka sredina se uvijek nalazi između najmanje (
xmin
) i najveće
(
xmax
)vrijednosti numeričkoga niza, tj. vrijede nejednakosti:
x
min
≤ x ≤ x
max
Svojstvo 5.
Aritmetička je sredina
jedina
srednja vrijednost takva da je
zbir odstupanja svih
elemenata numeri
č
koga niza
od nje
uvijek jednak nuli
.
17
∑
i
=
1
N
(
x
i
−
X
) = 0
Svojstvo 6.
(
svojstvo minimuma zbira kvadrata
) Neka je
x
1
; x
2
....
x
i
zadani numerički niz
podataka. Tada realna funkcija poprima minimalnu vrijednost za
x
=
X
,tj. navedeni zbir
kvadrata poprima minimalnu vrijednost kad je vrijednost varijable
x
jednaka aritmetičkoj
sredini elemenata zadanog niza.
∑
i
=
1
k
(
x
i
-
x
)²
¿
∑
i
=
1
k
(
x
i
-a)² ; a
≠ x
Svojstvo 7.
Aritmetička sredina
nije dobar reprezentant numeri
c
koga niza
ukoliko u
numerickom nizu
postoje ekstremno male ili velike vrijednosti
promatranog kvantitativnog
obilježja.
Svojstvo 8.
Ako su vrijednosti numeričkog obilježja jednake konstanti c, aritmetička sredina
tog obilježja jednaka je toj konstanti:
x
=c ;
x
1
=
x
2
=......
x
N
=c
Ako imamo skup od
N
elemenata a svi elementi su raspoređeni u
k
podskupova ,zajednička
sredina za skup tj.
aritmetička sredina aritmetičkih sredina
se izračunava:
x
=
∑
i
=
1
k
N
i
x
i
N
N=
∑
i
=
1
k
N
i
Aritmetička sredina skupa je ponderisana aritmetička sredina podskupova , pri čemu su
ponderi veličine podskupova.Članovi zbira u brojniku su podtotali.
Na isti način se računa i
aritmetička sredina relativnih brojeva
koordinacije i artimetičke
sredine prosjeka.
Relativni brojevi koordinacije ili odnosa su veličine koje se dobiju kada se frekvencije jednog
statističkog niza upoređuju sa frekvencijama drugog statističkog niza.Obe serije su samostalne
, a nalaze se u nekom odnosu.Računa se po formuli
Relativni broj koordinacije (R)=
veličina koju upoređujemo
veličina s kojom upoređujemo
Primjer relativnog broja koordinacije: gustoća stanovništva; dohodak po stanovniku.
Pojava koja se upoređuje dobit će se pomoću formule:
D
i
=
P
i
C
i
Prosjek relativnih brojeva koordinacije
dobit ćemo računanjem aritmetičke sredine
artimetičkih sredina:

19
Pretpostavimo sada da su podaci grupisani, tj. da imamo ukupno
n
različitih oblika
x
1
; x
2
....
x
i
Za svaki
i
= 1, 2, …,
n
označimo s
fi
apsolutnu frekvenciju oblika
xi
. Tada je
vagana
(
ponderirana
)
geometrijska sredina
izračunata iz grupiranih podataka dana izrazom:
G=
N
√
x
1
f
1
… . x
k
f
k
N=
∑
i
=
1
k
f
i
log G =
1
N
∑
i
=
1
k
f
i
log
x
i
N=
∑
I
=
1
k
f
i
Primjer 1.
Proizvodnja jednog artikla po mjesecima bila je 8, 12, 16, 19, 21 i 23. Izračunati
prosječnu mjesečnu proizvodnju datog artikla
.
Primjer 2.
Raspored radnika prema random stažu u jednoj fabrici bila je:
Godine
staža
5-10
10-15
15-20
20-25
25-30
30-35
Broj
zaposlenih
28
21
38
24
15
8
Izračunati prosečan radni staž zaposlenih
Godine staža
(x
i
)
Broj zaposlenih
(fi)
Razredna
sredina
Logx
i
filogx
i
5-10
28
7,5
0.87506
24,50168
10-15
21
12,5
1,09691
23,03511
15-20
38
17,5
1,24303
47,23514
20-25
24
22,5
1.35218
32,45232
25-30
15
27,5
1,43933
21,58995
30-35
8
32,5
1,51188
12,09504
160,90924
G=15,87
Prosečni radni stažu fabrici bio je 15,87 godina.
Geometrijska sredina primjenjuje se u analizi vremenskih nizova.Nalazi se između najmanje i
najveće vrijednosti niza.brojčano je manja od aritmetičke sredine.
20
1.2.3.Harmonijska sredina
Neka je
x
1
; x
2
....
x
i
konačan numerički niz podataka takav da za svaki
i
= 1, 2, …,
n
vrijedinejednakost
xi
> 0.
Harmonijska sredina
(oznaka:
H
) navedenog numeričkoga niza
definiše se kao
recipro
č
na vrijednost aritmetičke sredine recipro
č
nih vrijednosti svih
elemenata niza
.. Za numeričke nizove kojima je barem jedan član najviše jednak nuli
harmonijska sredina se
ne definiše
.Prema navedenoj definiciji, harmonijska sredina
negrupiranih numeri
č
kih podataka
računase iz izraza:
H=
N
∑
i
=
1
N
1
x
i
, x
i ≠
0
Izraz predstavlja jednostavnu harmobijsku sredinu.
Pretpostavimo sada da su podaci grupirani, tj. da imamo ukupno
n
različitih oblika
x
1
; x
2
....
x
i
.
Za svaki
i
= 1, 2, …,
n
označimo s
fi
apsolutnu frekvenciju oblika
xi
. Tada je
vagana
(
ponderirana
)
harmonijska sredina
izračunata iz grupiranih podataka data izrazom:
H=
∑
i
=
1
k
f
i
∑
i
=
1
k
f
i
x
i
Primjer1.
Prosjeĉna prodajna cijena proizvoda 2002.godine, te struktura vrijednosti prodaje
prema prodajnim područjima:
Područje
Prosječna prodajna cijena
u EUR
Struktura vrijednosti
prodaje (%)
Sjever
490
35,0
Središnja regija
500
40,0
Jug
494
25,0
Odredite kolika je prosječna prodajna cijena za sva tri područja zajedno.
H=
∑
i
=
1
k
f
i
∑
i
=
1
k
f
i
x
i
=
35
+
40
+
35
35
490
+
40
500
+
25
494
=
100
0,2020359
=494,96
Prosjeĉna prodajna cijena za sva tri područja zajedno je (zaokruţeno) 495EUR

22
Primjer 2.Izračunavamje moda distribucije frekvencija sa razredima.
Broj saobraćajnih nezgoda prema godinama starosti.
God starosti
Broj učesn.
U saob.nezg.
Precizne
granice raz.
Razredna
sredina
Veličina
razreda
f
i
x
si
i
0-4
12
0-5
2,5
5
5-9
20 (a)
5-10
7,5
5
10-14
28 (b)
10-15
12,5
5
15-19
19(c)
15-20
17,5
5
20-24
11
20-25
22,5
5
x
si
=
l
1
+
l
2
2
Precizne granice razreda (kolona 3) određujemo tako da donja granica razreda kojeg
promatramo mora biti jednaka gornjoj granici prethodnog razreda.
M
o
=
10
+
(
28
−
20
)
(
28
−
20
)+(
28
−
19
)
5
=
12,35
Dobna grupa koja najčešće stradava u saobraćajnim nezgodama je stara
12, 35 godina.
Mod, kao mjera centralne tendencije , određen je položajem u nizu.Na njega ne djeluju izraziti
male ili velike vrijednosti numeričkog niza.Prednost je što se može utvrditi i kod kvalitativnih
i kvantitativnih obilježja.Ne može se odrediti ako nema bar dva podatka sa istim
obilježjem.Određivanje moda je nepouzdano kod izrazito asimetrične distribucije u kojima je
otvoren modalni razred.
1.2.5. Medijana
Medijan-Medijana (oznaka
M
e
) je vrijednost numeričkog obilježja X, koja niz
uređen po
veličini
dijeli na dva jednaka dijela.Prva polovina članova niza ima vrijednost obilježja
jednaku medijani ili manju od nje, a preostalih 50% članova nizaima vrijednost obilježja veću
od medijane..Medijana je određena položajem u nizu i zbog toga se ubraja u grupu položajnih
srednjih vrijednosti
Medijana, kod negrupisanih vrijednosti obilježja, određuje se tako da se one najprije urede po
veličini, od najmanje prema najvećoj.
23
Ukoliko je broj članova uređenog statističkog niza neparan, N = 2 k +1, tada jemedijana
jednaka vrednosti {
N
+
1
2
} -og člana niza, a ukoliko je broj članova uređene statističkog niza
paran, N = 2 k , tada je medijana jednaka
aritmetičkoj sredini {
N
2
}-og i {
N
2
+1}-og člana tog niza.
Za negrupisane vrijednosti medijana je:
N=2k+1
M
e
=
x
N
+
1
2
N=2k
M
e
=
x
N
2
+
X
{
N
2
+
1
}
2
Primjer 1.
Odrediti medijanu za sljedeći niz podataka:
18, 25, 19, 22, 26, 28, 30, 16, 36
Prvo se niz podataka uredi po veličini:
16, 18, 19, 22, 25, 26, 28, 30, 36.
Pozicija medijane je
, što znači da je medijana vrijednost petog člana niza:
M
e
=25
Kod grupisanih obilježja(distribucija frekvencija) polazi se od predpostavne da su članovi
niza u medijalnom razredu međusobno jednako udaljeni.Da bismo odredili Me za grupisane
podatke neprekidnog tipa, potrebno je prvo da pronađemo medijalnu razreda Me.pronalaženje
vrijednosti obilježja srednjeg člana niza, pojednostavljuje se upotrebom empirijske funkcije
distribucije tj. kumulativnog niza „manje od“.
Za izračunavanje medijane distribucije frekvencija s razredima može se primjeniti sljedeći
izraz:
M
e
=
L
1
+
N
2
−
∑
f
i
f
med
pri čemu je u navedenom izrazu:
L
1
−
¿¿
donja prava ili precizna granica medijalnog razreda,to je razred s najmanjom vrijednosti
empirijske funkcije distribucije(kumulativnog niza „manje od“)koja uključuje veličinu N/2.
N- je zbir apsolutnih ili relativnih frekvencija
∑
f
i
–zbir frekvencija do medijalnog razreda
i
-veličina medijalnog razreda
f
med
−
¿¿
frekvencija medijalnog razreda

25
Kvantili(
oznaka p) su vrijednosti numeričkog obilježja koji niz uređen po veličini dijeli na q
jednakih dijelova.Broj kvantila pje za jedan manji od njegova reda q.Pa iz ovog možemo
zaključiti da je medijana kvantil q=2, pa je p=1, jer je dovoljna jedna vrijednost da se niz
podjeli na dva dijela.Kvantili koji niz dijele na deset jednakih dijelova nazivaju se
decili.
Ukupni broj decila je devet.Percentili dijele niz na sto jednakih dijelova i njih je ukupno
devedeset devet.kvantile su značajne deskriptivno statističke veličine.
Kvartili
su
položajne
vrijednosti koje uređeni numerički niz dijele na ukupno 4 jednaka dijela.
Ima ih ukupno4 – 1 = 3,p=3 a imaju svoja posebna imena i oznake:
–
prvi
ili
donji kvartil
(oznaka:
Q
1);
–
drugi kvartil
ili
medijan
(oznake:
Q
2,
Me
);
–
tre
ć
i
ili
gornji kvartil
(oznaka:
Q
3)
Prvi ili donji kvartil
je vrijednost obilježja koja članove niza dijeli u dvije grupe.U prvoj se
grupi nalazi ¼ elemenata s vrijednostima obilježja koja je jednaka ili manja od kvartila a u
drugoj su grupi ¾ članova s većim vrijednostima od kvartila.
Treći kvartil
je vrijednost obilježja, koja dijeli niz na dva dijela.U prvoj su grupi članovi, nih
¾, s vrijednostima obilježja koja je jednaka ili manja od gornjeg kvartila.Posljednja četvrtina
ima vrijednost obilježja veću od trećeg kvartila.
Tumačenje drugog kvartila, već je dato, jer je drugi kvartil jednak medijani.
Sve ovo prethodno što je napisano odnosi se na negrupisane numeričke ili
redosljedne(ordinalne) podatke
Primjer 1.
Negrupirani numerički podaci Mjesečna proizvodnja istovrsnog proizvoda na 10
dislociranih proizvodnih mjesta (u tonama):
72 81 74 85 88 74 86 94 79 90
Niz uređen po veličini:
72
74
74 79 81
M
e
85 86
88
90 94
Q
1
Q
2
Q
3
26
Kod grupisanih numeričkih obilježja(distribucije frekvencija) podaci su već uređene po
veličini, pa se postupak određivanja kvantila svodi na utvrđivanje rednih brojeva
podataka.postupak se ubrzava upotrebom kumulativne frekvencije.
Izraz za izračunavanje
donjeg kvartila
kod grupisanih podataka je :
Q
1
=
L
1
+
N
4
−
∑
f
i
f
kvar
i
A za gornji kvartil
:
Q
3
=
L
1
+
3
N
4
−
∑
f
i
f
kvar
i
L
1
-
donja granica kvartilnog razreda
N-ukupan zbir članova niza
∑
f
i
-zbir frekvencija do kvartilnog razreda
∑
f
kvar
-frekvencija kvartilnog razreda
i
-veličina kvartilnog razreda

28
1.3. MJERE DISPERZIJE
Srednjim vrijednostima se opisuje gomilanje podataka oko nekog oblika obilježja.srednja je
vrijednost konstanta, kojom se niz varijabilnih podataka opisuje jednim brojem .za
upoznavanje karakteristika podataka važna je značajna i informacija o stepenu njihove
varijabilnosti.Moguće je da različiti skupovi imaju jednake srednje vrijednosti, ali se razlikuju
po stepenu varijabilnosti(raspršenosti) obilježja.
Izračun neke od potpunih ili položajnih srednjih vrijednosti predstavlja tek jedan korak
ustatističkoj analizi nekoga obilježja. Sljedeći je korak analiza
reprezentativnosti
izračunatesrednje vrijednosti, odnosno, pojednostavljeno rečeno, određivanje
pokazatelja
kolikoizračunata srednja vrijednost dobro opisuje elemente osnovnoga skupa. Ti pokazatelji
gotovosu jednako važni kao i izračunate srednje vrijednosti.
Kako bi se moglo što bolje opisati
stepen varijabilnosti
statističkih podataka, definišu
seodgovarajući statistički pokazatelji pod zajednickim imenom
mjere
raspršenosti
(stepenvarijabilnosti; disperzije). Mjere disperzije mogu biti
apsolutne
i
relativne
.
Apsolutne
mjere disperzije su:
raspon varijacije, interkvartil
,varijansa i standardna devijacija.
Zajedničko obilježje svih navedenih mjera jest iskazivanje u jedinicama mjere
obilježjastatistickog skupa (KM, €, kg, cm itd.)
MJERE
DISPERZIJE
APSOLUTNE
MJERE
DISPERZIJE
1. Raspon
varijacije (R)
2.Interkvartil (I
Q)
3.Varijansa(δ2)
4.Standardna
devijacija (δ)
RELATIVNE
MJERE
DISPERZIJE
1.Koeficijent
varijacije(V)
2.Koeficijent
kvartalne
devijacije (I Q)
29
Relativne
mjere raspršenja obično se izražavaju u postocima, a dvije najčešće su
koeficijentkvartilne devijacije i koeficijent varijacije
.
Ukoliko je posmatrano obilježje
kvantitativno
, potrebno je izračunati sve navedene mjere.
Ukoliko je posmatrano obilježje
kvalitativno redosljedno
, zaanalizu disperzije mogu se
koristiti raspon varijacije, interkvartil i koeficijent kvartilnedevijacije. Grubu sliku (''prvi
utisak'') o raspršenosti podataka u osnovnom skupu možepredstavljati i odgovarajući
grafikon, a riječje o
dijagramu rasipanja
ili
dijagramu raspršenja.
Navedene mjere disperzije su svojevrsne mjere reprezentativnosti srednjihvrijednosti. Manja
mjera disperzije znači bolju reprezentativnost srednje vrijednosti iobrnuto.
1.3.1. Raspon varijacije
Raspon varijacije
(oznaka:
R
) je najjednostavnija mjera disperzije, definiše kao razlikaizmedu
najveće (
X
max
) i najmanje (
X
min
) vrijednosti
kvantitativnog
(ili, eventualno,
kvalitativnogredosljednog) obilježja. Dakle,
R
=
X
max
-
X
min
Najmanja moguca vrijednost raspona varijacije jednaka je nuli i nastupa u slučajevima kad
jeniz vrijednosti kvantitativnoga obilježja
konstantan
. Najveca vrijednost rasponavarijacije ne
može se odrediti.
Primjer 1.
Navršene godine radnoga staža svih 10 zaposlenika firme čine niz: 20, 12, 7, 29,
32, 10, 18, 16, 8, 17. Najveća vrijednost u tom nizu je
X
max
= 32, anajmanja
X
min
= 7. Pa je
raspon varijacije vrijednosti posmatranog obilježja
R
= 32 – 7 = 25 (godina).
Raspon varijacije distribucije frekvencija s razredima može se odrediti ako je poznata najveća
i najmanja vrijednost promjenljive.raspon je razlika gornje granice posljednjeg i donje granice
prvog razreda.
Nedostatak raspona varijacije je u tome što uzima samo dvije vrijednosti niza, i to najmanju i
najveću, a ne uzima u obzir raspoređivanje ostalih podataka.Primjenjuje se za mjerenje
varijacija npr. cijena, izmjene kursa dionica na berzi.

31
Raspon varijacije i interkvartil su nepotpune mjere disperzije.primjenjuju se za mjerenje
disperzije numeričkih i redosljednih nizova.
1.3.3.Varijansa i standardna devijacija
Varijansa i iz nje izvedena standardna devijacija obično se svrstava u red
najvažnijihpokazatelja varijabiliteta ili raspršenosti kvantitativnih obilježja. Osnovni razlog
je, da je zbir odstupanja svih vrijednosti kvantitativnog obilježja od njihovearitmetičke
sredine
uvijek
jednak nuli, pa taj pokazatelj ne možemo koristiti za opisvarijabiliteta
statističkoga niza. Drugi je razlog tome što u računanju varijanse, a samim tim i standardne
devijacije, koristimo sve elemente statističkog niza, pa je možemo svrstatikao
potpunu
mjerom disperzije.Varijansa i standardna devijacija mogu seračunati i iz ''sirovih''
(negrupiranih ili neuređenih) i iz grupiranih podataka
.
Varijansa
(oznaka: σ
2
grčko slovo
sigma
) se definiše kao
aritmetička sredinakvadrata
odstupanja vrijednosti kvantitativnoga obilježja od aritmeti
c
ke sredine svihvrijednosti
.
Varijansa se definiše kao
prosječno kvadratno odstupanje
vrijednosti kvantitativnoga
obilježja odaritmetičke sredine tih vrijednosti.Formula za izračunavanje varijanse je:
σ
²
=
∑
i
=
1
N
(
X
i
−
X
)
2
N
;
Kako je varijansa mjera data u drugom stepenu, što otežava njeno tumačenje.Radi lakšeg
objašnjavanja stepena varijabilnosti obilježja , kao mjera disperzije, uzima se standardna
devijacija.
Pošto je varijansa ''kvadratna'' mjera disperzije, relativno teško je tumačiti. Pomoćudrugoga
korijena iz varijanse dolazimo do najprimjenjenije potpune mjeredisperzije:
standardne
devijacije
.
Standardna devijacija
je po definiciji,
drugikorijen iz varijanse
. Takva formalna
definicija obično se zamjenjuje matematički netačnom,ali prihvatljivijom definicijom prema
kojoj je standardna devijacija
prosječnoodstupanje vrijednosti kvantitativnoga obilježja od
aritmeti
č
ke sredine tih vrijednosti
ili, joškraće i još nepreciznije,
prosje
č
no odstupanje od
prosjeka
. Istaknimo da je ''mjerna jedinica''za standardnu devijaciju jednaka ''mjernoj jedinici''
odgovarajućeg kvantitativnog obilježja(KM, €, kg, cm itd.).
32
σ=
√
∑
i
=
¿¿
N
(
X
i
−
X
)
²
N
Primjer 1
.Visina petoro slučajno odabranih studenata EF-a
Visina u cm
|
X
i
−
X
)
|
(
X
i
−
X
)
2
178
168
176
172
202
1.2
11.2
3.2
7.2
22.8
1.44
125.44
10.24
51.84
519.84
896
45.6
708.80
X
=
896
5
=179,2
σ
²
=
∑
i
=
1
N
(
X
i
−
X
)
2
N
=
708,80
5
=141,76 cm
σ=
√
∑
i
=
¿¿
N
(
X
i
−
X
)
²
N
=
√
σ
²
=11,90cm
Varijansa distribucije frekvencija numeričkih obilježja je
vagani prosjek kvadrata odstupanja
vrijednosti te promjenljive od njenog prosjeka.
Ponderi predstavljaju apsolutne frekvencije.
Uzraz varijanse distribucije frekvencija je:
σ
²
=
∑
i
=
1
N
f
i
(
X
i
−
X
)
2
N
N=
∑
i
=
1
k
f
i
Primjer 2
Posmatramo statistički skup svih stanova u onim stambenim zgradama(novogradnja
i dogradnja) koje su 2006. godine dobile građevinsku dozvolu u Srbiji. Posmatrani skup
dijelimo prema broju soba u stanu:

34
10 – 15
29
15
11
20
3
20 – 40
8
Ukupno:
3 742
Odredimo prosječno trajanje kazne po jednom izvršiocu, te varijansu i standardnu
devijacijutrajanja kazni. U tablici imamo ukupno 7 pravih razreda i dva obilježja koja nisu
grupisanau razrede. Za svaki pojedini razred računamo
razrednu sredinu
, a potom i vaganu
aritmetičkusredinu:
Trajanje kazne
(godine)
Broj izvršitelja (f
i
)
Razredna
sredina (x
i
)
f
i
x
i
f
i
(
X
i
−
X
)
2
0 – 1
2 535
0.50
1267.50
1 866,17
1 – 2
658
1.50
987
13,26
2 – 3
232
2.50
580
302,56
3 – 5
164
4
656
1 144,74
5 – 10
102
7.50
765
3 847
10 – 15
29
12.50
362.50
3 600,18
15
11
15
165
2 047,14
20
3
20
60
1 042,57
20 – 40
8
30
240
6 562,91
Ukupno:
3 742
5083
20 426,53
Vagana aritmetička sredina jednaka je:
35
X
=
∑
i
=
1
k
f
i X
i
N
=
5083
3742
=
1,358god
σ
²
=
∑
i
=
1
N
f
i
(
X
i
−
X
)
2
N
=
20 426,53
3742
=5,45 god
σ
=
√
σ
²
=
¿
2,33 god.
1.3.3.1.Koeficijent varijacije
Vec smo istakli da je standardna devijacija potpuna apsolutna mjera disperzije iskazana u
jedinicamaposmatranog kvantitativnog obilježja. Kao takva, standardna devijacija nije
pogodna zapoređenjepromjenljivih sanajmanje dva različita tipa kvantitativnih obilježja
premakojima se može podijeliti isti statistički skup. Posmatramo li npr. skup svih takmičara
uizboru za ovogodišnjeg Mistera i podijelimo li sve njegove elemente prema obilježjima
masa
i
visina
, onda na osnovu standardne devijacije ne možemo reći razlikuju lise
posmatranitakmičari više prema masi ili prema visini. U takvim se slučajevima
obavezno
primjenjuju
relativne mjere disperzije
jer one ne zavise o ''mjernim jedinicama''
posmatranogobilježja. Koeficijen varijacije je odnos standardne devijacije i aritmetičke
sredine pomnožen sa sto:
V=
σ
X
100
Dvije najčešce primjenjivane mjere su
koeficijent varijacije
i
koeficijent kvartilnedevijacije
, a
koriste se ponajprije za poređenje varijabiliteta. Slobodno govoreći, možemo reci da je
koeficijent varijacije
zapravo prosječno odstupanje vrijednosti kvantitativnoga obilježja od
aritmetičke sredineiskazano u postotcima. Koeficijent varijacije nezavisno otome jesu li podaci
grupirani ili nisu računamo prema istoj formuli.
Istaknimo da se koeficijent varijacije primijenjuje gotovo isključivo u statistickoj
analizikvantitativnih obilježja vezanih za
ordinalnu
skalu (zbog dogovorno definirane nule
nijeprimjenjiv u obilježjima vezanima za
intervalnu
skalu). Njegovi osnovni nedostaci su
lošareprezentativnost u slučaju ekstremnih vrijednosti ili otvorenih razreda, te osjetljivost na
malepromjene aritmetičke sredine u slučajevima kad je aritmetička sredina vrlo blizu nuli.
Primjer 1.
Utvrdimo varijabilitet navršenih godina starosti svih nezaposlenih osoba uSomaliji
u februaru 2008. godine:

37
Ovakvi problemi rješavaju se računanjem vrijednosti tzv.
standardiziranoga obilježja
(oznaka:
z-obilježje; z-skoro
).Standardizirano obilježje služi za utvrđivanje položaja
numeričkog podatka u nizu. Riječje o linearnoj transformaciji vrijednosti kvantitativnoga
obilježja definisanoformulom
:
z
i
=
x
i
−
x
σ
i
=1,20.....N
gdje je uobicajeno
x
aritmeticka sredina, a standardna devijacija vrijednosti varijable
x
.Zbog
svog svojstva standardizirano obilježje ima veliku primjenu.Njegovo svojstvo je:
Aritmetička
sredina standardiziranog obilježja jednaka je nuli, a standardna devijacija jedan
tj:
z
=0 ;
σ
z
=
1
Standardizirano obilježje pokazatelj je relativnog položaja pojedinačne vrijednosti
numeričkog obilježja u nizu, ne zavisi o mjernim jedinicama, može poslužiti za poređenje
položaja podataka u različitim nizovima.Standardizirana obilježja može imati različite
vrijednosti, koje mogu biti pozitivne ili negativne.Po pravilu rijetko odstupaju od aritmetičke
sredine za više od tri standardne devijacije na lijevu ili desnu stranu., pa s tim u vezi koristi se
teorema Čebiševa.Prema teoremi pojas od
X ±
2σ obuhvata najmanje proporciju od 75% svih
podataka, pojas od
X ±
3σ sadrži najmanje 88,89% podataka.
1.4.
Vrste distribucija
Podjela statističkih skupova prema
kvantitativnim
obilježjima grupišemo prema tome kakosu
vrijednosti obilježja elemenata tog skupa raspoređene oko najvažnije srednje
vrijednosti:aritmetičke sredine. Prema tome razlikujemo tri osnovne vrste statističkoga skupa:
Ako su vrijednosti obilježja elemenata statističkoga skupa ravnomjerno raspoređene
okoaritmetičke sredine, govorimo o
simetrč
c
noj distribuciji
.
Kod simetrične distribucije sve
tri srednje vrijednosti su jednake (
X
=
Me
=
Mo
)
.
Ako skup vrijednosti obilježja elemenata statističkoga skupa sadrži bar jednu
ekstremnoveliku
vrijednost, govorimo o
pozitivno asimetričnoj distribuciji
. Kod pozitivnoasimetrične
distribucije vrijede nejednakost:
X
>
Me
>
Mo
.
38
Ako skup vrijednosti obilježja elemenata statističkoga skupa sadrži bar jednu
ekstremnomalu
vrijednost, govorimo o
negativno asimetri
č
noj distribuciji
. Kod negativnoasimetrične
distribucije vrijede nejednakosti:
X
<
Me
<
Mo
.
1.4.1.
Mjere asimetrije
Pri opisu distribucije vrijednosti obilježja elemenata određenoga statističkog skupa,
osimsrednjih vrijednosti i mjera disperzije, koristimo i
mjere asimetrije
. Tim mjerama nastoji
sejednim numeričkim pokazateljem opisati
na
č
in rasporeda
kvantitativnih
podataka
premaaritmetičkoj sredini ili nekoj drugoj srednjoj vrijednosti. U praksi se najcešce koriste tri
mjereasimetrije:
1.)
Pearsonovamjera asimetrije
(oznaka:
Sk
) je mjera asimetrije definirana kao
omjer
aritmeti
c
ke sredine x i medijana Me
, odnosno
moda Mo
,
izražen u jedinicama standardne
devijacije .
U simetričnim distribucijama kontinuirane varijable sve su tri vrijednosti
jednake, pa je razlika moda ili medijana i aritmetičke sredine jednaka nuli. U pozitivno
asimetričnim distribucijama ta je razlika pozitivna, a u negativno asimetričnim razlika je
negativna. Pearsonova mjera uobičajeno poprima vrijednosti iz intervala +3, ali moţe biti
i izvan tog intervala.
Pearsonova mjera asimetrije:
S
k
=
(
x
−
M
o
)
σ
;
S
k
1
=
3
(
x
−
M
e
)
σ
2.)
Bowleyevamjera asimetrije
(oznaka:
SkQ
) racuna se iz medusobnoga odnosa
tri kvartila
:
prvog (
Q
1), trećeg (
Q
3) i medijana (
Me
). Na temelju toga odnosa odreduje se
asimetri
c
nost središnje polovice
(središnjih 50%)
elemenata ure
d
enoga statisti
c
koga
niza
.U simetričnom rasporedu vrijednosti razlika gornjeg kvartila i medijana, jednaka je
razlici medijana i donjeg kvartila tj. Q1+ Q3-2Me=0
U pozitivno asimetričnom rasporedu razlika gornjeg kvartila i medijana veća je od razlike
medijana i donjeg kvartila, a u negativno asimetričnom razlika gornjeg kvartila i
medijana manja je od razlike medijana i donjeg kvartila.
Mjera poprima vrijednosti iz intervala + 1.Računamo je prema formuli:
S
kQ
=
Q
1
+
Q
3
+
2
M
e
Q
3
−
Q
1

40
Standardna devijacija = 6,03
μ
₃
=
∑
i
=
1
N
f
i
(
x
i
−
x
)
³
N
=
839,919
90
=9,32
α
3
=
μ
3
δ
3
=
9,32
6,03
3
=0,043
1.4.2. Mjere zaobljenosti
Vecina pojava u prirodi, raznim privrednim i tehničkim procesima i sl. raspoređena je uskladu
s tzv.
normalnom distribucijom
. Ova se distribucija vrlo precizno definiše u
matematičkojstatistici i za to je potreban nešto složeniji aparat teorije vjerojatnoće. Ovdje
ćemo samonapomenuti da je riječo potpuno simetričnoj unimodalnoj distribuciji takvoj da se
otprilike svipodaci (tačnije,njih 99.73% ) posmatranog obilježja nalaze u rasponu [
x
– 3,
x
+
3],gdje je
x
aritmetička sredina, a
δ
standardna devijacija distribucije. Ova je činjenica
korisna pri procjenjivanju je li neka distribucija (približno) normalna ili nije.
S obzirom na veliki značaj normalne distribucije u statistici, definisane su posebne mjere
kojima se pojedine distribucije uspoređuju s normalnom. To su tzv.
mjere zaobljenosti.
Zaobljenost u okolini modalnog vrha krivulje distribucije frekvencija brojčano se opisuje
koeficijentom zaobljenosti.Koeficijen je definisan kao odnos četvrtog momenta oko sredine i
standardne devijacije na četvrtu potenciju.
Koeficijent je:
α
4
=
μ
4
δ
4
Zaobljenost normalne distribucije mjerena koeficijentom zaobljenosti iznosi 3., ako je za neku
empirijsku distribuciju vrijednost koeficijenta veća od 3, ta je distribucija šiljastija od
normalne,a ako je koeficijent manji od tri , tada je distribucija plosnatija od normalne.da bi se
izračunala vrijednost koeficijenta zaobljenosti , potrebno je odrediti vrijednost četvrtog
momenta oko sredine.Četvrti moment oko sredine je prosječno odstupanje vrijednosti
numeričkog obilježja od njezine aritmetičke sredine podignuto na četvrtu potenciju.
μ
4
=
∑
i
=
1
N
(
x
i
−
x
)
4
N
za negrupisane podatke
41
μ
4
=
∑
i
=
1
N
f
i
(
x
i
−
x
)
N
za grupisane podatke
Primjer 1.Izračunavanje mjera asimetrije
Tabela: Učesnici saobraćajnih nesreća prema godinama starosti
Godina
starosti
Broj
sudionik
a
f
i
Precizne
granice
Sredin
a
razred
a Xsi
Veli
ĉina
razre
da
fi Xsi
fi (Xi
-X)³
fi (Xi
-X)4
0-4
12
0-5
2,5
5
3,0
-11294
,13
110684,1
5-9
20
5-10
7,5
5
150,0
-2211,
8
10616,83
10-14
28
10-15
12,5
5
350,0
0,224
0,0448
15-19
19
15-20
17,5
5
332,5
2871,2
13872,07
20-24
11
20-25
22,5
5
247,5
11673,
288
119067,5
ukupno
90
-
-
-
1110,
838,91
254260,6
μ
4
=
∑
i
=
1
N
f
i
(
x
i
−
x
)
N
=
254260,6
90
=2825,12
α
4
=
μ
4
δ
4
=
2825,12
6,03
4
=
2,1368
Koeficijent zaobljenosti je manji od 3, pa se može zaključiti da se radi o distribuciji koja je
plosnatija od normalne.
1.5.
Programska pomoć deskriptivnoj statističkoj analizi
Danas je u uporabi više različitih računarskih programa namijenjenih statističkim
analizama.Najpoznatiji od njih su
SAS
,
SPSS
i
STATISTICA
. U
MS EXCEL
-u potpunu
statističku analizuvrijednosti
kvantitativnoga
obilježja elemenata statističkoga skupa možemo
dobiti koristeći alat
Descriptive Statistics
smještenu u izborniku
Alati
(
Tools
), opcija:
Analiza
podataka
(
DataAnalysis
). Taj je alat dio
Analysis ToolPak
alata za analizu, a stvara statistički

43
2.TEORIJA VJEROVATNOĆE
Dio matematike koja proučava slučajne pojave jeste upravo
teorija vjerovatnoće
. Postanak
teorije vjerovatnoće pripadali su hazardnim igrama, a posebno igrama sa kockom. Prva
teorijska razmatranja o teoriji vjerovatnoće nalaze se kod francuskih matematičara Bleza
Paskala i Pjera Ferma. Švajcarski matematičar Jakov Bernuli dokazao je zakon velikih
brojeva (Bernulijev zakon) i time otvorio novu oblast u teoriji vjerovatnoće i njenu primjenu u
statistici.
Značajan rezultat u razvoju teorije vjerovatnoće dali su francuski matematičari Abraham De
Moavr i Pjer Laplas, a njemački matematičar Karl Gaus je analizirao slučajne greške pri
mjerenju i došao do normalnog zakona (Gausov zakon normalne krive). Ruski matematičar
Čebišev i njegovi učenici A.Markov, A.Ljapunov i A.Kolmogorov takođe su dali značajan
razvoju i primjeni teorije vjerovatnoće, čime je ova teorija postala ravnopravna matematička
disciplina sa geometrijom i algebrom.
2.1.Osnovni pojmovi vjerovatnoće
U okviru osnovnih pojmova iz teorije verovatnoće neophodno je prije svega definisati: Ako
izvodimo neki eksperiment rezultat tog eksperimenta nazivaju se
događaji.
Svaki proces
posmatranja nekog događaja naziva se
eksperiment
,
ogled(pokus)
,a rezultat takvog
posmatranja je
ishod
.
Neki događaji proizilaze uvijek prilikom izvođenja eksperimenta i njih nazivamo
sigurnim
događajima
. Za događaje koji se ne mogu pojaviti pri izvođenju eksperimenata kaže se da je
nemoguć događaj
. Slučajan događaj nastupa sa nekom vjerovatnoćom, jer unaprijed se ne
može utvrditi njegov ishod.
Primjer 1
:
Kolika je vjerojatnoća da će kod bacanja novčića,novčić pasti na ”pismo”?
2.2..Vrste vjerovatnoće
Postoje sljedeće vrste vjerovatnoće:
- Klasična vjerovatnoća(a priori)
- Statistička vjerovatnoća(a posteriori)
- Subjektivna vjerovatnoća
- Geometrijska vjerovatnoća
44
- Uslovna vjerovatnoća
- Totalna vjerovatnoća i Bajesova formula
2.2.1. Klasična vjerovatnoća (a priori)
Klasična (a priori) vjerovatnoća nekog događaja predstavlja odnos broja za njega povoljnih
ishoda (m) prema broju svih jednako mogućih ishoda (n). Ili još jednostavnije: ako se jedan
događaj (A) može desiti na (m) načina, onda se vjerovatnoća ostvarenja događaja (A) izražava
odnosom
:
p(A)=
m
n
0 ≤ p(A) ≤ 1.
Vjerovatnoća da će se desiti neki događaj označava se s p, a vjerovatnoća da se neći desiti
neki događaja s q. Prema tome vjerovatnoća nenastupanja nekog događaja bit će
q
=
1
−
p
Ako je potpuno sigurno da će se neki događaj dogoditi onda je vjerovatnoća tog događaja
p=1, a takav događaj naziva se siguran događaj (npr. Poslije noći dolazi dan).
Ako je potpuno sigurno da se neki događaj neće dogoditi onda je vjerovatnoća tog događaja
p=0, a takav događaj naziva se nemoguć događaj (npr. Visina čovjeka je 100 metara).
Događaji čija je vjerovatnoća nastupanja veća od 0 i manja od 1 nazivaju se vjerovatni
događaji, a njihova vjerovatnoća je
0 < p < 1.
Samo vjerovatni događaji predmet su izučavanja.
Primjer 1:
Posmatrajući slučajan eksperiment u kojem bacamo pravilnu kocku i zbog
simetričnosti kocke prihvatamo predpostavku o jednakoj mogućnosti javljanja svake strane
kao ishoda eksperimenta. Kako je n=6, vjerovatnoća javljanja svake pojedinačne strane iznosi
P
(
A
)=
1
6
.
2.2.2.Statistička vjerovatnoća
Statistička vjerovatnoća je vjerovatnoća slučajnog događaja A ako se neki eksperiment može
pod istim uslovima ponoviti neograničen broj puta. Izračunava se na osnovu sledeće formule:

46
Ako je dat
a
1
;
a
2
… . a
n
povoljnih, međusobno isključivih, elementarnih događaja onda je
vjerovatnoća da će se dogoditi bilo koji od tih događaja
a
i
(i=1,2,...,n) jednaka zbiru
vjerovatnoća nastupanja pojedinih događaja. To znači da je:
p = p(
a
1
)+p(
a
2
)+p(
a
3
)+...+p(
a
n
)
Npr. kod bacanja kocke dogadaji A = ”pojavit će se paran broj manji od 6 i B = pojavit će se
neparan broj manji od 5” su međusobno isključivi jer nijedan od elementarnih dogadaja
(pojavljivanje 1, 2, 3, 4, 5 ili 6), ne vodi na istovremeno ostvarenje dogadaja A i B. Oni vode
na ostvarenje ili događaja A ili događaja B.
Za dva događaja A i B kažemo da su isključivi, ako ne postoji elementarni događaj koji
ostvaruje oba ova dogadaja.Iz ovog slijedi da je vjerovatnoća :
P(AiliB)=P(A)+P(B)
Primjetimo da znak + kada stoji između događajima, ne znači isto kao i
znak + kada stoji između brojeva. Takoder riječ ili ovdje ima svoje
isključivo
značenje:ili
jedno ili drugo, ali ne i oba zajedno.
Zakon multiplikacije:
Ako su dati povoljni elementarni događaji
a
1
;
a
2
…..
a
n
koji se međusobno ne isključuju (mogu
se istovremeno pojaviti), vjerovatnoća da će nastupiti više takvih nezavisnih događaja
istovremeno jednaka je proizvodu vjerovatnoće pojavljivanja svakog od tih događaja. To
znači da je
p = p(
a
1
) x p(
a
2
) x p(
a
3
) x ...x p(
a
n
).
Pretpostavimo sada da postoje dva dogadaja A i B čija se ostvarenja međusobno ne
isključuju. Npr. bacaju se istovremeno novčić i kocka.
Događaj A je
da će novčić pasti
na“pismo” (bez obzira na kocku), a događaj B je da će kocka pasti na paran broj(bez obzira
šta pokazuje novčić).Svaki mogući događaj od A možemo kombinovati sa svakim mogućim
događajem od B I tako dobijemo da je vjerovatnoća događaja A I događaja B:
P(A i B) =P(A) x P(B)
47
Slučajna promjenljiva
, x, je promjenljiva koja poprima pojedinačne vrijednosti s određenom
vjerovatnoćom. Dva su osnovna tipa:
diskretna ili diskontinuirana
slučajna promjenljiva:
numeričke vrijednosti su cijeli brojevi (primjer: broj nezrelih ćelija u nekom preparatu može
biti 0;1;2..k
kontinuirana
slučajna promjenljiva: numeričke vrijednosti su realni brojevi
(primjer: težina 72,35 kg, glukoza u krvi 7,2 mmol/l ).
Distribucija(raspodjela)vjerovatnoće
prikazuje način na koji je ukupna
vjerovatnoćaraspodijeljena na pojedine vrijednosti slučajne promjenljive.Svaku distribuciju
vjerovatnoće definišu parametri (npr. prosjek, varijansa).
Zavisno od tipa slučajne
promjenljive i distribucije dijelimo na diskretne i kontinuirane.
Diskretne distribucije vjerovatnoće
:
Možemo izvesti vjerovatnoću za svaku moguću
vrijednosti slučajne promjenljive.Zbir svih mogućih vjerovatnoća slučajne promjenljive je
1.Primjeri: Binomna raspodjela, Poissonova raspodjela.
Binomna distribucija
:To je teorijska distribucija za diskretne slučajne promjenljive kada
imamo dva moguća ishoda,jedan je “uspjeh” I drugi “neuspjeh”, u “n” mogućih događaja.Pri
čemuje vjerojatnoća da u seriji od n ogleda događaj A nastupi tačno x puta.
P(x)=
(
n
x
)
p
x
q
n
−
x
Skup svih parova {x, P(x)}, x = 0, 1, 2, ..., n čini binomnu distribuciju.
Osnovne karakteristike binomne distribucije
:

49
1. parametar koji opisuje Poissonovu distribuciju je aritmetička sredina
2. aritmetička sredina i varijansa imaju jednake vrijednosti;
3. unimodalna je krivulja, zakrenuta u desno kada je vrijednost aritmetičke sredine mala;
4. kako raste aritmetička sredina, asimetrija se smanjuje i na kraju aproksimira normalnu
raspodjelu.
Slika br: Poissonova distribucija
Kontinuirane distribucije vjerovatnoće:
Vjerojatnoćase izvodi za slučajnu promjenljivu, x,
koja poprima vrijednosti u određenim razredima.
Vrijednosti promjenljive x predstavlja horizontalana os, prema jednačini distribucije može se
nacrtati kriva. Ova jednačina zove se funkcija gustoće vjerojatnoće.Površina ispod krive
iznosi 1 i ujedno je vjerovatnoća svih mogućih događaja.Površina ispod krive između dvije
vrijednosti jednaka je vjerovarnoći da x leži između dvije vrijednosti.
Sloka br: Vjerovatnoća da x leži
između dvije vrijednosti
50
U kontinuirane distribucije vjerovatnoće ubrajamo:normalna distribucija,
x
2
distribucija; t
distribucija, F distribucija.
Normalna distribucija
:najčešće primjenjivana distribucija.Primjenjuje se u modelima analize
podataka, a veliki broj bioloških mjerenja ima normalnu distribuciju.
Slika br.Standardna normalna distribucija (zeleno)
Karakteristike normalne distribucije:
1.Aritmetička sredina i varijansa je opisuju
2.područje slučajno promjenljive x je(
−
∞
+
∞
)
3.zvonolikog je oblika i unimodalna;
4.ukoliko se povećava vrijednost aritmetičke sredine kriva se pomiče udesno, a ukoliko se
vrijednost aritmetičke sredine smanjuje kriva se pomiče ulijevo (uz pretpostavku jednake
varijanse);
Slika br: Kriva normalne distribucije sa različitim vrijednostima aritmetičke sredine
5. simetrična oko aritmetičke sredine;
6.ukoliko se vrijednost varijanse povećava kriva se snižava i širi, a ukoliko se vrijednost
varijanse smanjuje kriva se povisuje i sužava (uz nepromijenjenu aritmetičku sredinu);

52
Studentova t-distribucija:
Karakteristike Studentove t-distribucije:
1.karakterišu je stepeni slobode;
2. ima sličan oblik kao normalna distribucija samo što je šira i položenija;
3. kako raste broj stepena slobode oblikom je sve sličnija normalnoj raspodjeli;
4.primjenjuje se u računanju intervala pouzdanosti i testiranju hipoteza o razlici između dva
uzorka.
Slika br.. Kriva t – distribucije
X
2
distribucija
se definiše kao zbir odnosa kvadrata razlika izmeđustvarnih i očekivanih
vrijednosti prema očekivanim vrijednostima.
Slika br. Krivulja
X
2
distibucije
1. distribucija je pozitivnih vrijednosti, zakrivljena u desno;
2. karakterišu je stepeni slobode;
3.oblik distribucije zavisi o broju stepena slobode: kako raste broj stepena slobode distribucija
postaje sve više simetrična i sličnija normalnoj distribuciji
4. primjenjuje se u analizi kategorijskih podataka.
53
F distribucija
se koristi ukoliko se želi ustanoviti da li je promjenljivost osnovnog skupa veća
ili manja od promjenljivosti drugog osnovnog skupa.Kao pokazatelj se uzima odnos dviju
varijansi.
Slika br :F distribucija
Opšte karakteristike F distribucije:
zakrivljena prema desno;
1.distribucija je omjera dvije varijanse izračunatih iz normalno distribuiranih podataka;
2. karakterišu je stepeni slobode brojnika i nazivnika omjera varijansi;
3. upotrebljava se za poređenje dvije varijanse, kao i za poređenje više od dvije aritmetičke
sredine analizom varijance.
2.3.Kombinatorika
Teorija vjerojatnoće i statistika koristi pojmove i rezultate jednog dijela
matematike koji se zove
kombinatorika
.Kombinatorika se bavi prebrojavanjem elemenata
konačnih skupova i prebrojavanjem broja načina da se ti elementi poredaju.
Da bi mogli razumjeti pojmove kombinatorike , moramo ponoviti već poznate pojmove:
Faktorijel
nekog prirodnog broja je proizvod svih prirodnih brojeva koji su manji ili jednaki
njemu.Označava se
n!
(n faktorijel), računa se na sljedeći način:
n!=n
∙
(
n
−
1
)
∙
(
n
−
2
)
∙∙∙∙∙
2
∙
1
Po definiciji 0!=1
Primjer1
:Koliko je 5!
5!=5
∙
4
∙
3
∙
2
∙
1
=
120
Binomni koeficijent:
neka su
n
i
r
prirodni brojevi, za koje vrijedi
r
≤ n
,
tada
binomni koeficijent
označavamo
(
n
r
)
i računamo po formuli:

55
P
10
3,2,2
=
10
!
3
!
2
!
2
!
=151200 ; od slova riječi matematika može se napisati 151 200 riječi.
2.Varijacije
su dio kombinatorike kod koje na dva postavljena pitanja dobijemo jedan
potvrdan odgovor (raspored izabranih elemenata je bitan) i jedan negativan odgovor(nisu svi
elementi početnog skupa izabrani).Varijacije mogu da budu sa i bez ponavljanja.
Varijacije bez ponavljanja
.Varijacije r-te klase ćemo dobiti tako što ćemo prvo dobiti sve
kombinacije r-te klase koje ćemo permutovati.Varijacijesu permutirane kombinacije.
Varijacije su skupine određenog broja elemenata odabranih iz skupa od n elemenata
razmještenih na sve moguće načine.
Broj varijacija r-te klase od n elemenata bez ponavljanja računamo po formuli:
V
n
k
=
n !
(
n
−
r
)
!
Primjer 1
:
Koliko ima trocifrenih brojeva, čiji su brojevi različiti elementi skupa S=
{
1,2,3,4,5,6,7,8
}
V
3
8
=
8
!
(
8
−
3
)
!
=
8
!
5
!
=336
Varijacije sa ponavljanjem
Kod varijacija sa ponavljanjem svaki se element u varijaciji r-te
klase može pojaviti r puta.Broj varijacija sa ponavljanjem
r-te
klase skupa od
n
elemenata je:
V
r
n
=
n
r
Primjer 1
:
Na koliko se različitih načina može popuniti test s 10 pitanja i 3 ponuđena
odgovora na svako pitanje?
Na svako pitanje može se odgovoriti s jednim od tri ponuđena odgovora, te
V
3
10
=
3
10
=59.049 načina popunjavanja testa
3.Kombinacije
na dva pitanja daju dva negativna odgovora(nisu svi elementi početnog skupa
izabrani) i (raspored izabranih elemenata nije bitan).
I kombinacije mogu biti sa i bez ponavljanja.
Kombinacije bez ponavljanja
r-te klase su podskupovi zadanog skupa od
n
elemenata u
kojima se isti element pojavljuje samo jednom.
Ukupan broj kombinacija r-te klase od
n
elemenata iznosi:
K
n
k
=
(
n
k
)
=
n !
(
n
−
r
)
! r !
Primjer 1
:Skup se sastoji od 20 proizvoda.na koliko se načina može formirati uzorak od 5
proizvoda.
56
K
n
k
=
(
n
k
)
=
n !
(
n
−
r
)
! r !
=
20
!
15
!
=
16
∙
17
∙
18
∙
19
∙
20
120
=15.504
Kombinacije sa ponavljanjem:
Kod kombinacija sa ponavljanjem broj elemenata u podskupu
može biti manji, jednak ili veći od broja zadanih elemenata (r
≥
n) tj da se isti element u
podskupu
r
-teklase može pojaviti
r
puta.
Broj kombinacija s ponavljanjem r-te klase od
n
zadanih elemenata jednak je broju
kombinacija r-teklase bez ponavljanja od (n+r -1) elemenata:
K
n
k
=
(
n
+
r
−
1
r
)
Primjer 1
: U cvjećari se prodaju mini ruže, ruže i ljiljani.Na koliko načina je moguće
napraviti buket od 9 cvjetova?
K
n
k
=
(
n
+
r
−
1
r
)
=
(
9
+
3
−
1
9
)
=
11
!
9
!
2
!
=55 ,
buket možemo napraviti na 55 načina
2.3. Subjektivna vjerovatnoća
U praksi često dešavaju događaji koji se javljaju samo jedanput, ili su okolnosti u kojima su
oni ponavljaju među sobom toliko različiti da događaj moramo posmatrati kao jedinstvene
(plasman novog proizvoda, rezultati političkih izbora i slično). U ovakvim situacijama,
vjerovatnoću neizvjesnih događaja ne možemo da odredimo empirijskim putem, a često ne
možemo ni da prihvatimo predpostavku klasične koncepcije o jednakim vjerovatnoćama svih
elementarnih događaja. Tada koristimo tzv.
subjektivnu vjerovatnoću
.
Po ovoj koncepciji, vjerovatnoća predstavlja stepen uvjerenja koji osoba ima za ostvarenje
datog događaja kao ishoda slučajnog eksperimenta. Pojedinac na osnovu znanja, iskustva i
raspoloživih informacija pripisuje događaju broj od 0 do 1 kojima izražava svoje uvjerenje u
mogućnost javljanja datog događaja.Subjektivna vjerovatnoća se koristi u teoriji odučivanja u
uslovima neizjvesnosti koja je poznata pod nazivom Bayesova teorija odlučivanja. Ona se
dosta izučava, naročito u vezi sa kockanjem i tržištima hartija od vrijednosti. Prednost
subjektivne vjerovatnoće je što može da se dopiše svakom događaju, pa čak i onom koji se
dešava samo jednom ili situaciji koja ne uključuje slučajni proces.
2.4.Uslovna vjerovatnoća
Imamo dva događaja, događaj A i događaj B ;ako je realizacija
događaja A uslovljena nastupanjem još nekog drugog događajaB tada se vjerovatnoća
događaja A pod uslovom da se desio događaj B naziva
uslovnomvjerovatnoćom
i obilježava
se
sa
P(A|B).
Posmatrajući neki eksperiment od dva slučajna događaja A i B. Ako je poznato da se jedan od

58
Primjer 1
.
U jednoj kutiji nalazi se 6 bijele i 7 crnih kuglica, a u drugoj 4 bijele i 8 crnih.
Izvlačimo iz svake kutije po jednu kuglicu. Odrediti vjerovatnoću da je iz obe kutije izvučena
bijela?
Događaj A: bijela kuglica iz prve kutije
Događaj B: bijela kuglica iz druge kutije.
Događaji A i B su nezavisni.
P
(
AB
)=
P
(
A
)
∙ P
(
B
)=
6
12
∙
4
12
=
1
6
2.5.Totalna vjerovatnoća i Bajesova formula
Ukoliko se dogadjaj H
1
,H
2
,.....H
n
, međusobno isključuju realizacija proizvoljnog događaja A
mora se realizovati uz realizaciju bar jednog od ovih događaja Vjerovatnoće P(H
i
) su obično
poznate unaprijed prije realizacije eksperimenta pa se često nazivaju apriornim
vjerovatnoćama, a sami događaji hipiotezama.
Ako događaji H
1
,H
2
,.....H
n
, čine potpun sistem događaja, i ako je A neki događaj, tada
formula za totalnu vjerovatnoću glasi:
P(A)=P(H
1
)P(A| H
1
)+P(H
2
)P(A| H
2
)+···+P(H
n
)P(A| H
n
).
Primjer1.U fabrici "Volkswagen" 40% proizvidnje otpada na prvu mašinu, 30% na drugu
mašinu i ostalo na treću mašinu. Na prvoj mašini pojavljuje se 2% škarta, na drugoj mašini
3% i na trećoj mašini 4% škarta. Tokom dana ove mašine proizvedu 10.000 artikala.Koliko je
vjerovatnoća da će slučajno izabrani proizvod biti škart?
A je događaj da je slučajno izabrani proizvod škart.
H
1
,H
2
,H
3
su proizvodi izrađeni na mašinama.
P(H
1
)= 0.40 P(H
2
) =0.30 P(H
3
)= 0.30
P(A|H
1
)= 0.02 P(H
2
) =0.03 P(H
3
)= 0.04
P (A| H(A)=P(H
1
)P(A| H
1
)+P(H
2
)P(A| H
2
)+P(H
3
)P
3
)=0.008+0.009+0.012=0.029
Za totalnu vjerovatnoću je vezana Bayesova formula.
Ako događaji H
1
,H
2
,.....H
n
, čine potpun sistem događaja, i ako je A neki događaj, tada je
P(A)
≠
0 tada je za svako
i
= 1.2,....,n
P
(
H
1
∨
A
)=
P
(
AHi
)
P
(
A
)
=
P
(
Hi
)
P
(
A
∨
Hi
)
P
(
H
1
)
P
(
A
|
H
1
)+
P
(
H
2
)
P
(
A
|
H
2
)+
···
+
P
(
Hn
)
P
(
A
|
Hn
)
"
59
Bajesova formula
se koristi kada je potrebno odrediti vjerovatnoću nekog događaja koji je
prethodio
ostvarenju
konačnog
događaja.
Primjer 2.
U prvoj kutiji se nalaze 9 listića numerisani brojevima od 1-9, a u drugoj kutiji se nalazi 5
listića numerisani brojevima od 1-5. Biramo nasumice kutiju i iz nje izvlačimo jedan listić.
Ako je broj na listiću paran izračunati kolika je vjerovatnoća da je listić izvađen iz prve
kutije?
M : izvađen je paran broj
H
1
- izabrana je prva kutija
H
2
- izabrana je druga kutija
P
(
H
1
)=
1
2
P
(
H
2
)=
1
2
, , jer imamo dvije kutije od kojih biramo jednu
,
P
(
M
|
H
1
)=
4
9
, , pošto iz prve kutije ima
4
parna broja
(
2,4,6,8
)
P
(
M
|
H
2
)=
2
5
, pošto iz druge kutije ima
2
parna broja
(
2.4
)
P(M)=P(H
1
)P(M| H
1
)+P(H
2
)P(M| H
2
)
P
(
M
)=
1
2
∗
4
9
+
1
2
∗
2
5
=
19
45
Totalna vjerovatnoća iznosi
19
45
.
Vjerovatnoća da ako je izvučen paran listić, da je uzet iz kutije A se obilježava P(H
1
|M) i
računa se na sljedeći način
::
P
(
H
1
∨
M
)=
P
(
H
1
)
P
(
M
∨
H
1
)
)
P
(
M
)
P
(
H
1
∨
M
)=
1
2
∙
4
9
19
45
=
10
19
II DIO

61
koeficijenta jednostavne , višestruke i parcijalne korelacije, koeficijenta korelacije ranga i
koeficijenta asocijacije.
Regresijska analita modela uključuje ocjenjivanje nepoznatih parametara, računanje mjera
disperzije,primjena postupaka o modelu kojim se ispituje kvalitet dobivenih podataka.
Područje korelacijske i regresijske analize u čvrstoj su vezi.Ako je primarni cilj istraživanja
utvrđivanje prediktivnog oblika odnosa, polazi se od regresijskog modela i njegove analize, a
zatim nastavlja sa korelacijskom analizom.
2.2. Model jednostavne regresije
Ovim modelom se izražava odnos između dvije pojave.Vrijednosti pojave čije se
promjenljivosti objašnjavaju predstavljaju vrijednost zavisno promjenljive Y , dok stvarne
vrijednosti pojave kojom se objašnjava promjenljivost prve pojave predstavljaju vrijednost
nezavisno promjenljive X.Opšti oblik modela jednostavne regresije :
Y = f(X) +u
Kod ovog modela izbor oblika modela svodi se na izbor funkcije
f(X)
.Oblik funkcije zavisi od
priprode odnosa između analiziranih pojava.Npr. ukoliko se potrošnja u domaćinskvu mijenja
linearno s promjenama raspoloživog dohotka,
f(X)
će imati linearnu funkciju.
Pomoćno sredstvo za izbor oblika funkcije je
dijagram rasipanja
.To je grafički prikaz u
pravougaonom koordinatnom sistemu, pri čemu na osi apscise upisujemo vrijednosti
nezavisno promjenljive X , a na osi ordinate upisujemo zavisno promjenljivu Y.Prema
rasporedu tačaka donosi se prvi sud o obliku veze tj. obliku funkcije
f(X).
a)
b)
c)
d)
62
Slika br. Dijagrami rasipanja
Ako su tačke, u dijagramu rasipanja, raspoređene od donjeg lijevog do gornjeg desnog ugla
oko zamišljenog pravca, onda se odnos između pojava, analitički može izraziti pomoću
modela jednostavne linearne regresije.
Što je rasipanje oko pravca manje, povezanost je
uža.Ako su tačke raspoređene u dijagramu oko neke krive linije tada kažemo da se radi o
modelu krivolinijske regresije.Ako je riječ o linearnoj vezi, istovremeno se utvrđuje i
smjer
veze
.Po smjeru linearna veza može biti pozitivna ili negativna.Pozitivna je ako vrijednost
nezavisno promjenljive prati linearni ili približno linearni porast vrijednosti zavisno
promjenljive.Povećavali se vrijednost nezavisno promjenljive, a vrijednost zavisno
promjenljive linearno se ili približno linearno smanjuje, govorimo o negativnom smjeru
linearne veze.
2.2.1. Jednostavna linearna regresija
Za model jednostavne linearne regresije karakteristično je da promjene jedne pojave prati
približna linearna promjena druge pojave., ako se pođe od takve predpostavke u modelu
funkcija
f(X)
će imati sljedeći oblik:
f(X)= a+bX
Uzimajući u obzir opšti oblik modela i oblik linearne funkcije, model jednostavne linearne
regresije je:
Y= a+bX+u
U navedenom modelu X je nezavisno promjenljiva , a Y zavisno promjenljiva.Promjenljiva
u
predstavlja nepoznate uticaje na promjene promjenljive Y i predstavlja odstupanje od

64
a=
y
−
bx
Model jednostavne linearne regresije sa ocjenjenim parametrima ima ovaj oblik
^
y
=
a+bx
^
y
regresijska funkcija s ocjenjenim parametrima
a
je konstantni član, to je vrijednost regresijske funkcije za vrijednost nezavisne promjenljive
x=0.
b
je regresijski koeficijen i pokazuje za koliko se linearno mijenja vrijednost regresijske
funkcije za jedinični porast vrijednosti nezavisne promjenljive X.Predznak koeficijenta je
pozitivan ili negativan.
Primjer 1
.Analiziraj odnos po modelu jednostavne linearne regresije između broja zaposlenih
i iznosa poreza iz dohotka i ostalih dohodaka u budžetu odabranih 8 opština u 1989 godini.
Tabela br. Zaposleni i prihod od poreza odabranih zajednica opština
Zajednica
opština
Broj zapos.
U 000
Prihod u
Mil.
x
i
y
i
x
i
2
y
i
2
x
i
y
i
Sarajevo
Beograd
Titograd
Novi Sad
Priština
Zagreb
92,8
312,4
34,2
51,1
21,7
263,7
28,4
82,4
10,7
14,1
4,2
91,0
8611,84
97593,46
1169,64
2611,21
470,89
69537,69
806,56
6789,76
114,49
198,81
17,64
8281,00
2635,52
25741,76
365,94
720,51
91,14
23996,70
65
Ljubljana
Skoplje
54,9
56,9
16,4
20,1
3014,01
3237,61
268,96
404,01
900,36
1143,69
ukupno
887,7
267,3
186246,65
16881,23
55595,62
Za nezavisnu promjenljivu uzet je broj zaposlenih, a za zavisno promjenljivu iznos poreza iz
dohotka i ostalih dohodaka.
Model jednostavne linearne regresije:
y
i
=
a+b
x
i
+
u
i
a sa ocjenjenim parametrima
^
y
=
a+bx.
Treba prema formuli izračunati parametre
a i b:
b
=
∑
i
=
1
n
x
i
y
i
−
n x y
∑
i
=
1
n
x
i
2
−
n x
²
=
55595,62
−
8
∙
110.9625
∙
33.4125
186246,65
−
8
∙
110.9625²
=0,295575
Konstantni član
a
je:
a=
y
−
bx
=
33.4125
−
0,295575
∙
110.9625
=0,614759
Model jednostavne linearne regresije s ocjenjenim parametrima metodom najmanjih kvadrata
je.
^
y
=a+bx =
0,614759+0,295575
x
Tumačenje: ako se broj zaposlenih poveća za jednu hiljadu , regresijska vrijednost poreza od
dohotka i ostalih dohodaka povećat će se za 0,295575 milijona.
2.2.2.Regresijske vrijednosti, rezidualna odstupanja i analiza varijanse za model
jednostavne linearne regresije
Pomoću regresijske jednačine s ocjenjenim parametrima utvrđuju se
regresijske vrijednosti.
One su date izrazom :
^
y
=a+bx
Izračunavaju se uvrštavanjem empirijskih vrijednosti nezavisno
promjenljive X u jednačinu s ocjenjenim parametrima.Te vrijednosti predstavljaju ocjenu
nivoa zavisno promjenljive za date stvarne vrijednosti nezavisno promjenljive.

67
28.400
82.400
10.700
14.100
4.200
91.000
16.400
20.100
28.044
92.952
10.723
15.719
7.029
78.558
16.842
17.433
0.3559
-10.552
-0.02338
-1.619
-2.829
12.442
-0.4418
2.667
1.253
-12.806
-0.2186
-11.480
-67.350
13.673
-2.694
13.269
0,05171
-1.533
-0.003398
-0.2352
-0.4110
1.808
-0.06419
0.3875
Razlika između stvarne veličine prihoda za tu zajednicu i regresijske vrijednosti predstavlja
prvo rezidualno odstupanje:
u
i
=
y
i
-
^
y
i
=28.4-28.0441=0.3559
Prvo relativno rezidualno odstupanje je :
u
i rel
=
y
i
−^
y
i
y
i
∙
100
=
0.3559
28.4
∙
100
=1,253%
Po istom se postupku dolazi i do preostalih regresijskih vrijednosti, rezidualnih odstupanja i
relativnih rezidualnih odstupanja.Rezidualna odstupanja, odnosno odstupanje stvarne
vrijednosti za Sarajevo od procjenjene svega je 0.3559 milijona ili 1,253%
i
ˆ
i
y
C
У
Ukupno,objasnjeno i neobjasnjeno odstupanje zavisne promenljive У
i
68
Stepen varijacije stvarnih vrijednosti zavisne varijable u odnosu na procjenjene vrijednosti
pomoću regresije mjeri se različitim mjerama.Najvažnije su:
varijansa; standardna devijacija
i koeficijent varijanse regresije
.Mjere disperzije oko regresije služe kao pokazatelji za ocjenu
kvaliteta modela.Ukoliko se pogleda graf ispred , dolazi se do zaključka da je:
(
y
i
−
y
) =(
^
y
i
−
y
)
+
¿
(
y
i
−^
y
i
), ukoliko se kvadrira prethodni izraz dobit će se jednačina, temelj
analize varijanse:
∑
i
=
1
n
(
y
i
−
y
)
²
=
∑
i
=
1
(
n
( ^
y
i
−
y
)
²
+
∑
i
=
1
n
(
y
i
−^
y
i
)
²
Prvi član sa desne strane jednačine predstavlja zbir
kvadrata onog dijela odstupanja zavisne varijable koji je
protumačen
vezom između pojava,
dok drugi član s desne strane jednačine predstavlja zbir kvadrata onog dijela odstupanja
zavisne varijabe koji je ostao
neprotumačen.
Ukoliko se svaki član jednačine podijeli ukupnim zbirom kvadrata i ako se strane jednačine
zamjene, dolazi se do ukupnog zbira kvadrata u relativnom iznosu:
∑
i
=
1
(
n
( ^
y
i
−
y
)
²
∑
i
=
1
n
(
y
i
−
y
)
²
+
∑
i
=
1
n
(
y
i
−^
y
i
)
²
∑
i
=
1
n
(
y
i
−
y
)
²
=
1;
prvi član s lijeve strane jednačine naziva se
koeficijent
determinacije
,
U razvijenom obliku zbir kvadrata dati su jednačinama:
∑
i
=
1
n
(
y
i
−
y
)
²
=
∑
i
=
1
n
y
i
2
−
¿
n
y
²

70
∑
i
=
1
n
(
y
i
−
y
)
²
=
∑
i
=
1
n
y
i
2
−
¿
n
y
²=
16881,23-8
∙
3
3.4125²=7950.069
Neprotumačeni dio zbira kvadrata:
∑
i
=
1
n
(
y
i
−^
y
i
)
²
=
∑
i
=
1
n
y
i
2
−
¿
a
∑
I
=
1
n
y
i
−
¿
b
∑
i
=
1
n
x
i
y
i
=
16881,23-0.614759
∙
267.3 – 0.295575
∙
55595.62=284.216
Protumačeni dio zbira kvadrata je razlika ukupnog i neprotumačenog dijela:
∑
i
=
1
n
(
y
i
−
y
)
²
=
∑
i
=
1
(
n
( ^
y
i
−
y
)
²
+
∑
i
=
1
n
(
y
i
−^
y
i
)
²
=
7950.069 -284.216=7665.853
Pomoću rezidualnog zbira kvadrata izračunat će se varijansa regresije i standardna devijacija.
Varijansa regresije:
σ
^
y
2
=
∑
i
=
1
n
(
y
i
−^
y
i
)
²
n
=
284.216
8
=35.527
Standardna devijacija:
σ
^
y
=
√
∑
i
=
1
n
(
y
i
−^
y
i
)
²
n
=
√
35.527
=
5,960
Standardna devijacija regresije pokazuje da je prosječno odstupanje stvarnih vrijednosti
zavisne varijable od regresijskih vrijednosti prihoda 5,96 milijona.
Relativna mjera disperzije oko regresije je
koeficijent varijacije regresije:
V
^
y
=
σ
^
y
y
∙
100
=
5.960
33.4 125
∙
100=
17,838%
Stvarne vrijednosti prihoda odstupaju od procjenjenih vrijednosti u prosjeku 17.838%
Varijansa, standardna devijacija i koeficijent varijacije omogućavaju donošenje zaključka o
statističkoj reprezentativnosti modela, a u istu svrhu služi i koeficijent determinacije:
71
r
2
=
∑
i
=
1
(
n
( ^
y
i
−
y
)
²
∑
i
=
1
n
(
y
i
−
y
)
²
=
7665.853
7950.069
=
0,9642
Modelom jednostavne linearne regresije protumačeno je 96,42% odstupanja.Neprotumačeni
je dio 0,0358 ili 3,58%
U praksi se ponekad raspolaže s grupnim podacima o dvije numeričke promjenljive.Takvi
grupni podaci prikazani su u dvodimenzionalnoj tabeli.
2.3. Višestruka regresija
U modelu jednostavne regresije varijacije zavisne varijable objašnjavaju se pomoću varijacija
jedne nezavisne varijable i slučajne veličine(slučajnih odstupanja)U istraživanju često na
jednu pojavu djeluje više varijabli(na krvni pritisak djeluje dob;težina, spol i druge
promjenljive).Statističko –analitički se varijacija jedne pojave u zavisnosti od dvije pojave ili
o više njih izražava pomoću modela višestruke regresije.
Pojavu koja se objašnjava predstavljaju vrijednosti zavisne varijable, a za pojave pomoću
kojih se objašnjava varijacija date su brojčane vrijednosti i one predstavljaju vrijednosti
varijable u modelu višestruke regresije.
U analizi višestrukih odnosa polazi se od opšteg modela Y
= f (
X
1
,
X
2
⋯
X
K
) + u
,za primjenu
modela nužno je odrediti koja je varijabla zavisna, a koje su nezavisne.Zatim treba utvrditi
oblik funkcije u modelu(deterministički dio modela), te svojstva slučajne varijable.Često je
oblik funkcije
linearan,
a varijabla
u aditina
komponenta, pa je riječ o
modelu višestruke
linearne regresije.
2.4.Korelacijska analiza
Mjerenje stepana jakosti statističkih veza provodi se metodama
korelacijske
analize
.Korelacijska i regresijska analiza često su povezane.
Kod korelacije
pri analizi dvije pojave nije bitno koja je pojava označava kao nezavisna , a
koja kao zavisna varijabla.Međutim kod ispitivanja korelacione veze između tri ili više pojava
mora se prethodno jedna od njih definisati kao zavisna varijabla.
Cilj korelacione analize
je da se ispita da li između varijacija posmatranih pojava postoji
kvantitativno slaganje i, ako postoji, u kom stepenu.
Pokazatelji stepena statističkih veza su
koeficijenti korelacije
.Ako su odnosi dvije pojave
linearni u statističkom smislu, utvrđivat će se
koeficijen jednostavne linearne korelacije.
2.4.1.Koeficijent jednostavne linearne korelacije

73
r=
5595.62
−
8
∙
110.9625
∙
33.4125
√
(
186246.65
−
8
∙
110.9625²
)(
16881.23
−
8
∙
33.4125²
)
=+0,98196
Do istog rezultata dolazimo pomoću koeficijenta determinacije, izračunatog pomoću
elemenata analize varijanse:
r=
√
7665.853
7950.069
=0,98196
Regresijski koeficijent je pozitivnog predznaka(b=0,295575), pa se koeficijentu pridružuje
pozitivni predznak.Do istog rezultata se dolazi i na treći način:
R=b
σ
x
σ
y
=0,295575
√
87745.23875
/
8
7950.06879
/
8
=0,98196
Koeficijentom linearne korelacije mjeri se jakost i smjer statističke povezanosti dvije pojave
predstavljenih u obliku parova vrijednosti numeričkih varijabli.Koeficijent varira u intervalu
od -1 do +1.Utvrđivanje jakosti veze pomoću koeficijenta linearne korelacije kao deskriptivno
statističke veličine treba povezati s veličinom koeficijenta determinacije.Orjentaciono u tome
mogu poslužiti sljedeći odnosi:
Tabela br. Odnosi koeficijenata determinacije i korelacije
Koeficijent determinacije
Apsolutna vrijednost koeficij.
linearne korelacije
Tumačenje
r
2
|
r
|
0
0,00-0,25
0,25-0,64
0,64-1
1
0
0,00-0,50
0,50-0,80
0,80-1
1
Odsutnost korelacije
Slaba korelacija
Korelacija srednje jačine
Čvrsta korelacija
Potpuna korelacija
Na osnovu raspona vrijednosti koeficijenta zaključuje se da je linearna povezanost slabija što
je koeficijent bliži nuli.
Mjerenje stepena statističke veze opisanim koeficijentima korelacije odnosi se na pojave
predstavljene vrijednostima numeričkih varijabli.
Ispitivanje stepena veze između pojava datih u obliku
redosljedne(rang) promjenljive
nije
moguće na isti način kao i za ove date u obliku numeričkih nizova, jer varijable ranga nemaju
za to potrebna metrička svojstva.Korelacija se može mjeriti za dvije varijable ranga.Postoji
više različitih koeficijenata korelacije ranga, jedan od njih je
Spearmanov koeficijent.
Pri
74
analizi polazi se od parova vrijednosti varijabli ranga:
r(
x
i ;
) ;r(
y
i
) i=1,2.........,n .P
olazna
veličina za mjerenje korelacije varijabli ranga je razlika rangova:
d
i
=
r(
x
i ;
)
−
¿
r(
y
i
)
i=1,2,3....,n
pri čemu je
d
razlika vrijednosti rangova dvije
posmatrane varijable, a
n
broj različitih serija.
D
a bi se uklonio uticaj predznaka na veličinu
razlika, polazi se od kvadrata razlika.Koeficijen korelacije ranga Spearmana dat je izrazom:
r
s
=1-
6
∑
i
=
1
n
d
i
2
n
3
−
n
-1
≤ r
s
≤
1
Pri korištenju
Spearmanov koeficijent
, vrijednosti varijabli potrebno je rangirati i na takav
način svesti na zajedničku mjeru.Najjednostavniji način rangiranja je da se najmanjoj
vrijednosti svake varijable dodijeli rang 1,sljedeći po veličini rang 2 i tako sve do posljednje
kojoj se dodjeljuje max. rang.
Spearmanov koeficijent
mjeri korelaciju dviju varijabli ranga.U praksi se pokazuje potreba da
se izrazi korelacija skupa od tri i više varijabli ranga.Pri tome se koristi
Kendallov koeficijent
,
zasniva se na koeficijentu višestruke korelacije ranga, čija se vrijednost kreće od 0-1, što je
bliža 1 višestruka korelaciona veza je čvršća.
2.4.2.Koeficijent multiple linearne korelacije, korelacijska matrica
Koeficijent multiple linearne korelacije
mjeri se jakost veze između zavisne varijable Y i više
nezavisnih varijabli.On je drugi korjen iz koeficijenta determinacije:
R
y ,
1.
⋯
K
=
√
∑
i
=
1
(
n
( ^
y
i
−
y
)
²
∑
i
=
1
n
(
y
i
−
y
)
²
0
≤ R
y ,
1.
⋯
K
≤
1
Koeficijent će biti bliže 1 što je veći dio protumačenog zbira kvadrata u ukupnom zbiru,
odnosno što su manje razlike između stvarnih vrijednosti zavisne varijable i regresijskih
vrijednosti.
Osim koeficijenta multiple i parcijalne korelacije u cjelovitoj analizi višedimenzionalnih
modela primjenjuje se i koeficijent jednostavne linearne korelacije.Koeficijenti se prikazuju u
uređenoj šemi.Nakon što se posmatranjem međusobnog odnosa svih parova dvije varijable
utvrdi njihova međusobna korelacija, izrađuje se
matrica korelacije.
Redovi i kolone matrice
predstavljaju posmatrane varijable, a podatak na presjeku određenog reda i kolone predstavlja
koeficijent korelacije između varijabli u odgovarajućem redu i koloni.Vrijednost koeficijenta
neće se promjeniti ako se zamijene mjesta varijabli.Iz tog proizilazi da prvi red i prva kolona
korelacijske matrice imaju iste elemente:
r
yj
=
r
jy
j=1,2
⋯
K
.
Ostali elementi korelacijske

76
Frekvencije vremenskog niza izražene su u različitim mjernim jedinicama.Neke su date
vrijednosno tj. u novčanim jedinicama.Vrijednost novca mijenja se s vremenom, pa tako iste
količine u različitim vremenima imaju različite nominalne vrijednosti.
3.1.1.Analiza vremenskih nizova:zadaci i pristupi
Analiza vremenskih nizova treba omogućiti donošenje brojčanih sudova o obilježjima razvoja
pojava u vremenu.Zadaci anlize su:
1.deskripcija razvoja pkojava u vremenu
opis se vrši različitim metodama.Među njima su
grafički prikazi jednostavni brojčani pokazatelji(relativni brojevi-sve vrste numeričkih
vrijednosti , do kojih se dolazi mjerenjem jedne veličine drugom veličinom zovu se
relativni
brojevi)
Analitički se razvoj izražava modelima vremenskih pojava.
2.
objašnjenje varijacije pojave u vremenu
pomoću drugih pojava.To se obavlja pomoću
regresijske i korelacijske analize.
3.predviđanje razvoja pojave
,predviđanje je donošenje sudova o budućen nivou
pojave.Predviđa se pomoću jednostavnih rezultata, kao što su pokazatelji dinamike ili modela
vremenskih pojava.
4.kontrola procesa
, proizvodni procesi se odvijaju u vremenu.Praćenje karakteristike procesa
pojavljuju se kao zapisi generirani pomoću analognog računala.Zapisi su u vremenu te
predstavljaju vremensku seriju prikazanu na kontrolnoj karti.
Predmet analize
može biti jedna pojava(jedan vremenski niz) ili više njih, zavisi od datih
slučajeva.Metode analize mogu biti iz deskriptivne statistike.
Statistička analiza vremenskih pojava provodi se u
vremenskoj domeni
i u
domeni frekvencija.
U analizi pojave u vremenskoj domeni pomoću modela postoje dva pristupa:
Prvi
sastoji se u utvrđivanju analitičkih izraza kojima se statistički opisuje razvoj nivoa pojave
u vremenui to pomoću neke funkcije vremena.
Drugi
nastoji da se statistički opiše dinamička struktura pojave , a ne kretanje nivoa u
vremenu.Ovdje je riječ o mjerenju stepena i smjera korelacije članova iste serije razmaknutih
jedno razdoblje, dva ili više njih , kao i analitičkom istraživanju takve međuzavisnosti.
Statistička analiza kretanja nivoa pojave u vremenu provodi se polazeći od
klasične podjele
serije u komponente.
Vremenske pojave se mogu predstaviti pomoću manjeg broja tipičnih
komponenti.To su:
trend;ciklična;sezonska i slučajna komponenta.
Trend
komponenta vremenske serije predstavlja osnovnu dugoročnu(sekundarnu)tendenciju
njezina razvoja u vremenu.Predstavlja se funkcijama vremena.Ako se pojava od razdoblja do
razdoblja mijenja za približno jednak iznos, njezin je trend linearan.Trend se može uočiti
77
samo ako se raspolaže s dovoljno dugim vremenskim nizom.U praksi se uzima niz od
najmanje deset godišnjih frekvencija.
Ciklične
promjene pojave prisutne su ako se pojava obnavlja na približno jednak način s
periodom od dvije i više godina.Privredni ciklus pokazuju strukturne promjene, koje su
posljedica privrednog razvoja.
Sezonske
pojave mogu se obnavljati u periodu od jedne godine.One se javljaju samo ako se
raspolaže serijom mjesečnih ili kvartalnih podataka.
Trend komponenta, ciklična i sezonska zovu se sistematskim , determinističkim
komponentama jer predstavljaju kovarijacije pojave koje se daju predstaviti nekom funkcijom
vremena.Slučajna komponenta je nesistematska.
Vremenska serija ne mora sadržavati sve navedene komponente i u pravilu ih i ne sadrži.
3.1.2.Grafičko prikazivanje vremenskih nizova
Postoji nekoliko vrsta grafikona pomoću kojih se mogu prikazivati statističke vremenske
serije , a u primjeni su najčešće linijski grafikoni, odnosno površinski grafikoni.
Trenutni nizovi se prikazuju linijskim grafikonom, dok se intervalni vremenski nizovi mogu
prikazivati i površinskim grafikonom.Grafikoni nam omogućavaju prikaz prvih impresija o
nekoj pojavi i pri tome nam pomažu pri izboru matematičko-statističke metode.
Intervalni niz prikazuje se površinskim i linijskim grafikonom.Na „Y“ ordinatu nanosimo
aritmetičko mjerilo za frekvencije, i ono uvijek počinje od nule a na „X“ osi nalazi se
aritmetičko mjerilo za vrijeme.Ako intervali promatranja nisu jednaki , potrebno je izvršiti
korekciju frekvencija.Pri konstrukciji površinskog grafikona upotrebljavaju se
pravougaonici.Linijski grafikon intervalnog vremenskog niza nastaje spajanjem tačaka čije su
koordinate date sredinama vremenskih razdoblja i frekvencijama.
1980
1981
1982
1983
1984
1985
0
5
10
15
20
25
30
35
Broj stanova u
000

79
3.2. Brojčana analiza vremenskih nizova
Uz grafičku analizu po pravilu moramo provesti i brojčanu analizu.Grafičko prikazivanje
omogućava uvid u osnovnu sliku o dinamici jedne pojave ili više njih.Kod brojčane analize
počet će se sa jednostavnim pokazateljem dinamike(relativni brojevi).
Sve vrste numeričkih vrijednosti , do kojih se dolazi mjerenjem jedne veličine drugom
veličinom , zovu se
relativni brojevi.
Svi relativni brojevi računaju se na isti način:
Broj koji
želimo upoređivati stavljamo u odnos prema broju s kojim se upoređuje.
Relativni broj=
veličina koju upoređujemo
veličina s kojom upoređujemo
3.2.1.Osnovni numerički pokazatelji dinamike
Među osnovne pokazatelje razvoja pojave u vremenu ubrajaju se:pojedinačne razlike
frekvencija niza u uzastopnim razdobljima ili u odnosu na neko fiksno razdoblje u apsolutnom
i relativnom isnosu:
Ako se sa
{
y
t
}
, t=1,2,3
⋯
, n
označe frekvencije vremenskog niza s jednakim intervalima
posmatranja(jednako udaljenim vremenskim tačkama), pojedinačne promjene u apsolutnom
iznosu u uzastopnim razdobljima date su
prvim diferencijama
serija(
apsolutna razlika nivoa):
ΔY
t
=
Y
t
-
Y
t
−
1
;
t=2,3,....., n
Promjene su izražene u istim mjernim jedinicama kao i frekvencije.Izraz pokazuje za koliko
se apsolutno promjenio nivo pojave u vremenu
t
prema vremenu
t-1.
Za seriju od N članova može se odrediti N-1 apsolutnih razlika, s obzirom da se do apsolutnih
razlika dolazi odbijanjem jednog broja od drugog njihov predznak može biti pozitivan ili
negativan.Predznak ukazuje na smjer kretanja promjene..Ukoliko se mjeri razlika neke pojave
u odnosu na bazno razdoblje, to se može izraziti na sljedeći način:
ΔY
t
=
Y
t
-
Y
b
;
t=1,2,3....N ;
Y
b
=
Y
t
−
1
Pri poređenju dinamike različitih pojava, nemoguće je uporediti diferencije različitih jedinica
mjere.Kao posljedicu imamo mjerenje promjena relativnim brojevima.
80
Pojedinačne relativne promjene mjere se
koeficijentom dinamike:
K
t
=
ΔY
t
Y
t
−
1
odnosno
K
t
=
Y
t
−
Y
t
−
1
Y
t
−
1
=
Y
t
Y
t
−
1
-1
pomnožimo li koeficijent dinamike sa 100, dobijemo
prvu relativnu diferenciju ili pojedinačnu stopu promjene:
S
t
=
K
t
∙
100; s obzirom da je
verižni index
v
t
=
Y
t
Y
t
−
1
; pojedinačna stopa promjene može se pisati
i:
S
t
=
v
t
– 100
Nivo pojave u različitim vremenskim razdobljima može da se uporedi i s nivoom pojave u
nekom fiksnom periodu:tada se relativna promjena računa na sljedeći način:
S
t
=
Y
t
−
Y
b
Y
b
100 =
[
Y
t
Y
b
−
1
]
∙
100
I
t
=
Y
t
Y
b
∙
100
S
t
=
I
t
−
100
Nivo pojave
Apsolutna
promjena
Verižni indeksi
Pojedinačna stopa
promjene
Y
1
Y
2
ΔY
2
=
Y
2
-
Y
1
V
2
=
Y
2
Y
1
∙
100
S
2
=
I
2
−
100
Y
3
ΔY
3
=
Y
3
-
Y
2
V
3
=
Y
3
Y
2
∙
100
S
3
=
I
3
−
100
Y
4
ΔY
4
=
Y
4
-
Y
3
V
4
=
Y
4
Y
3
∙
100
S
4
=
I
4
−
100
Primjer 1:Proizvodnja pšenice u tonama u individualnim domaćinstvima opštine A.Izračunaj
pokazatelje dinamike za podatke iz sljedeće tabele:

82
U 1993. godini proizvodnja pšenice u individualnom sektoru opštine A bila je 2337 tona
manja od proizvodnje u 1992. godini ili za 21,3%.U 1995.godini proizvedeno je 1217 tona
više nego u 1994. Godini ili za 14,5% i tako redom.Posmatrajući predznake pojedinačnih
stopa promjena mogu se primjetiti godine smanjene vrijednosti proizvodnje, kao i godine
porasta proizvodnje u odnosu na prethodne godine, dok vrijednost stope govori o intenzitetu
tih promjena.
3.2.2. Srednje vrijednosti vremenskih serija
Za vremenski niz od n članova ima (n-1) vrijednosti apsolutnih promjena(prvih diferencija),
ponekad se izračunava
prosječna
vrijednost uzastopnih apsolutnih promjena(
prosječna prva
diferencija):
Δ
Y
=
∑
t
=
2
N
ΔY
t
N
−
1
=
(
Y
2
−
Y
1
)
+
(
Y
3
−
Y
1
)
+
…
..
(
Y
N
−
Y
N
−
1
)
N
−
1
Δ
Y
=
Y
N
−
Y
1
N
−
1
Primjer 2: Koristeći prethodni primjer izračunati prosječnu vrijednost uzastopnih apsolutnih
promjena.
Δ
Y
=
Y
N
−
Y
1
N
−
1
=
7566
−
10990
9
=
−
¿
380,4
Prosječna vrijednost prve diferencije pokazuje da prizvodnja pšenice u opštini A u
uzastopnim razdobljima smanjivao u prosjeku za 380,4 tone.
3.2.3. Relativni brojevi dinamike-indeksi
Upoređivanje dva ili više stanja jedne te iste pojave ili skupine pojava na različitim mjestima,
ukazuje na dinamiku promjena pojave ili skupine pojava u prostoru.U deskriptivnostatističkoj
analizi vremenske serije veoma se često upotrebljavaju relativni brojevi, koji se nazivaju
indeksnim brojevima.
Indeksi su relativni brojevi koji pokazuju odnos stanja jedne te iste pojave ili skupine pojava
na različitim mjestima ili u različitim vremenskim razdobljima.
83
Ako indeksima pratimo dinamiku jedne pojave oni se zovu
individualnim indeksima,
a oni
koji pokazuju odnose stanja heterogene grupe pojava nazivaju se
skupni indeksi.
Frekvencije jedne atributivne ili geografske statističke serije označimo sa:
X
1
;
X
2
...
X
n
, prije
računanja indeksa potrebno je jedan od članova serije, odabrati kao baznu.Uzme li se veličina
X
b
za baznu, matematički izraz za izračunavanje indeksa ima oblik:
I
i
=
X
i
X
b
∙
100
;
i=1,2,3,....N
izračunavanje indeksa moguće je uz uslov:
X
i
>
0
i
X
b
>
0
Za indekse vrijedi sljedeća relacija:
1.
X
i
>
X
b
→ I
i
>
100
Prva relacija ima značenje da je pojava u
i
-tom modalitetu obilježja veča za (I-100)%
nego u baznom modalitetu istog obilježja.
2.
X
i
<
X
b
→ I
i
<
100
Druga relacija ima značenje da je pojava u
i
-tom modalitetu obilježja manja za (100-I)
%nego u baznom modalitetu istog obilježja.
3.
X
i
=
X
b
→ I
i
=
100
Treća relacija ukazuje na jednakost pojave u
i
-tom i baznom modalitetu istog obilježja.
Indeksi
I
, su indeksi sa stalnom bazom.
3.2.4. Indeksi u statističkoj analizi vremenskih serija
Statistička analiza vremenskih serija predpostavlja međusobnu uporedivost frekvencija
vremenske serije, pri čemu prostorna i pojmovna definicija pojave mora u svim posmatranim
intervalima ili trenucima ostati nepromjenjena.Intervali posmatranja mora da budu
jednaki.Kod trenutnih vremenskih serija razmaci između vremenskih tačaka ne mora da budu
ekvidistantni.Trenutne i intervalne vremenske serije mogu da se analiziraju indeksnim
brojevima.Indeksi imaju funkciju da prate dinamiku jedne pojave ili grupe pojava u vremenu ,

85
Y
2
Y
1
∙
100
Y
3
y
2
∙
100
Y
n
Y
n
−
1
∙
100
Matematički izraz za računanje lančanih ili verižnih individualnih indeksa:
V=
Y
t
Y
t
−
1
100
; t=1,2,3,.......,N
Verižni indeks je uvijek pozitivna veličina.Za njih se upotrebljavaju sljedeće relacije:
1.
Y
t
>
Y
t
−
1
→V
t
>
100
2.
Y
t
<
Y
t
−
1
→V
t
<
100
3.
Y
t
=
Y
t
−
1
→V
t
=
100
Verižni indeks
V
t
pokazuje koliko jedinica pojave u vremenu t dolazi na svakih 100 jedinica
pojave u vremenu t-1.Indeksi mogu da posluže:
-kao pokazatelji dinamike jedne pojave
-za upoređivanje dinamike dvije ili više raznorodnih pojava.
Primjer 1:
Izračunati i uporediti verižne indekse za nekoliko osnovnih podataka o razvoju
kulture i umjetnosti na području države.
Godina
Profesionalna pozorišta
Pretplatnici u 000
Broj
Posjeti.u 000
Radija
TV
1992
1993
1994
1995
1996
1997
1998
1999
2000
36
36
38
37
40
41
42
41
41
1411
1337
1053
998
778
905
1021
916
1065
1786
1738
1412
1469
1420
1284
1185
1300
1175
1624
1582
2376
2676
2664
2692
2685
2163
2257
86
Tabela verižnih indeksa izračunatih iz prethodne tabele:
Godina
Profesionalna pozorišta
Pretplatnici u 000
Broj
Posjeti.u 000
Radija
TV
1992
1993
1994
1995
1996
1997
1998
1999
2000
-
100
106
97
108
102
102
98
100
-
95
79
95
78
116
113
90
116
-
97
80
104
97
90
92
110
90
-
97
150
112
99
101
99
81
104
Serija indeksa na stalnoj bazi je upravo proporcionalna seriji originalnih podataka iz kojih je
izračunata.Iz ovog možemo zaključiti da se serija indeksa na stalnoj bazi može preračunati u
seriju verižnih indeksa .Indeksi na stalnoj bazi:
I
1
;
I
2
........
I
N
¿
¿
Lančani indeksi predstavljeni su sljedećim izrazom:
I
2
I
1
∙
100 ;
I
3
I
2
∙
100
;
I
n
I
n
−
1
∙
100
Matematički izraz za preračunavanje indeksa na stalnoj bazi u seriji lančanih indeksa glasi:
I
t
=
V
t
I
t
−
1
∙
1
100
;
t=1,2,3......,N
Ako serija indeksa na stalnoj bazi može da se prepačuna u seriju verižnih indeksa, onda je
moguće i obrnuto.
V
t
=
I
t
I
t
−
1
100
t=1,2,3....n

88
-skupnih indeksa količina
-skupnih indeksa vrijednosti
-indeksa troškova života
3.2.4.3.1.Skupni indeksi cijena
Indeksima cijena mjeri se intenzitet promjena cijena tekućeg razdoblja u odnosu na bazno
rardoblje.Bazno razdoblje je bilo koje u vremenskom nizu.Označit će se sa
t
0
,
Individualni indeks cijena označava se :
I
i
(
p
)
=
p
¿
p
i
0
;
i=1,2,....k ; t=1,2....n
Gdje je
p
¿
cijena
i-
to npr. proizvoda u vremenu
t,
a
p
i
0
cijena
i-
tog proizvoda u baznom
razdoblju.Navedeni indeksi cijena tumače se kao indeksi na stalnoj bazi.Ako se odredi
jednostavna aritmetička sredina indeksa cijena, doći će se do pokazatelja promjena cijena za
grupu.
Jednostavna sredina indeksa cijena je:
I
(
p
)
=
∑
i
=
1
k
p
¿
∑
i
=
1
k
pi
0
∙
100
Skupni indeks cijena može se definisati kao nevagani indeks odnosa zbira tekučeg i baznog
razdoblja pomnožen sa 100.U njemu svaka cijena ima jednak ponder, što predstavlja jedan
nedostatak.Zbog toga se umjesto nevaganog primjenjuje vagani skupni indeks.
Kako se varijacije cijena i količina posmatraju za
n
razdoblja , prije računanja indeksa
potrebno je odrediti pomoću kojih će se količina provesti postupak ponderisanja.
Ako su ponderi cijena određuju pomoću količina baznog razdoblja doći će se do Laspeyrov
indeks cijena
P
0
t
(
q
0
)
=
∑
i
=
1
k
p
¿
q
i
0
∑
i
=
1
k
p
i
0
q
i
0
∙
100
;
t=1,2,....,n
Iz navedenog izraza se vidi da se ponderisanje cijena provodi nepromjenjenim količinama
baznog razdoblja.Skupni indeks cijena pokazuje prosječnu promjenu cijena grupe pojava u
vremenu
t
u odnosu na bazno razdoblje.Laspeyrov skupni indeks cijena naziva se još i skupni
indeks cijena postojanog sistema ili postojane strukture prometa.
89
Ako su ponderi cijena određuju pomoću količina tekućeg razdoblja doći će se do Paascheov
indeks cijena.
P
0
t
(
q
t
)
=
∑
i
=
1
k
p
¿
q
¿
∑
i
=
1
k
p
i
0
q
¿
∙
100
;
t=1,2,....,n
Ponderi indeksa cijena se revidiraju za svaki period za koji se računa taj indeks.Ovaj indeks se
zove i skupni indeks cijena nepostojanog sastava, nepostojane strukture prometa ili
proizvodnje.Paasche uzima za pondere uvijek količine izvještajnog razdoblja tako da
promjena, u tom razdoblju , dovodi do promjene pondera.
Skupni indeksi cijena po
Laspeyrov indeksu cijena i Paascheova indeksa cijena se
razlikuju.
Razlika je nastala usljed različitih ponderacionih sistema jednog i drugog indeksa tj.
razlika u sadržaju indeksa.Oba ova indeksa mjere promjene cijena.
Specifičnu sintezu ta dva indeksa čini
Fisherov idealni indeks cijena.
To je geometrijska
sredina Laspeyrov indeksa cijena i Paascheova indeksa cijena.On sadrži svojstav oba
indeksa.Njegovo tumačenje je komplikovano.
Primjer1
:
Date su cijene tri najčešće namirnice koje se troše na području Beograda za 2002 i
2007. Godinu
Namirnice
Količinska
jedinica
Prosječna cijena
Potrošnja po stanov/mj
2002
(
p
i
0
)
2007 (
p
¿
)
2002(
q
i
0
)
2007(
q
¿
)
Mlijeko
Hljeb
Jaja
Litar
Kg
tucet
4,7
4,9
9,3
5,6
8,9
10,1
5,7
9,0
0,9
7,3
8,6
1,5
Izračunajte Laspeyresov skupni indeks za 2007. Godinu za tri namirnice uzevši da je 2002.
Godina bazna.
Namirnice
Laspeyresov indeks
Paascheova indeksa
p
¿
q
i
0
p
i
0
q
i
0
p
i t
q
¿
p
i
0
q
¿

91
Q
0
t
(
p
0
)
=
∑
i
=
1
k
q
¿
p
i
0
∑
i
=
1
k
q
i
0
p
i
0
∙
10 0
;
t=1,2......n
Alternativno taj se indeks može pisati u obliku vagane aritmetička sredina individualnih
indeksa količina:
Q
0
t
(
p
0
)
=
∑
i
=
¿¿
k
q
¿
qi
0
W
i
0
∑
i
=
1
k
W
i
0
100; t=1,2......,n
Q
0
t
označava skupni indeks količina razdoblja t , tok 0 je oznaka za bazno razdoblje
t
0
.U
zagradi
p
0
nam govori da se ponderisanje količina vrši polazeći od cijena baznog razdoblja.
W
i
0
su ponderi , ako su ponderi vrijednosti baznog razdoblja onda imamo izraz:
Q
0
t
(
p
0
)
=
∑
i
=
¿¿
k
q
¿
qi
0
p
i
0
∑
i
=
1
k
q
i
0
p
i
0
100
; t=1,2.....,n
Ako je skupni indeks količina izračunat polazeći od stalnih cijena tekućeg razdoblja dobit će
se
Paascheov skupni indeks količina
:
Q
0
t
(
p
t
)
=
∑
i
=
1
k
q
¿
p
¿
∑
i
=
1
k
q
i
0
p
¿
∙
100
;
t=1,2......,n
Alternativno taj se index može pisati u obliku vagane aritmetička sredina individualnih
indeksa količina:
Q
0
t
(
p
t
)
=
∑
i
=
¿¿
k
q
¿
qi
0
W
¿
∑
i
=
1
k
W
¿
100
; t=1,2...., n
Ako su ponderi vrijednosti količina obračunate po cijenama tekućeg razdoblja, indeks postaje:
92
Q
0
t
(
p
0
)
=
∑
i
=
¿¿
k
q
¿
qi
0
q
i
0
p
¿
∑
i
=
1
k
q
i
0
p
¿
100
; t=1,2.....,n
Laspeyresov skupni indeks količina
pokazuje za koliko se u prosjeku relativno mijenja
vrijednost fizičkog obima heterogene grupe pojava usljed promjena količina pojedinih pojava
uz nepromjenjene cijene baznog razdoblja.
Paascheov skupni indeks količina
izražava
prosječnu relativnu promjenu količina grupe pojava zbog promjena količina pojedinih pojava
u grupi, polazeći od strukture vrijednosti obračunate po cijenama tekućeg razdoblja.Ni u
jednom indeksu ne dolazi do izražaja varijabilnost
cijena , jer su one stalne.
Primjer 1:
Data su četiri najčešće proizvedena proizvoda u poljoprivrednom domaćinstvu za
2000 i 2001. Godinu.
Proizvod
Jed. mjere
Količina
Cijena
2000
2001
2000
2001
Mlijeko
Jaja
Puter
Meso
Lit.
Kom
Kg
kg
30 000
4 000
500
1 640
36 000
5 200
480
1 200
14
6
233
534
18
7
350
620
Izračunati skupne indekse količina
Proizvod
q
i
0
p
i
0
q
i
0
p
i
0
q
¿
p
¿
q
¿
p
i
0
q
¿
p
¿
Mlijeko
Jaja
Puter
Meso
30 000
4 000
500
1 640
14
6
233
534
420 000
24 000
116 500
875 760
36 000
5 200
480
1 200
18
7
350
620
504 000
31 200
111 840
640 800
648 000
36 400
168 000
744 000
Ukupno
-
-
1436260
-
-
1287840
1596400
Laspeyresov skupni indeks količina:
Q
0
t
(
p
0
)
=
∑
i
=
1
k
q
¿
p
i
0
∑
i
=
1
k
q
i
0
p
i
0
∙
100

94
V
0
t
=
∑
i
=
1
k
p
¿
q
¿
∑
i
=
1
k
p
i
0
q
i
0
∙
100
Skupni indeks vrijednosti , količina i cijena su u međusobnoj vezi.Vrijednost je produkt
količine i cijene.Indeks vrijednosti je produkt indeksa količina i indeksa cijena.
Primjer 1.
Promatraju se prosječne prodajne cijene (PDV uračunat) i prodane količine četiri
različite vrste proizvoda u trgovini tokom oktobra i novembra 2008. g. Podaci su navedeni u
donjoj tabeli.
Proizvod
Prosj.prodajna
cijena u oktobru
2008. God
(KM/kg)
Prosj.količina
prodatih proiz.u
oktobru
2008.god.
(kg)
Prosj.prodajna
cijena
unovembru
2008. God
(KM/kg)
Prosj.količina
prodatih proiz.u
oktobru
2008.god.
(kg)
Brašno
Kafa
So
Šećer
0,95
19,80
0,80
2,20
190
50
170
290
1,10
19,30
0,75
2,30
200
54
150
180
V
0
t
=
∑
i
=
1
k
p
¿
q
¿
∑
i
=
1
k
p
i
0
q
i
0
∙
100
=
(
1,10
∙
200
+
19,30
∙
54
+
0,75
∙
150
+
2,30
∙
180
0,95
∙
190
+
19,80
∙
50
+
0,80
∙
170
+
2,20
∙
290
=
1788,70
1944,50
∙
100
=
¿
91,99
Zaključujemo da je ukupna vrijednost posmatrane skupine robâ u novembru 2008. bila za
približno8,01% manja nego u oktobru 2008.
Vrijednost izražena pomoću cijena tekućeg razdoblja naziva se
nominalnim
vrijednostima .
Ako cijene u vremenu nisu postojane, što je pravilo,sud stvarnog razvoja
pojave u vremenu nije moguć na osnovu vrijednosti izraženih u tekućim cijenama.Da bi
shvatili stvarnu dinamiku, treba odbaciti uticaj promjena cijena na vrijednost izražene
pojave.Taj se postupak naziva
deflacioniranje.
Provodi se djeljenjem nominalnih vrijednosti s
odgovarajućim indeksom cijena nemnoženim sa sto.Takav indeks se zove
deflacijskim
indeksom ili deflatorom
3.2.4.3.4.Indeks troškova života
Indeks troškova života je skupni indeks cijena i primjeljuje se u svojstvu deflatora.Tim
indeksom se deflacioniraju nominalne plate, ako se one podjele indeksom troškova života ,
nemnoženim sa sto, doći će se do veličine realnih plata.Realne plate govore nam o kupovnoj
moći novca, koja je bitna u doba inflacije.
95
Ponekad se vrijednosti za niz razdoblja daju u stalnim cijenama, cijenama jednog vremenskog
razdoblja.Takve vrijednosti zbog niza razloga treba uskladiti s nastalim promjenama
cijena.Postupak usklađivanja vrijednosti a nastalim promjenama cijena naziva se
revalorizacija.
I suprotna je od deflacije.Revalorizacija se provodi množenjem vrijednosti u
stalnim cijenama odgovarajućim indeksima cijena nemnoženim sa sto ili pomoću propisanih
koeficijenata.
3.3.Modeli vremenskih pojava
Modeli vremenskih pojava su analitički izraz njihova razvoja u vremenu.Izbor modela zavisi
od cilja analize i obilježjima vremenskog niza koji predstavlja datu pojavu.Zavisno od
karaktera faktora koji djeluju u vremenu na neku pojavu, kažemo da vremenske serije čine
sljedeće komponente:
1.
trend
ili osnovna tendencija kretanja neke pojave kroz vrijeme
2.
sezonske oscilacije
koje se pojavljuju unutar jedne godine
3.
slučajne komponente
koje čine slučajni, teško predvidivi događaji(rat,potres,novi zakon
itd).Slučajne tj. sve ostale komponente skreću pojavu od njene osnovne tendencije kretanja.
3.3.1.Trend
Trend je osnovna tendencija kretanja pojave kroz određeno vremensko razdoblje.Prvu
informaciju o kretanju pojave pruža grafički prikaz originalnih podataka.Raspored tačaka koje
predstavljaju veličinu pojave u pojedinim vremenskim periodima omogućuje lako utvrđivanje
smjera kretanja pojave.U statistici trend znači karakterističnu i zakonomjernu liniju kretanja
pojave u vremenu.Trend se ponekad zove i dinamička sredina vrijednosti, jer izražava
prosječno ili srednje stanje pojave u posmatranom periodu.Linija koja reprezentuje originalne
vrijednosti može biti prava ili kriva.Koju ćemo matematičku funkciju izabrati , zavisi od
ocjene vrste i oblika kretanja posmatrane pojave.Ona treba da bude odabrana tako da se
najbolje prilagođava originalnim podacima. Ako postoji dilema u izboru, treba izabrati onaj
trend čija je standardna devijacija manja.
Teoretski metod trenda može se primjeniti kad imamo formiranu vremensku
seriju.Najpogodnije su vremenske serije koje su date u jednogodišnjim vremenskim
intervalima i kada se posmatrana pojava razvija kao dugoročna.
Za utvrđivanje trenda postoje neparametarske i parametarske metode.Neparametarskim
metodama se utvrđuje samo približno osnovnu tendenciju kretanja pojave, one su dobre kao
prethodnica parametarskim metodama , koje treba da dovedu do linije koja će najbolje
reprezentovati originalne podatke.

97
1996/1997
1997/1998
1998/1999
1999/2000
2000/2001
1232
1090
1157
1279
943
Za izračunavanje parametara a i b potrebno je sljedeće:
Školska god.
Y
i
X
i
X
i
2
X
i
Y
i
1994/1995
1995/1996
1996/1997
1997/1998
1998/1999
1999/2000
2000/2001
1351
1496
1232
1090
1157
1279
943
0
1
2
3
4
5
6
0
1
4
9
16
25
36
0
1496
2464
3270
4628
6395
5658
Ukupno
8548
21
91
23911
Izračunavamo aritmetičku sredinu za vrijeme
X
i
X
=
∑
x
i
N
=
21
7
=3
Izračunavamo aritmetičku sredinu za prosječnu vrijednost posmatrane pojave
Y
i
Y
=
∑
y
i
N
=
8548
7
=1221,143
Izračunamo parametre a i b
b=
∑
i
=
1
n
X
i
y
i
−
N xy
∑
i
=
1
N
X
i
2
−
N x
²
=
23511
−
7
x
3
x
1221,14
91
−
7
x
9
b=-61,893
a=
y
-b
x
=
1221,143 + 61,893x3
a=1406,822
pošto imamo sve potrebne veličine možemo da napišemo jednačinu linearnog trenda:
y
t
=1406,822-61,893
x
i
Početak: 30.09.1994
98
Oznaka za Y:1 student
Oznaka za X: 1 godina
i ovo tumačimo:prema trendu 30.09 1994. godine na fakultetu bilo je upisano 1407 studenata
s prosječnim godišnjim smanjenjem od 62 studenta.
Parametar „a“ je vrijednost trenda na početku razdoblja, jer je tu vrijednost x=0.Parametar „b“
označava pad ili porast pojave, zavisno od predznaka.
Izračunavanje trend vrijednosti za ostale godine serije :potrebno je na vrijednost parementa a
(1406,822) dodavati vrijednost parametra b(-61,893).
Trend bolje reprezentuje originalne vrijednosti vremenske serije što su razlike originalnih i
trend vrijednosti manje.
Škol. godina
Y
i
Y
ci
Y
i
−
Y
ci
(
Y
i
−
Y
ci
)²
1994/1995
1995/1996
1996/1997
1997/1998
1998/1999
1999/2000
2000/2001
1351
1496
1232
1090
1157
1279
943
1406,822
1344,929
1283,036
1221,143
1159,250
1097,357
1035,464
-55,82
15,07
-51,04
-131,14
-2,25
181,64
92,46
3116,10
82822,45
2604,67
17198,49
5,06
32994,18
8504,60
Ukupno
8548
8548,001
0
87290,55
Varijansa linearnog trenda:
σ
^
y
2
=
∑
(
Y
i
−^
y
t
)
²
N
=
87290,55
7
=124770,08
Standardna devijacija:
σ
^
y
=
√
σ
y
2
=
√
12470,08
=111,67
Koeficijent varijacije linearnog trenda:
V
^
y
=
σ
y
y
100 =
111,67
1591,857
100 =9,14%
Prosječno odstupanje originalnih vrijednosti od trend vrijednosti iznosi 111,67 studenata.Što u
relativnom iznosu znači 9,14%, što znači da su odstupanja vrlo mala i da linearni trend dobro
reprezentuje originalne podatke.
3.3.1.2.Parabolični trend drugog stepena
Za primjenu modela linearnog trenda polazi se od predpostavke da se pojava mijenja u
uzastopnim razdobljima za približno isti apsolutni iznos.Ako su promjene promjena po
jedinici vremena približno jednake, umjesto linearnog primjenit će se parabolični trend.

100
2001
53
godina
y
i
x
i
x
i
2
x
i
4
y
i
x
i
x
i
2
y
i
1995
1996
1997
1998
1999
2000
2001
53
46
79
96
88
62
53
-3
-2
-1
0
1
2
3
9
4
1
0
1
4
9
81
16
1
0
1
16
81
-159
-92
-79
0
88
124
159
477
184
79
0
88
248
477
ukupno
477
0
28
196
41
1553
Broj posjetilaca iz Njemačke jedno vrijeme je rastao, a zati je padao.To nas je opredjelilo za
parabolični trend.
Računamo parametre „a“,“b“,i „c“
a=
∑
i
=
1
N
x
i
4
∑
i
=
1
N
y
i
−
¿
∑
i
=
1
N
x
i
2
∑
i
=
1
N
x
i
2
y
i
N
∑
i
=
1
N
x
i
4
−
∑
i
=
1
N
x
i
2
∑
i
=
1
N
x
i
2
¿
=
196
(
477
)−
28
(
1553
)
7
(
196
)−
28
(
28
)
=85,05
b
=
∑
i
=
1
N
x
i
y
i
∑
i
=
1
N
x
i
2
=
41
28
=1,46
c=
∑
i
=
1
N
x
i
2
y
i
−
∑
i
=
1
N
x
i
2
∑
i
=
1
N
y
i
N
∑
i
=
1
N
x
i
4
−
∑
i
=
1
N
x
i
2
∑
i
=
1
N
x
i
2
=
7
(
1553
)−
28
(
477
)
588
=-4,23; zbog predznaka parametra
„c“ otvor parabole će biti okrenut prema dole.Jednačina trenda je:
Y
t
=85,05+1,46
x
i
-4,23
x
i
2
Početak:30.06.1998. godine
Oznaka x: 1 posjetilac iz Njemačke
Oznaka y:1 godina
Godina
y
i
x
i
1,46
x
i
x
i
2
−
4,23
x
i
2
Y
ci
101
1995
1996
1997
1998
1999
2000
2001
53
46
79
96
88
62
53
-3
-2
-1
0
1
2
3
-4,38
-2,92
-1,46
0
1,46
2,92
4,38
9
4
1
0
1
4
9
-38,07
-16,92
-4,23
0
-4,23
-16,92
-38,07
42,60
65,21
79,36
85,05
82,28
71,05
51,36
Da bi provjerili reprezentativnost izračunatog paraboličnog trenda računamo njegovu
standardnu devijaciju i koeficijent varijacije.
godina
y
i
Y
t
y
i
−
Y
t
(
y
i
−
Y
t
)
²
1995
1996
1997
1998
1999
2000
2001
53
46
79
96
88
62
53
42,60
65,21
79,36
85,05
82,28
71,05
51,36
10,4
-19,2
-0,4
11,0
5,7
-9,1
1,6
108,16
368,64
0,16
121,00
32,49
82,81
2,56
ukupno
477
477
0
715,82
Varijansa paraboličnog trenda:
σ
^
y
2
y
=
∑
i
=
1
N
(
y
i
−
y
t
)
²
N
=
715,82
7
=102,26
Standardna devijacija:
σ
^
y
=
√
σ
y
2
=
√
102,26
=10,11 turista
Koeficijent varijacije:
V
^
y
=
σ
y
Y
100 =
10,11
68,14
100 =14,84
Prosječno odstupanje originalnih vrijednosti serije turista iz Njemačke od paraboličnog trenda
je 10,11 turista ili 14,84% , i smatra se tolerantnim odsupanjem, tj . da parabolični trend dobro
reprezentuje kretanje pojave u posmatranom intervalu.
3.3.1.3.Eksponencijalni trend
Eksponencijalni trend spada u grupu krivolinijskih trendova.Koristi se kod pojava koje rastu
ili padaju približno istom uzastopnom stopom promjene.To su promjene koje , prikazane
grafički, pokazuju prvo slabi porast ili pad , a zatim strmije.Kod modela jednostavnog
eksponencijalnog trenda funkcija vremena je predstavljena eksponencijalnom funkcijom.

103
godina
log
y
t
log
^
y
t
^
y
❑
1993
1994
1995
1996
1997
1998
1999
2000
2001
0,079189
0,255273
0,310211
0,602060
0,662758
0,681241
0,832509
0,929419
1,100371
0
,140937
0,259120
0,377303
0,495486
0,613668
0,731858
0,850035
0,968218
1,086401
1,4
1,8
2,4
3,1
4,1
5,4
7,1
9,3
12,3
ukupno
5,533023
5,523021
46,9
Za računanje staandardne devijacije i koeficijenta varijacije:
Type equation here .
godina
y
t
^
y
t
Y
t
−^
y
t
(
Y
t
−^
y
t
)
²
1993
1994
1995
1996
1997
1998
1999
2000
2001
1,2
1,8
2,4
4,0
4,6
4,8
6,8
8,5
12,6
1,4
1,8
2,4
3,1
4,1
5,4
7,1
9,3
12,3
-0,02
0
0
0,9
0,5
-0,6
-0,3
-0,8
0,3
0,04
0
0
0,81
0,25
0,36
0,09
0,64
0,09
ukupno
46,7
46,9
2,28
Standardna devijacija:
σ
^
y
=
√
σ
^
y
2
=
√
∑
i
=
0
N
(
Y
t
−^
y
t
)
²
N
=0,5
Koeficijent varijacije:
V
^
y
=
σ
y
y
=9,63%
Relativno prosječno odstupanje originalnih podataka od vrijednosti eksponencijalnog trenda
je 9,63%, te zaključujemo da eksponencijalni trend dobro reprezentuje dinamiku
kratkoročnog kretanja.Jednačina eksponencijalnog trenda glasi:
104
^
y
t
=4,1
∙
1,315
xi
Početak: 31.12.1997.
Oznaka Y:1 mil EUR
Oznaka X:1 godina
Parametar „a“ predstavlja vrijednost trenda u početku, dok parametar“b“ svojim predznakom
govori o smjeru promjene pojave, dok vrijednošću pokazuje intenzitet te promjene.
3.3.2.Sezonske oscilacije
Neke pojave pri svom kretanju kroz vrijeme u određenim dijelovima vremenskih perioda
pokazuju tendenciju pada ili porasta.Takve pojave zovemo periodičnim pojavama.Ako je taj
ciklus godinu dana , tj ako pojava pokazuje u određenim dijelovima godine pad a u drugim
rast govorimo o sezonskim pojavama(proizvodnja i ptrošnja velikog broja proizvoda je
sezonskog karaktera).Različiti faktori utiču na kretanje pojave tako da ona odstupa od svoje
osnovne tendencije utvrđene trendom.Treba utvrditi kolika su ta odstupanja , koji imaju
pravac.Polazimo od predpostavke da na pojavu utiču sljedeći faktori:
Y=TxSxR
T=trend
S=sezona
R=rezidualni uticaji
Pošto smo u prethodnom dijelu vidjeli kako se utvrđuje trend, moramo utvrditi sezonski i
rezidualni uticaj.S ekonomske strane sezonski uticaj ima nepovoljno djelovanje.Pri
utvrđivanju ovog uticaje trebamo se voditi sljedećim zadacima:
1.da li postoji sezonski karakter pojave
2.izmjeriti jačinu sezonskog uticaja, ako ima taj karakter
3.eliminisati uticaj sezone tj. kolika bi pojava bila kada sezonskog uticaja ne bi bilo.
Sezonski karakter pojave možemo vidjeti iz tabela ,a lakše je uočiti sa grafikona.
Primjer 1.
Data je proizvodnja piva u hl za pet godina, a za svaku godinu data je mjesečna
proizvodnja.
Mjesec
1997
1998
1999
2000
2001
1
2
3
4
36
39
88
153
37
75
105
212
45
54
111
170
64
99
139
205
80
92
144
287

106
5
6
7
8
9
10
11
12
402
432
534
502
315
215
179
82
272
272
272
272
272
272
272
272
148,8
158,8
193,3
184,6
115,8
79,9
65,8
30,2
ukupno
3264
3264
1200,00
Suma sezonskih indeksa iznosi 1200.Baza iznosi 100, a koristili smo 12 puta za dvanasest
mjeseci.Originalne podatke smo 12 puta stavljali u odnos prema bazi i dobili indekse od kojih
je neki iznad , a neki ispod 100.U januaru je proizvodnja piva zbog uticaja sezone manja za
70,6%, nego što bi bila da nema sezonskog uticaja.U junu je proizvodnja piva veća za 58,8%
nego što bi bila da nema sezonskog uticaja.
Kod pojava koje kroz vrijeme pokazuju zapaženu tendenciju pada ili porasta potrebno je pri
izračunavanju jačine sezonskih uticaja uzeti u obzir osnovnu tendenciju kretanja ili
trend.Treba izračunati mjesečne trend vrijednosti svih posmatranih godina, a zatim podatke
stavljati u odnos prema trend vrijednostima.Ako razvoj pojave dobro reprezentira linearni
trend, onda se kao baza izračunavanja sezonskih indeksa računaju vrijednosti linearnog
trenda.Mjesečne trend vrijednosti dobiju se tako da se izračunaju prvo vrijednosti linearnog
trenda i to godišnja jednačina linearnog trenda a zatim preračuna na mjesečnu jednačinu.
Sezonski indeks se izračunava:
I
s
=
y
t
^
y
t
I
s
=sezonski indeks ;
y
t
=originalna vrijednost;
^
y
t
=trend vrijednost
Na osnovu gore navedenog primjera proizvodnje piva , izračunaćemo godišnju jednačinu
linearnog trenda proizvodnje piva za rezdoblje 1997-2001. Godina.
godina
Y
i
X
i
X
i
2
Y
i
X
i
1997
1998
1999
2000
2001
1568
1847
2108
2553
3264
-2
-1
0
1
2
4
1
0
1
4
-3136
-1847
0
2553
6528
ukupno
11340
0
10
4098
b
=
∑
i
=
1
N
x
i
y
i
∑
i
=
1
N
x
i
2
=
4098
10
=409,8
a=
y
=2268
107
Jednačina linearnog trenda:
^
y
t
=2268+409,8
x
i
Početak: 30.06.1999
Oznaka Y:stotina hl piva
Oznaka X: 1 godina
Uzračunaćemo sve godišnje vrijednosti trenda i provjeriti njegovu reprezentativnost:
godina
Y
t
^
y
t
Y
t
−^
y
t
(
Y
t
−^
y
t
)²
1997
1998
1999
2000
20001
1568
1847
2108
2553
3264
1448,4
1858,2
2268,0
2677,8
3087,6
119,6
-11,2
-160,0
-124,8
176,4
14304,16
125,44
25600,00
15575,04
31116,96
ukupno
11340
11340
0
86721,60
Varijansa linearnog trenda:
σ
^
y
2
=17344,32 =
86721,60
5
Standardna devijacija:
σ
^
y
=131,7=
√
17344,32
Koeficijent varijacije linearnog trenda:
V
^
y
=5,81%=
131,7
2268
100
Koeficijent varijacije govori o dovoljno reprezentativnom linearnom trendu.Preračunaćemo
njegovu godišnju jednačinu na mjesečnu:
^
y
t
=
2268
12
+
409,8
144
x
i
^
y
t
=189+2,846
x
i
Početak:30.06.1999
Oznaka Y:100hl piva
Oznaka X:1 godina
Potrebne su nam mjesečne trend vrijednosti za sve mjesece svih godina.Zato ćemo početak
jednačine trenda premjestiti u prvi mjesec prve posmatrane godine tj. 15.01.1997 godine.Od
30.06.1999. godine do 15.01.1997. godine ima (-29,5)mjeseci, pa ćemo za „x“ uvrstiti-29,5.
^
y
t
=189+2,85x(-29,5)=104,92
^
y
t
=104,92+2,85
x
i

109
11
12
43,5
55,8
45,3
42,8
48,1
34,7
56,8
41,0
66,2
30,0
Razpolažemo sa podacima za 5 godina i za svaki mjesec imamo po 5 sezonskih
indeksa.Moramo imati samo jedan reprezentativni indeks, a za reprezentativni se uzima
medijana indeks.Medijana indeks za januar:
26,0 ; 26,6 ; 30,8 ; 33,1 ; 34,3 M=30,8
Medijana indeks za februar:
30,6 ; 36,2 ; 37,6 ; 47,1 ; 52,8 M=37,6, na isti način se određeuje medijana indeksa za
sve ostale mjesece.
Izračunavanjem medijana indeksa –srednje pozicione vrijednosti indeksa smo uklonili.Suma
grubih sezonskih indeksa mora biti 1200, ukoliko je različita , računamo korektor, s kojim
linearno množimo sve medijana indekse, kako bi njihovu sumu sveli na 1200.U našem sličaju
suma medijana indeksa je 1185.Korektor računamo : 1200/1185=1,027( sa korektorom
množimo sve medijana indeksa , da bi sumu sveli na 1200)
Mjesec
Medijana indeksi
Sezonski indeksi
1
2
3
4
5
6
7
8
9
10
11
12
30,8
37,6
65,2
134,8
141,5
155,1
190,6
153,0
109,9
77,4
48,1
41,0
31,2
38,1
66,0
136,5
143,3
157,1
193,0
154,9
111,3
78,4
48,6
41,5
Ukupno
1185,0
1200,00
Sezonski indeks za februar 38,1, znači da je proizvodnja piva u mjesecu februaru manja za
61,9%, zbog djelovanja sezonskog uticaja.
Vrijednosti koje su očišćene od sezonskih uticaja :
Mjesec
1997
1998
1999
2000
2001
1
2
3
4
5
6
7
8
9
10
11
115
102
133
112
124
141
153
123
126
119
119
119
197
159
155
149
146
131
151
160
195
156
144
142
168
125
158
173
188
214
193
196
199
205
260
211
223
202
219
219
188
181
213
275
156
241
218
210
281
275
277
324
283
274
368
110
12
183
176
171
236
198
Originalne podatke ćemo očistiti od sezonskih uticaja ukoliko originalne vrijednosti stavimo u
omjer sa sezonskim faktorom.
Ukoliko nema sezonskog uticaja, imali bi proizvodnju piva u januaru 1997 godine 115hl.U
ovom iznosu su uključeni trend i rezidualna komponenta.
Čistu rezidualnu komponentu ćemo dobiti djeljenjem vrijednosti očišćenih od sezonskog
uticaja s vrijednostima trenda.Pri tome rezidualne komponente u obliku indeksa su:
Mjesec
1997
1998
1999
2000
2001
1
2
3
4
5
6
7
8
9
10
11
12
109,6
94,9
120,2
98,7
106,6
118,3
125,4
98,5
98,6
91,1
89,2
134,3
85,5
138,8
109,8
105,0
99,0
95,2
83,9
98,7
120,4
118,3
93,1
103,2
83,1
80,6
93,8
68,7
85,5
92,2
98,7
110,7
99,9
99,9
99,9
99,9
98,9
123,6
98,9
103,2
92,3
98,8
97,7
82,6
92,5
91,3
116,3
98,8
105,9
98,5
88,1
83,9
111,0
107,4
107,8
123,8
103,6
102,5
136,2
72,5
U januaru 1997. godine proizvedeno je zbog rezidualnih faktora 9,6% više piva.
Utvrtili smo tri komponente, koje multiplikativno stvaraju originalni podatak u jednom
vremenskom razdoblju, on se može rasčlaniti :
Uzmimo podatke iz avgusta 2000. godine:
-prema trendu je trebala biti proizvedeno 227,47
-zbog uticaja sezone proizvedeno je za 54,9% više ili 124,88
to je ukupno 352,35
-zbog rezidualnih faktora proizvedeno je za 17,4% manje -61,3
-stvarno je proizvedeno 291,05
Izračunavanje mjesečnog trenda vrijednosti na bazi krivolinijskog trenda je komplikovanije
od linearnog trenda. Da bi izbjegli nastale probleme mjesečne trend vrijednosti računamo
mjesečne trend vrijednosti metodom pomičnih prosjeka.U tabeli su prikazane izračunate trend
vrijednosti za sve mjesece vremenske serije:
Mjesec
1997
1998
1999
2000
2001
1
2
3
21
34
45
12
14
28
14
19
36
12
27
34
26
33
45

112
4
5
6
7
8
9
10
11
12
1667
1638
1601
1533
1446
1369
1118
1068
1035
1030
1037
1050
1064
1086
1118
1338
1371
1382
1387
1384
1390
1402
1412
1395
1227
1220
1215
1230
1250
1267
1303
1388
1515
2042
2096
2133
24-mjesečne pomične totale smo dobili sumiranjem susjednih 12-mjesečnih totala
838+829=1667
829+809=1638
809+792=1601 itd.
24-mjesečne pomične totale ćemo podijeliti s 24 i dobiti 24-mjesečne pomične prosjeke, tj
trend vrijednosti krivolinijskog trenda izračunate metodom pomičnih prosjeka.Ttrend
vrijednosti
^
y
t
Mjesec
1997
1998
1999
2000
2001
1
2
3
4
5
6
7
8
9
10
11
12
69
68
67
64
60
57
54
51
48
47
45
43
43
43
44
44
45
47
48
51
54
56
57
58
57
58
58
58
58
58
56
53
52
51
51
51
51
52
53
54
58
63
70
77
82
85
87
89
Djeljenjem originalnih vrijednosti s odgovarajućim vrijednostima trenda dobićemo proizvode
uticaja sezone i reziduala.
Mjesec
1997
1998
1999
2000
2001
1
2
3
4
5
6
7
8
9
10
11
12
197
138
100
84
75
56
22
27
58
109
127
172
221
144
107
68
42
53
29
37
68
102
128
155
205
184
124
86
54
40
21
51
65
139
135
151
159
152
111
91
45
38
37
43
55
113
148
162
Za svaki mjesec imamo po četiri indeksa.Različiti su zbog rezidualnih uticaja.Uzimajući
njihovu srednju vrijednost , eliminisat ćemo rezidualne uticaje.
113
Pri izboru srednje vrijednosti opredjelili smo se za medijalnu , jer je ona manje osjetljiva na
ekstreme od aritmetičke sredine.
Mjesec
Medijana
indeksi
1
2
3
4
5
6
7
8
9
10
11
12
25,5
40
61,5
111
131,5
158,5
201
148
109
85
49,5
46,5
Ukupno
1167,0
Suma medijana indeksa nije 1200, pa prema tome to nije konačni sezonski indeksi.Moramo
izračunati korektor:
1200
1167
=1,0283
Mjesec
Medijana indeksi
Sezonski indeksi
1
2
3
4
5
6
7
8
9
10
11
12
25,5
40
61,5
111
131,5
158,5
201
148
109
85
49,5
46,5
26
41
63
114
135
164
207
152
112
88
51
48
ukupno
1167
1200
Da bi dobili čiste podatke od sezonskog uticaja, moramo podijeliti svaku originalnu vrijednost
s odgovarajućum sezonskim indeksom
Mjesec
1997
1998
1999
2000
2001
1
2
81
83
46
34
54
46
46
66
100
80

115
Kretanje rezidualne komponente prikazano grafički.
Analiza proizvodnje piva za januar 200.godine:
-prema trendu realizacija je 56hl
-zbog sezonskog uticaja -41,44hl
-ukupno 14,56hl
-zbog rezidualnih faktora proizvedeno je -2,6hl
Realizacija januara 200.godine 11,96hl
4.0.Osnovni skup i uzorak
Ako statistički skup , koji se ispituje statističkom metodom, ima mnogo elemenata, treba
skupiti mnogo informacija, veliki broj mjerenja,što predstavnja dugotrajan i skup posao,
pristupa se prikupljanju manje, podataka samo za jedan dio elemenata statističkog skupa.Dio
osnovnog skupa koji se ispituje zove se
uzorak.
Uzorak je
reprezentativni
ako je po svojim
osnovnim karakteristikama liči na osnovni skup ili ako je uzorak umanjena slika od osnovnog
skupa.
Metode pomoću kojih se određuje pouzdanost i preciznost procjene karakteristika osnovnog
skupa jednim imenom zovemo
metoda uzorka ili reprezentativna metoda.
Ako se u uzorak izaberu elementi redom , a nakon izbora se ne vraćaju u osnovni skup tada
imamo izbor uzorka
bez ponavljanja.U
koliko se svaki izabrani element za uzorak nakon
izbora vraća u osnovni skup, tako da učestvuje u izboru sljedećeg elementa za uzorak tada
imamo izbor uzorka
sa ponavljanjem.
Izbor elemenata osnovnog skupa u uzorak može biti:
namjernim izborom elemenata
pri čemu
istraživač za uzorak izabere elemente iz osnovnog skupa prema ličnom nahođenju, iskustvu
itd.
Slučajan izbor elemenata
za uzorak pri čemu za svaki element postoji mogućnost da bude
podjednako izabran za uzorak.
4.1.Procjena karakteristika osnovnog skupa pomoću uzorka
Ako je osnovni skup beskonačan ili ako se veličina osnovnog skupa ne može odrediti, onda se
karakteristike ne mogu izračunati iz podataka o svim elementaima skupa, nego iz podataka
samo jednog dijela osnovnog skupa.Ako je taj dio elemenata osnovnog skupa reprezentativni
uzorak onda karakteristike izračunate za uzorak mogu poslužiti za procjenu tih karakteristika
osnovnog skupa
θ
.
116
Procjena karakteristika osnovnog skupa
θ
pomoću izračunate karakteristike iz uzorka je
intervalna procjena
^
θ
.Izračinavaju se granice u kojima se s određenom vjerovatnoćom nalazi
karakteristika osnovnog skupa.
Opšti oblik intervala izgleda ovako
:
^
θ
– greška procjene
¿
θ
< ^
θ
+greška procjene
4.1.1.Procjena aritmetičke sredine osnovnog skupa
U svakom od izabranih uzoraka možemo izračunati sve karakteristike, koje ima osnovni
skup , pa prema tome i aritmetičku sredinu.Aritmetičke sredine uzorka su različite.One
variraju, a što je posljedica numeričkog obilježja elemenata , izabranih u pojedini
uzorak.Postavlja se pitanje:kako se može karakteristika osnovnog skupa procjeniti pomoću
karakteristika samo jednog uzorka?
Vezu osnovnog skupa i uzorka pokušaćemo objasniti na primjeru.Imamo jedan mali osnovni
skup od deseteto djece.Iz tog skupa biraćemo na slučajan način uzorak od 2.Djecu
označavamo sa slovima:
Djete
a
b
c
d
e
f
g
h
i
j
Starost
3
3
4
5
6
7
7
8
8
9
Suma osnovnog skupa svih godina starostI:
∑
i
=
1
10
x
i
=60.
Broj elemenata osnovnog skupa N=10
Aritmetička sredina osnovnog skupa
x
=60:10=6 godina;
Standardna devijacija osnovnog skupa :
σ=
√
∑
i
=
¿¿
N
(
X
i
−
X
)
²
N
=
2,05
Iz osnovnog skupa od 10 elemenata možemo izabrati 45 različitih uzoraka po 2 elementa.Sve
kombinacije su prikazane:
ab ac ad ae af ag ah ai aj 9
bc bd be bf bg bh bi bj 8
cd ce cf cg ch ci cj 7
de df dg dh di dj 6
ef eg eh ei ej 5
fg fh fi fj 4
gh gi gj 3
hi hj 2

118
Kao što možemo zaključiti, aritmetička sredina uzoraka(
očekivana vrijednost
) veličine
„
n“
koji se mogu izabrati iz jednog osnovnog skupa , uvijek je jednaka aritmetičkoj sredini tog
osnovnog skupa.
Distribucijaaritmetičkih sredina ima i svoju varijansu i standardnu devijaciju.U toj distribuciji
aritmetička sredina uzoraka
x
je varijabla, a aritmetička sredina te varijable je aritmetička
sredina osnovnog skupa (
μ
).Odstupanje aritmetičkih sredina uzoraka od aritmetičke sredine
osnovnog skupa ima „
k
“.varijansa distribucije sredina uzoraka glasi:
σ
x
2
=
1
k
∑
i
=
1
k
(
x
i
−
μ
)
²
Drugi korijen iz varijanse distribucije sredina uzoraka
σ
x
daje standardnu devijaciju
distribucije sredina uzoraka, koja se zove
standard error ili standardna greška p
rocjene
aritmetičke sredine osnovnog skupa.zašto se standardna devijacija distribucije sredina uzoraka
zove standardna greška?Aritmetičkom sredimom uzorka procjenjuje se aritmetička sredina
osnovnog skupa, pa je razlika (odstupanje
x
i
−
μ
) greška u procjeni aritmetičke sredine
osnovnog skupa.prosječna greška je standardna devijacija, zato se u tom slučaju zove
standardnom greškom (
σ
x
).
U našem primjeru standardna greška je:
σ
x
=1,37
Ako se može izvršiti identifikacija teorijske distribucije prema kojoj sampling varijabla
poprima svoje vrijednosti, onda se može odrediti i vjerovatnoća kojom će karakteristika
uzorka, ako je ona diskretna varijabla, poprimiti vrijednosti nekog realnog broja
x
, odnosno
ako karakteristika uzorka kontinuirana varijabla, može se odrediti vjerovatnoća kojom će se
karakteristika uzorka nalaziti u intervalu između dva realna broja
x
1
i
x
2
.
Aritmetičke sredine uzoraka se raspoređuju oko aritmetičke sredine osnovnog skupa u obliku
normalne distribucije ili oblika koji je blizi normalnoj distribuciji.To znači da se pomoću
tablica površina ispod normalne krive može naći da će 68,27% mogućih uzoraka imati
aritmetičku sredinu koja od aritmetičke sredine osnovnog skupa neće odstupati više od jedne
standardne greške u lijevu i desnu stranu te da će se 95,45% svih sredina uzoraka nalaziti u
pojasu od dvije standardne greške od aritmetičke stredine osnovnog skupa.Gotovo sve ,
tačnije 99,73%aritmetičkih sredina uzorakaneće odstupiti od aritmetičke sredine osnovnog
skupa više nego za tri standardne greške.U 5% slučajeva možemo očekivati da će sredina
uzorka odstupiti od aritmetičke sredine osnovnog skupa za više od 1,96 standardnih grešaka.
Ili, vjerovatnoća da će se sredina uzoraka razlikovati od aritmetičke sredine osnovnog skupa
za više od 1,96
σ
x
iznosi 0,05.
Kako smo naglasili u prethodnom izlaganju, aritmetičke sredine uzoraka mogu da se nalaze u
bilo kom intervalu.Ukoliko se one izraze u obliku standardizovanog obilježja (spomenuli smo,
prethodno, 1,96, to je vrijednost standardizovanog obilježja), tada sempling distribucija
aritmetičkih sredina uzoraka iznosi:
119
z
=
x
i
−
μ
σ
x
Aritmetička sredina slučajno odabranog uzorka većeg od 30 elemenata sa vjerovatnoćom 0,95
će se nalaziti između +1,96 i -1,96 i vrijedi nejadnačina:
-1,96
¿
x
i
−
μ
σ
x
<
¿
1,96
Ako je u našem primjeru greška 1,37.Šta nam to znači?To znači da se aritmetičke sredine
uzoraka veličine 2 grupišu oko prave aritmetičke sredine osnovnog skupa po raspodjeli , kojoj
standardna devijacija iznosi 1,37, pošto ne zanmo aritmetičku sredinu osnovnog skupa onda
zaključujemo sljedeće:ako standardna greška iznosi 1,37, onda naša dobijena aritmetička
sredina iz uzorka može od prave stredine odstupiti praktično najviše 3 standardne greške ili u
našem slučaju 4,11, pa zaključujemo da se aritmetička sredina osnovnog skupa nalazi negdje
u in tervalu artimetička sredina uzorka
±
4,11
ili uopšteno:
x
-3
σ
x
<
X
<
x
+3
σ
x
Ako standardu grešku množimo sa 3 vjerovatnoća da se aritmetička sredina nalazi u
navedenom intervalu je 0,9973.Pomnožimo li standardnu grešku sa 2, vjerovatnoća da se
aritmetička sredina nalazi u tako izračunatom intervalu je 0,9545.Brojevi 3 i 2 su
standardizovano obilježje, i može se napisati opšti oblik:
x
-z
σ
x
<
X
<
x
+z
σ
x
Ako je aritmetička sredina slučajnog uzorka veličine
n
¿
30
upotrebljena za procjenu
aritmetičke sredine osnovnog skupa
μ
, tada možemo s vjerovatnoćom 0,95 tvrditi da je
veličina greške te procjene manja od +1,9
6
σ
x
i veća od -1,96
σ
x
.
Budući da je standardna greška veličina greške koja se može očekivati u procjeni aritmetičke
sredine osnovnog skupa, to je standardna greška najvažniji element analize tačnosti
procjenena na osnovu uzorka uz oblik distibucije vjerovatnoće i očekivanu vrijednost te
distribucije.
U praksi se nikad neće izabrati svi mogući uzorci iz jednog osnovnog skupa, pa se za
računanje standardne greške koristi standardna devijacija osnovnog skupa.Ako se iz osnovnog
skupa sa N elemenata, koji ima aritmetičku sredinu
μ
i standardnu devijaciju
σ
izabere uzorak
od
n
elemenata, tada će standardna grešaka procjene aritmetičke sredine osnovnog skupa biti:
σ
x
=
σ
√
n
√
N
−
n
N
−
1
ako je N(broj elemenata osnovnog skupa) veliki, , a uzorak relativno mali u
odnosu na osnovni skup, tada će frakcija izbora(
f
)biti veoma mala a izraz
N
−
n
N
−
1
≈
N
−
n
N
=
N
N
-
n
N
=1-f
≈
1
približit će se broju 1.U tom slučaju standardna greška računa
se pomoću formule:

121
2.Koliku max.grešku možemo tolerisati.Izražava se u jedinici mjere u kojoj je izraženo
obilježje.
3.Standardnu devijaciju osnovnog skupa
Standardnu devijaciju ne znamo, zato što smo u fazi određivanja veličine uzorka, tako da ne
znamo ni standardnu devijaciju uzorka.Zbog toga moramo standardnu devijaciju osnovnog
skupa veoma grubo procjeniti, ako uzmemo pri procjeni uzmemo veću standardnu devijaciju
od stvarne, posljedica je to što ćemo za uzorak izabrati nešto veći broj elemenata , nego što je
potrebno.Ali veći broj elemenata za uzorak daje nešto precizniju procjenu od procjene kojom
bi smo se zadovoljili.
Poslije izračunatog broja elemenata u uzorku moramo provjeriti kolika je frakcija izbora.Ako
je manja od 0,05 onda je izračunata veličina uzorka
n
konačna.Ako je frakcija izbora veća od
0,05, mora se uzeti faktor korekcije, i pri tome ćemo dobiti konačan broj elemenata u uzorku:
n=
n
0
1
+
n
0
N
Rezime u kojem ćemo objasniti šta sve treba napraviti ukoliko želimo procjeniti aritmetičku
sredinu osnovnog skupa pomoću uzorka:
1.iz osnovnog skupa izaberemo određen broj elemenata za uzorak na slučajan način, pomoću
tablica slučajnih brojeva
2.u uzorku izračunamo:
X
–aritmetičku sredinu
σ
x
2
-
varijansu
σ
x
–
standardna devijaciaj
3.izračunamo standardu grešku procjene aritmetičke sredine osnovnog skupa po formuli:
σ
x
=
σ
√
n
√
N
−
n
N
−
1
ili po formuli
σ
x
=
σ
√
n
ako je f
¿
0,05
4. iz tablica površina ispod normalne krive određujemo koeficijent pouzdanosti“
z
„ za željenu
pouzdanost.tablice površina ispod normlne krive koristimo za određivanje koeficijenata
pouzdanosti za sve uzorke veće od 30 elemenata.Ako je uzorak manji od 30 elemenata,
koeficijent pouzdanosti određujemo pomoću Studentove t-distribucije.U slučaju procjene
malim uzorkom treba za koeficijent pouzdanosti uvrstiti vrijednost za
t
iz Studentove tablice
za određen broj stepena slobode.interval procjene aritmetičke sredine osnovnog skupa
pomoću malog uzorka će biti:
x
-t
σ
x
<
X
<
x
+t
σ
x
122
5.pomoću izračunatih veličina sastavljamo intervalnu procjenu aritmetičke sredineosnovnog
skupa
x ±
z
σ
x
6.donosimo zaključak u kome tvrdimo s određenom pouzdanošću da se aritmetička sredina
osnovnog skupa nalazi između donje i gornje granice izračunatog intervala procjene.
Primjer1:Izračunati prosječnu površinu posjeda na 615000 domaćinstava.
Površina u ha
Broj domaćinstva 000
-2
2-3
3-5
5-8
8-
256
109
124
84
42
Ukupno
615
Pomoću ovog uzorka sastavićemo 95% pouzdan interval procjene aritmetičke sredine
osnovnog skupa, to znači da moramo uvrstiti veličinu 1,96 iz tablica.Spremni smo u procjeni
tolerisati max. Grešku od 0,25ha tj d=025.Trebamo procjeniti standardnu devijaciju osnovnog
skupa.Površina posjeda u rasponu od 0-20 obuhvata sav domaćinstav.Prije smo naveli da su
elementi gotovo svake distribucije obuhvaćeni u rasponu od šest standardnih devijacija, pa
gruba procjena standardne devijacije :20:6=3,33ha.Zaokružićemo ma 3,5ha.Sada imamo sve
za određivanje broja elemenata u uzorku:
n=
[
1
,
(
3,5
)
0,25
]
²
=27,44² =753 elementa
za preciznost procjene prosječne površine od 0,25 ha uz pouzdanost 0,95 i procjenjenu
standardnu devijaciju osnovnog skupa od 3,5 trebalo bi izabrati 753 poljoprivredna
domaćinstva.
Frakcija iznosi:
F=
753
615000
=0,0012
Distribucija domaćinstva prema površini zemljišta
Površona
U ha
Sredina
razreda
Broj
Domaćin.
x
i
f
i
x
i
f
i
f
i
x
i
2
f
i
x
i
3
f
i
x
i
4
-2
2-3
3-5
5-8
8-
1
2,5
4
6,5
12,5
285
143
148
112
59
285
357,5
592
728
737,5
285
893,75
2368
4732
9218,75
285
2234375
9472
30758
115234,3
285
5586
37888
199927
1440430
747
2700
17497,5
157983,7
1684116

124
Total je suma vrijednosti numeričkog obilježja.Total se računa kao proizvod broja elemenata i
njihove aritmetičke sredine.kako nam aritmetička sredina osnovnog skupa nije poznata,
uzorak će nam pomoći da procjenimo total osnovnog skupa.Total osnovnog skupa dobijemo
ako aritmetičku sredinu uzorka pomnožimo s brojem elemenata u osnovnom skupu N:
∑
x
=N
x
Procjenom totala čini se N puta toliko grešaka , koliko ima elemenata u osnovnom skupu.Pa
iz toga se zaključuje, standardna greška procjene totala osnovnog skupa jednaka je N puta
standardna greška procjene aritmetičke sredine:
σ
∑
x
=N
σ
x
Interval procjene totala osnovnog skupa pomoću uzorka je:
N x
-z
Nσ
x
<
∑
X
<
N x
+z
N σ
x
Veličina uzorka za procjenu totalu osnovnog skupa pomoću uzorka je:
n=
[
N
zσ
d
]
²
U našem prethodnom primjeru interval procjene totala osnovnog skupa glasi:
615000(3,6144)-1,96(615000)0,1178
¿
∑
x
<
615000
(
3,6144)+1,96(615000)0,1178
2222856-1,96(72 452 772)
¿
∑
x
<
¿
2222856+1,96(72 452 772)
2222856-142007
¿
∑
x
<
¿
2222856+142007
2 080 849
¿
∑
x
<
¿
2 364 863
Zaključak:Ukupna površina zemlje svih 615 000 poljoprivrednih domaćinstava s
vjerovatnoćom od 0,95 , veća je od 2 080 849 hektara i manja od 2 364 863 hektara.
4.1.3.Procjena merdijane osnovnog skupa
Procjenu medijane osnovnog skupa objašnjavamo na osnovu rezultata uzorka.Sampling
distribucija će biti distribucija medijana svih „
k“
uzoraka.Ako veličina uzorka raste sampling
distribucija medijana približava se obliku normalne krive.Varijansa sampling distribucije
medijana uzoraka je:
σ
^
Me
2
=
σ
2
π
n
2
=
σ
2
n
1,570796
Standardna greška procjene medijane osnovnog skupa na bazi uzorka je:
125
σ
^
Me
=
σ
√
n
√
π
2
=
σ
x
1,253 31
Interval procjene medijane osnovnog skupa .
^
M
e
-z
σ
^
Me
<
M
e
< ^
M
e
+z
σ
^
Me
Iz prethodnog primjera izračunali smo da je medijana uzorka:
^
M
e
=2,619 hektara.Standardna
greškaprocjene medijana osnovnog skupa pomoću uzorka iznosi :
σ
^
Me
=
σ
√
n
√
π
2
=
σ
x
1,253 31 =0,1178
∙
1.253 31=0,147 64
Interval procjene medijana osnovnog skupa je:
2,619-1,96(0,147 64)
¿
M
e
<
¿
2,619+1,96(0,147 64)
2,619-0,289
¿
M
e
<
¿
2,619+0,289
2,33
¿
M
e
<
¿
2,91
Zaključak:S vjerovatnoćom 0,95 možemo tvrditi da je medijana osnovnog skupa veća od 2,33
ha i manja od 2,91 ha.
4.1.4.Procjena kvartila osnovnog skupa
Sampling distribucijakvartila uzoraka približava se obliku normalne distribucije ako veličina
uzorka raste.Standardna greška procjene bilo donjeg ili gornjegkvartila osnovnog skupa
pomoću uzorka iznosi:
σ
Q
=
σ
x
∙
1.362 63
U našem primjeru ne može se izračunati donji kvartil jer prvi razred sadrži više od četvrtine
svih elemenata.Iz tih podataka izračunali smo gornji kvartil uzorka:
Q
3
=
4,787
.standardna
greška procjene kvartila iznosi:
σ
^
Q
=0,1178(1,362 63)=0,1605
Interval procjene gornjeg kvartila osnovnog skupa uz pouzdanost 95% je:
4,787-1,96(0,1605)
¿
Q
3
<
¿
4,787+1,96(0,1605)
4,787-0,315
¿
Q
3
<
¿
4,787+0,315
4,472
¿
Q
3
<
¿
5,095

127
Određivanje veličine uzorka za procjenu proporcije osnovnog skupa je u fazi određivanja
varijanse osnovnog skupa mnogo jednostavnije, nego što je pri određivanju veličine uzorka za
procjenu aritmetičke sredine.S obzirom da je
p+q=1 ,
najveća moguća vrijednost varijanse je
u slučaju kada
je: p=q=0,5
tada varijansa može imati najveću vrijednost 0,25.Ako ne znamo
varijansu osnovnog skupa predpostavićemo najveću moguću varijansu.Pri čemu ćemo imati,
uz preciznost i pouzdanost , veći uzorak nego što bi bio dovoljan.
Sampling distribucija proporcija svih uzorakakoji se mogu izabrati iz osnovnog skupa
određene veličine
n
ima oblik blizu normalnoj distribuciji ako je
n
¿
30
.
Standardna greška procjene proporcije osnovnog skupa je:
^
σ
p
=
√
pq
n
(
N
−
n
n
−
1
)
, u najvećem broju slučajeva nećemo znati proporciju osnovnog skupa, niti
njegovu varijansu i standardnu devijaciju, zato ćemo proporciju procjeniti iz uzorka na
sljedeći način:
^
σ
p
=
√
^
p
^
q
n
−
1
√
(
N
−
n
N
−
1
)
ako je frakcija izbora manja od 0,05:
^
σ
p
=
√
^
p
^
q
n
−
1
Interval procjene osnovnog skupa s određenom preciznošću nalazi unutar intervala:
^
p
-z
σ
^
p
<
¿
p
¿
^
p
+z
σ
^
p
U prethodnom primjeru uzorka želimo procjeniti proporviju poljoprivrednih domaćinstava
koja imaju površinu zemljišta veličine do 2 ha.Procjenu želimo dati sa 95%pouzdanosti.ne
želimo veću grešku procjene od 0,035.Proporciju osnovnog skupa ne znamo , pa ćemo za
računanje veličine uzorka uzeti najnepovoljniju varijansu :0,25.Računamo veličinu uzorka:
n
0
=
[
z
√
pq
d
]
²=
[
1,96
√
0,25
0,025
]
²
=
784
Veličina je uzoka n=747.Proporcija uzorka je
^
p
=
285
747
=
0,3815
Standardna greška procjene:
σ
^
p
=
√
(
0,385
)(
0,6185
)
0,035
=
0,01777
Interval procjene proporcije osnovnog skupa :
0,3815-1,96(0,01777)
¿
p
¿
0,3815+1,96(0,01777)
0,3815-0,03483
¿
p
¿
0,3815+0,03483
128
0,34667
¿
p
¿
0,41633
Zaključak:Sa 95%pouzdanosti možemo tvrditi da je osnovnom skupu proporcija
domaćinstava s površinom zemljišta do 2ha veća od 0,34667 i manja od 0,41633.
5.0.Testiranje hipoteza
U prethodnom poglavlju objasnili smo metodu i postupke , koji nam omogućavaju da iz dijela
osnovnog skupa, slučajno izabranog uzorka, procjenimo određenu karakteristiku osnovnog
skupa uz određenu grešku.Moguće je isto uraditi i na drugi način.Predpostavimo da neka
karakteristika osnovnog skupa , koja je poznata, ima određenu numeričku vrijednost.Da bi tu
vrijednost provjerili, iz osnovnog skupa izabere se uzorak i izračuna ta
karakteristika.Izračunata karakteristika uzorka upoređuje se sa predpostavljenom
vrijednostima karakteristika osnovnog skupa.Na osnovu razlike donosimo zaključak:
1.ako razlika nije velika smatra se slučajnom i kaže se da je moguća, a predpostavka može biti
istinita
2.ako je razlika velika kažemo da je značajna , te da je predpostavka nemoguća ili lažna
Pretpostavke se sreću pod imenom istraživačke ili radne hipoteze.ispitivanje pretpostavki se
zove testiranje hipoteza.postupak testiranja hipoteza temelji se na istim teoretskim osnovama
kao i procjena karakteristika osnovnog skupa.Hipoteze se mogu odnositi na sve karakteristike
osnovnog skupa.
5.0.1.Testiranje hipoteze da je aritmetička sredina osnovnog skupa jednaka nekoj
pretpostavljenoj numeričkoj vrijednosti
Često u praksi moramo odrediti ima li nepoznata aritmetička sredina osnovnog skupa neku
određenu vrijednost(
μ
0
).U vezi s tim posavljamo hipotezu da je aritmetička sredina
osnovnog skupa jednaka nekoj pretpostavljenoj aritmetičkoj sredini:
H
0
⋯
μ
=
μ
0
Takva hipoteza zove se
nul-hipoteza
i označava se sa
H
0
.Nul –hipotezom tumačimo
nepostojanje razlike između stvarne aritmetičke sredine osnovnog skupa i predpostavljene
aritmetičke sredine osnovnog skupa.
Nasuprot ovoj hipotezi stoji pretpostavka da aritmetička sredina osnovnog skupa nije jednaka
pretpostavljenoj aritmetičkoj sredini, to je tz.
alternativna hipoteza
označava se sa
H
1
H
1
⋯
μ ≠ μ
0
Treba li nul hipotezu prihvatiti ili odbaciti?Odgovor na to pitanje daje postupak testiranja
hipoteza s podacima iz uzorka.Broj elemenata koje ćemo izabrati za uzorak računamo na isti
način kao kada se određuje broj elemenata za uzorak koji će poslužiti za procjenu aritmetičke

130
Grafički prikazano područje odbacivanja i prihvatanja nul hipoteze
(1 - α )
α/2
α/2
Z ~ N
(0,1)
-z 0 +z
Područje odbacivanja Područje prihvaćanja Područje odbacivanja
U slučaju testiranja hipoteze pretpostavlja se za aritmetičku sredinu osnovnog skupa
vrijednost
μ
0
, te se interval prihvatanja nul hipoteze formira tako da se pođe od
pretpostavljene aritmetičke sredine osnovnog skupa tj. od
μ
0
± z σ
x
Pri čemu je
z
tablična vrijednost
.
U testiranju hipoteza cilj nam je da odbacimo što više lažnih i što manje istinitih hipoteza.Nul
hipoteza je ili istinita ili lažna, možemo je prihvatiti ili odbaciti.Ako je nul hipoteza istinita i
prihvaćena, a lažna i odbačena, odluka je bila ispravna.A ako je nul hipoteza istinita a
odbačena učinili smo grešku , koja se u statistici zove
greška tipa I
, a ako je nul hipoteza
lažna, a mi je prihvatimo učinili smo grešku koju zoveme
greška tipa II.
Šematski prikazano:
131
Nul-hipoteza
je prihvaćrna
Nul-hipoteza
je odbačana
Nul-hipoteza je istinita
Odluka je ispravna
Učinjena je greška
tipa II
Nul-hipoteza je lažna
Učinjena je greška
tipa II
Odluka je ispravna
Područjem prihvatanja hul hipoteze obuhvaćene su vrijednosti aritmetičkih sredina svih
uzoraka koji se mogu izabrati iz osnovnog skupa s aritmetičkom sredinom koju smo
pretpostavili.praktično ne možemo učiniti grešku tipa I.Kako možemo pri tom učiniti grešku
tipa II?
Aritmetička sredina izabranog uzorka, što smo izabrali iz osnovnog skupa, udaljava se
za manje od tri standardne greške a više od 2,58 standardnih grešaka od pretpostavljene
aritmetičke sredine osnovnog skupa, vjerovatnoća izbora takvog uzorka je mala.Veća je
vjerovatnoća da je uzorak s takvom aritmetičkom sredinom izabran iz osnovnog skupa koji
ima veću, tj. manju aritmetičku sredinu od pretpostavljene.To prikazuju grafikoni:
-z 0
Područje odbacivanja Područje prihvaćanja
α
1 -
α
Z ~ N
(0 , 1)
0 z
Područje prihvaćanja Područje odbacivanja
α
1 -
α
Z ~ N
(0 , 1)

133
σ
=2,6661
Standardna greška procjene aritmetičke sredine:
σ
x
=0,0666
Da bi se zaštitili da ne napravimo grekšku tipa II, povećaćemo rizik da se učini greška tipa
I.odlučili smo se da testiramo na nivo 5%signifikantnosti.
Možemo prvo testom mjeriti udaljenost aritmetičke sredine, izračunate u uzorku, od
pretpostavljene aritmetičke sredine u standardnim greškama:
Z=
x
−
X
0
σ
x
=8,82
σ
x
Prema prvom testu
nul hipotezu , da je prosječna starost djece školskog tipa u gradu B
11godina,odbacujemo kao lažnu na nivou 5% značajnosti, jerje razlika između izračunate
aritmetičke sredine iz uzorka i pretpostavljene vrijednosti velika.Pošto je na nivo
5%signifikantnosti dozvoljena razlika 1,96
σ
x
Drugim testom formiramo interval prihvatanja nul hipoteze:
X
0
± z σ
x
11
±
1,96
∙
0,0666
11-0,1305..............11+0,1305
10,8695.................11,1305
Aritmetička sredina , izračunata iz uzorka je 11,5875.ne uklapa se u interval prihvatanja nul
hipoteze, jer je veća od gornje granice tog intervala.To je razlog odbacivanja nul hipoteze, kao
lažne po drugom testu.Tvrdimo da uzorak koji ima aritmetičku sredinu 11,5875, nije mogao
biti izabran iz osnovnog skupa koji ima aritmetičku sredinu 11 i standardnu devijaciju
0,0666.da smo iz osnovnog skupa školske djece izabrali neki drugi uzorak veličine 1600 i
dobili aritmetičku sredinu u tom uzorku veću od 10,8695 i manju od 11,1305 zaključili bismo
na nivou 5%signifikantnosti da se nul hipoteza može prihvatiti kao mogućnost.u tom slučaju
bi vjerovatnost da smo prihvatili istiniti hipoteuu bila 95%.
Uzorak s aritmetičkom sredinom većom od 10,8695 i manjom od 11,1305 može se izabrati i
iz serije osnovnih skupova koji imaju aritmetičke sredine blizu 11.Ako smo prihvatili nul
hipotezu, a istina je da je uzorak izabran iz nekog drugog osnovnog skupa , učinili smo grešku
tipa II.Vjerovatnoća sa smo učinili grešku tipa II je različita od jednog do drugog osnovnog
skupa.
Granica intrvala prihvatanja nul hipoteze su 10,8695 i 11,1305 , ako je izabran uzorak dao
aritmetičku sredinu, koja se uklapa u tako formirani interval, prihatićemo nul hipotezu kao
moguću.Uzimamo za primjer da uzorak ima graničnu vrijednost -10,8695. Taj uzorak je
134
mogao biti izabran iz osnovnog skupa s aritmetičkom sredinom 10,9 ili 10,8 ili 10,7.Možemo
posmatrati položaj aritmetičke sredine 10,8695 u svakoj od njih , u odnosu na interval
prihvatanja nul hipoteze.
Površina ispod normalne krive, obuhvaćenu intervalom prihvatanja nul hipoteze za sampling
distribuciju s očekivanom vjerovatnoćom 10,9 izračunaćemo poslije izračunavanja z
vrijednosti:
z=
10,8695
−
10,9
0,0666
=
−
0,0305
0,0666
=-0,455
proporcija površine s lijeve strane distribucije je 0,1722.proporcija površine s desne strane
distribucije omogućiće izračunavanje pozitivne vrijednosti „z“:
Svih 0,5 desne strane površine obuhvaćeno je intervalom prihvatanja nul hipoteze.Ukupna
površina u sampling distribuciji aritmetičkih sredina s očekivanom vrijednošću 10,9 je
0,5+0,1772=0,6772.
Vjerovatnoća da se iz osnovnog skupa s aritmetičkom sredinom 10,9 izabere uzorak koji će
dati aritmetičku sredinu, koja će pasti u interval prihvatanja nul hipoteze
X
=11, i prema tome
dovesti do prihvatanja nul hipotezeje 0,6772.To je vjerovatnoća da ćemo učiniti grešku tipa II
a obzirom na osnovni skup s aritmetičkom sredinom 10,9.
Možemo prihvatiti lažnu nul hipotezu i tako ućiniti grešku tipa II.Vjerovatnoća sa de učini
greška tipa II , označava se
β
.Vjerovatnoća
β
da se učini greška tipa II jednaka je
vjerovatnoći da aritmetička sredina uzorka pada u područje prihvatanja nul hipoteze, iako je
uzorak izabran iz osnovnog skupa koji ima različitu aritmetičku sredinu od one koju smo
predpostavili., što znači da je naša nul hipoteza lažna.
Iz našeg primjera , pogledajmo kolika je vjerovatnoća da ćemo učiniti grešku tipa II s obzirom
na osnovni skup s aritmetičkom sredinom 10,8.
z=
10,8695
−
10,8
0,0666
=
−
0,0695
0,0666
=1,044
Iuzračunatoj vrijednosti „z“ odgovara površina ispod normalne krive 0,3508, što znači da
ćemo učiniti grešku tipa II s obzirom na osnovni skup s aritmetičkom sredinom 10,8 je 0,5-
0,3508=0,1492.
Tako se računa greška tipa II za sve osnovne skupove koji imaju susjedne vrijednosti
aritmetičkih sredina pretpostavljenoj aritmetičkoj sredini.
β
je vjerovatnoća da se prihvati nul hipoteza.Suprotna je vjerovatnoća(1-
β
) da se odbaci lažna
nul hipoteza tj. vjerovatnoća da ćemo izbjeći pogrešnu odluku.Razlika (1-
β
) naziva se snaga
testa.

136
Postupak testiranja uključuje izbor uzorka iz osnovnog skupa, te računanje aritmetičke
sredine, varijanse i standardne devijacije u tom uzorku.Zatim moramo izračunati standardnu
gešku procjene aritmetičke sredine osnovnog skupa .
Ako iz osnovnog skupa na koji se odnosi ta hipoteza izaberemo uzorak i ako se izračuna
aritmetička sredina uzorka , u donošenju odluke razlikujemo tri slučaja:
1.ako je aritmetička sredina uzorka jednaka ili veća od pretpostavljene atitmetičke sredine
osnovnog skupa, u tom slučaju je uzorak mogao biti izabran iz osnovnog skupa koji ima
aritmetičku sredinu jednaku ili veću od pretpostavljene, to je u skladu sa nul hipotezom
μ ≥ μ
0
.Nije potrebno nastaviti testiranje , i prihvatiti nul hipotezu.
2.ako je aritmetička sredina uzorka manja od pretpostavljene aritmetičke sredine uzorka
μ
<
μ
0
, ali i veća od vrijednosti granice
μ
0
-3
σ
x
, u tom slučaju taj uzorak je mogao biti izabran iz
osnovnog skupa koji ima aritmetičku sredinu jednaku
μ
0
ili čak veću od
μ
0
i odlučiti da se nul
hipoteza može prihvatiti.
3. ako je aritmetička sredina uzorka manja od vrijednosti granice
μ
0
-3
σ
x
,onda je gotovo
pouzdano da uzorak sa tako malom aritmetičkom sredinom nije mogao biti izabran iz
osnovnog skupa koji ima aritmetičku sredinu jednaku ili čak veću od pretpostavljene.Nul
hipoteza se odbacuje i prihvata alternativna.u ovom slučaju testiranja hipoteze , granica što
odvaja područje prihvatanja hipoteze od područja odbacivanja hipoteze određena je jednom
vrijednošću , a to je
μ
0
-3
σ
x
.pri čemu ne možemo učiniti grešku tipa I.Postoji velika
vjerovatnoća da učinimo grešku tipa II.Da bi smanjili vjerovatnoću da se učini greška tipa II ,
treba se izložiti riziku da se napravi greška tipa I tj. da se granica područja prihvatanja nul
hipoteze pomakne udesno prema većim vrijednostima.
Ako izaberemo testiranje na nivou 5%signifikantnosti ili drugim rječima , vjerovatnoća da
učinimo grešku tipa I povećat ćemo za 5%.U tabili vrijednostz=1,65 i omeđuje 45%
površine(normalne raspodjele) od sredine prema kraju.Granica koja odvaja područje
prihvatanja od područja odbacivanja nul hipoteze ima vrijednost:
μ
0
-1,65
σ
x
Ta vrsta testa zove
se test na donju granicu
ili na lijevi krak distribucije.Opšti izraz granice
koja razdvaja područje prihvatanja od područja odbacivanja nul hipoteze može se napisati:
μ
0
-z
σ
x
,
137
Na isti način , samo na suprotnom kraku sampling distribucije, testira se nul hipoteza:
H
0
....
μ ≤ μ
0
I alternativnu da je:
H
1
....
μ
>
μ
0
Primjer1:
stanovnici grada C dožive više od 70 godina.izabrali smo uzorak 256 podataka o
godinama starosti.prosječna starost u uzorku je 71,268 godina, s prosječnim odstupanjem od
tog prosjeka za 15,312 godina.Provjeričemo rezultatima uzorka navedenu tvrdnju na nivou
od1%signifikantnosti.
Prvo moramo postaviti nul i alternativnu hipotezu:
H
0
....
μ ≤
70
I alternativnu da je:
H
1
....
μ
>
70
; u alternativnoj hipotezi je radna hipoteza.Koeficijent pouzdanosti u testu na
jednu granicu iznosi 2,33.standardna greška procjene aritmetičke sredine:
σ
x
=
s
√
n
=
15.312
√
265
=0,957
Gornja granica prihvatanja nul hipoteze.
μ
0
+z
σ
x
,
70+2,33x0,957
70+2,2298
Aritmetička sredina izračunata iz uzorka je 71,268.Ona je manja od 72,2298.To znači da se
nalazi u području prihvatanja nul hipoteze.Na nivou od 1%signifikantnosti se ne možemo
složiti sa tvrdnjom da stanovnici grada C u prosjeku dožive više od 70 godina.da smo umjesto
gore navedene tvrdnje čuli tvrdnju kako stanovnici grada C dožive manje od 70 godina,
hipoteze bi postavili :
H
0
....
μ ≥
70
I alternativnu da je:
H
1
....
μ
<
70
bio bi to test prihvatanja nul hipoteze na donju granicu.tu granicu bi odredili na
sljedeći način:
μ
0
-z
σ
x
,
5.0.3.Testiranje hipoteze o razlici između aritmetičkih sredina dvaju osnovnih skupova

139
dva osnovna skupa različita.Ukoliko se razlika nalazi u području prihvatanja nul hipoteze,
tada se nul hipoteza prihvata kao moguća.
Primjer 1:
Prosječna ocjena studenata iz predmeta Statistika jednaka je prosječnoj ocjeni iz
predmeta Matematikaod studenata koji su polagali Statistiku izabrali smo njih 45 za uzorak i
izračunali prosječnu ocjenu , koja iznosi 3,225 i varijansu koja iznosi 0,81.Drugi uzorak čine
studenti koji su polagali Matematiku.Uzeli smo uzorak od 35 studenata, čija je prosječna
ocjena 2,962 a varijansa 0,84.
Tvrdnju ćemo ispitati na nivou 5% signifikantnosti.Hipoteze glase
H
0
......
μ
1
-
μ
2
=0
H
1
......
μ
1
-
μ
2
≠
0
Prema nul hipotezi razlike između aritmeičkih sredina prvog i drugog osnovnog skupa je
jednaka nuli, dok je po alternativnoj hipotezi razlika između aritmetičkih sredina različita od
nule.
Standardna greška:
σ
x
1
−
¿
x
2
¿
=
√
^
σ
1
2
n
1
+
^
σ
2
2
n
2
=
√
0,18
+
0,024
=0,205
Koeficijent pouzdanosti za 5% signifikantnosti iznosi 1,96
0
± z σ
x
1
−
¿
x
2
¿
0
±
1,96 x 0,205
0
±
0,4018
-0,4018.......+0,4018
Razlika između aritmetičkih sredina uzoraka je 0,263.Ta razlika se uklapa u interval
prihvatanja nul hipoteze.Na nivou 5%signifikantnosti možemo prihvatiti kao moguću
hipotezu da je prosječna ocjena iz predmeta Statistika jednaka prosječnoj ocjeni iz predmeta
Matematika.
5.0.4. Testiranje hipoteze o jednakosti aritmetičkih sredina više osnovnih skupova.Analiza
varijanse
Hipoteza da su aritmetičke sredine dva ili više osnovnih skupova među sobom jednake
testiraćemo metodom poznatom kao
analiza varijanse.
Metoda se zasniva na rasčlanjivanju ukupnog zbira kvadrata odstupanja mjerenih vrijednosti
od njegove aritmetičke sredine, u komponente prema određenim izvorima varijacije.Zbog
140
jasnoće, uzet ćemo da je iz svakog od
k
normalno distribuiranih osnovnih skupova s jednakom
varijansama izabran po jedan uzorak veličine
n
elemenata.Vrijednost obilježja svakog
elementa izabranog za uzorak označena je sa
x
ij
, gdje je
i
broj elemenata u uzorku
(
i=1,2,3....n)
, a
j
je uzorak kome pripadaju elementi
(j=1,2,3...k)
.Aritmetička sredina uzorka
j
označena sa
x
j
je
x
j
=
∑
i
=
1
n
x
ij
n
j=1,2,3....k
A zajednička aritmetička sredina sa
x .
.
x .
.=
∑
i
=
1
k
∑
j
=
1
n
x
ij
n ∙ k
Zbir kavdrata odstupanja vrijednosti za svaki od
k
uzoraka, dobit će se rasčlanjenjem zbira
kvadrata odstupanja za svaki
k
∙ n
elemenata.
∑
i
=
1
k
∑
j
=
1
n
(
x
ij
−
x
..)²=
∑
i
=
1
k
∑
j
=
1
n
(
x
ij
-
x
.
j
)² +
n
∑
j
=
1
k
(
x
. j
-
x
. j
)²,
izraz predstavlja analizu varijanse.
Metoda analiza varijanse primjenjuje se za testiranje nul hipoteze da su aritmetičke sredine
k
osnovnih skupova međusobno jednake:
H
0
....
μ
1
=
μ
2
.....=
μ
k
=
μ
Varijansa osnovnog skupa je:
σ
2
=
n
σ
x
2
Pošro je
σ
x
2
varijansa distribucije aritmetičkih sredina uzoraka veličine
n
izabranih slučajno iz
osnovnog skupa koji ima aritmetičku sredinu
μ
i varijansu
σ
2
, te kako smo nul hipotezu
pretpostavili da su aritmetičke sredina svih osnovnih skupova jednake, možemo uzeti kao da
svi uzorci izabrani iz osnovnog uzorka koji ima aritmetičku sredinu
μ
i varijansu
σ
2
,pa
možemo napisati da je :
σ
x
2
=
∑
i
=
1
k
(
x
. j
−
x
..
)
²
k
−
1
Uvrštavanjem izreza za varijansu distribucije aritmetičkih sredina uzoraka u izraz za varijansu
osnovnog skupa, dobijemo izraz za jednačinu
procjene varijanse osnovnog skupa ,
koju ćemo
označiti sa

142
Odluku o tome da li je razlika između dvije procjene varijanse osnovnog skupa slučajna ili
signifikantna donosimo na osnovu odnosa dviju procjena varijanse osnovnog skupa:
F=
^
σ
2
2
^
σ
1
2
je teorija F –distribucije, pa ćemo u testiranju hipoteze u tablici distribucije pročitati
tabličnu vrijednost za F pod određenim stepenima slobode i za izabrani nivo signifikantnosti
testiranja.U zaglavlju tabele je broj stepena slobode koji odgovara brojniku, a u predkoloni
tabele broj stepena slobode koji odgovara nazivniku, i na tom mjestu se pročita tablična
vrijednost F.Ako je izračunata vrijednost manja od tablične, znači da se razlike između dviju
procjena varijanse osnovnog skupa slučajna, i pri tom se nul hipoteza može prihvatiti.A ako je
izračunata vrijednost F jednaka ili veća od tablične vrijednosti F , tada je razlika između dvije
procjene varijanse između dvije procjene varijanse osnovnog skupa značajna.
Rezultati analize varijanse prikazani su u tabeli:
Izvor
varijacije
1
Zbir kvadrata odstupanja
Stepeni slobode
Ocjene var.
Uzorci različitih
veličina
Uzorci jednakih
veličina
Uzorci
Razl.
Vel.
Uzorci
Jed.vel.
1
2
3
4
5
6
Između
skupova
U skupovima
∑
i
=
1
k
n
j
(
x
. j
−
x
..
)
²
∑
i
=
1
k
∑
j
=
1
n
(
x
ij
−
x . j
)
²
n
∑
i
=
1
k
(
x
. j
−
x
..
)
²
∑
i
=
1
k
∑
j
=
1
n
(
x
ij
−
x . j
)
²
k-1
n-1
k-1
k(n-1)
^
σ
2
2
^
σ
1
2
UKUPNO
∑
i
=
1
k
∑
j
=
1
n
(
x
ij
−
x . j
)
²
∑
i
=
1
k
∑
j
=
1
n
(
x
ij
−
x . .
)
²
n-1
nk-1
Odnos varijansi F izračunava se tako da se u brojnik stavlja veća procjena varijanse.
143
Ukoliko je vrijednost F veća od jedan nul hipotezu odbacujemo.Testiranje pomoću analize
varijanse polazi od toga da se varijanse uzoraka međusobno ne razlikuju signifikantno.zato se
primjenjuje poseban test o homogenosti varijansi.Za to nam može poslužiti-
Bartlettov test.
Zbir kavdrata odstupanja vrijednosti elemnata u jednom uzorku od aritmetičke sredine uzorka
treba podijeliti odgovarajućim brojem stepena slobode(n-1), i to za svaki uzorak.I pri tome se
dobiju procjenevarijanse osnovnog skupa iz kojeg je uzorak izabran.najveću dobivenu
vrijednost tih procjena treba staviti u odnos s najmanjom.U zaglavlju tabele za vrijednosti F
distribucije treba pročitati broj stepena slobode za najveću varijansu, dok se broj stepena
slobode za najmanju varijansu nalaze u predkoloni.
Ako je izračunati odnos najveće i najmanje varijanse manji od nađene tablične vrijednosti F,
možemo reći da su razlike između varijansi uzorka slučajne, a rezultat testa analize varijanse
možemo smatrati valjanim.
Primjer 1:
Studente za vježbe iz statistike podjelili smo u tri grupe.U svakoj grupi primjenili
smo drugu nastavnu metodu vježbi.Na kraju vježbi željeli smo utvrditi da li postoji razlika u
efikasnosti između primjenjenih metoda.iz svake grupe izabrali smo uzorak po 10
studenata.Svima smo dali iste zadatke da ih riješe.Broj poena koje su studenti osvojili na
ispitu prikazali smo u tabeli.
Postavljamo nul hipotezu, da je efikasnost svake od tri predstavljene metode jednaka, tj.da je
aritmetička sredina postignutih poena u svakoj grupi studenata jednaka.nul-hipotezu ćemo
testirati metodom analize varijanse.
Prvo ćemo izračunati varijansu između uzoraka:
∑
j
=
1
k
(
∑
i
=
1
n
x
ij
)
²
n
-
(
∑
i
=
1
n
∑
j
=
1
k
x
ij
)
²
n ∙ k
=
(
710
2
10
+
830
2
10
+
690
2
10
)
-
(
710
+
830
+
690
)
²
3
(
10
)
= 1146,6
Zatim ćemo izračunati varijansu u uzorku prema formuli:
∑
j
=
1
k
∑
i
=
1
n
x
ij
2
−
∑
j
=
1
k
[
(
∑
i
=
1
n
x
ij
)
²
n
]
=170865-166910=3955
Elementi
(student) i
Broj poena
x
ij
Uzorak 1
Uzorak 2
Uzorak 3
1
2
3
4
5
6
7
8
67
51
89
72
80
55
74
92
83
94
95
61
79
86
99
73
70
81
74
63
51
72
85
67

145
Za devet(10-1) stepena slobode u zaglavlju i pretkoloni naći ćemo tabličnu vrijednost
F
.0,5
=3,18.Izračunata vrijednost F je manja od tablične, možemo zaključiti da prihvatamo
pretpostavku da su varijanse osnovnih skupova jednake.
5.0.5.Testiranje hipoteze da je proporcija osnovnog skupa jednaka nekoj pretpostavljenoj
vrijednosti
Ukoliko se mogu elememti osnovnog skupa grupisati prema alternativnom obilježju,
primjenjujemo test hipoteze da je proporcija osnovnog skupa jednaka nekoj pretpostavljenoj
vrijednosti(proporciji)
p=
p
0
Testiranje hipoteze da jeproporcija osnovnog skupa jednaka nekoj pretpostavljenoj
vrijednosti, bazira se na istim teoretskim postavkama kao već protumačemo testiranje
hipoteze o nepoznatoj aritmetičkoj sredini osnovnog skupa.
Postupak testiranja:
1.Postavljanje nul i alternativne hipoteze.
Nul hipoteza polazi od toga da nema razlike između proporcije osnovnog skupa i
pretpostavljene vrijednosti proporcije
H
0
......p -
p
0
=0
Alternativna hipoteza polazi od stava da postoji razlika između proporcije osnovnog skupa i
pretpostavljene vrijednosti te proporcije
H
1
......p -
p
0
≠
0
2.Iz osnovnog skupa , na koji se odnosi pretpostavka , izaberemo na slučajan način određen
broj elemenata za uzorak.U uzorku izračunamo proporciju i suprotnu proporciju
p=
m
n
; p+q=1 ; q=1-p
3.Izračunamo standardnu grešku procjene proporcije osnovnog skupa:
σ
^
p
=
√
pq
n
−
1
ako je f
¿
0,05
σ
^
p
=
√
pq
n
−
1
N
−
n
N
−
1
ako je
¿
0,05
4.Određujemo koeficijent pouzdanosti za željeni nivo signifikantnosti iz tablica površina
ispod normalne krive za sve uzorke koji su veći od 25 elemenata
146
5.Razliku između izračunate proporcije iz uzorka i pretpostavljene vrijednosti proporcije
osnovnog skupa izmjerimo jedinicama standardnih grešaka procjene proporcije:
z=
p
−
p
0
σ
^
p
ako je izračunati „z“ manji od koeficijenta pouzdanosti za željeni nivo signifikantnosti,
možemo prihvatiti nul hipotezu kao moguću.razliku između izračunate proporcije iz uzorka i
pretpostavljene proporcije u tom slučaju pripisujemo sampling varijacijama.Kada je razlika
između proporcije uzorka i pretpostavljene proporcije izmjerena standardnim greškama
procjene proporcije:
p
0
± z σ
^
p
Nul hipotezu ćemo prihvatiti kao moguću ako se proporcija uzorka uklapa u područje nul
hipoteze.Ako proporcija uzorka pada u područje ispod donje granice ili u područje iznad
gornje granice područja prihvatanja nul hipoteze, odbacićemo je kao lažnu.
Primjer 1:
U želji da provjerimo istinitost podatka da je proporcija turista u jednoj regiji
mlađih od 30 godina jednaka 0,48, izabrali smo uzorak na slučajan način 300 turista i
ustanovili da u uzorku ima 135 osoba mlađih od 30 godina.provjeru tvrdnje ćemo izvršiti na
nivou 4,04% signifikantnosti.
Prvo moramo postaviti nul i alternativnu hipotezu.
H
0
......p =0,48
H
1
......p
≠
0,48
U uzorku smo izabrali 300 elemenata(n=300), od 300 izabranih turista 135 je mlađe od
30godina.što znači da je m=135.proporcija turista mlađih od 30 godina u uzorku je:
p=
m
n
=
135
300
=0,45
Proporcije turista koji nisu mlađi od 30 godina:
q=1-p=1-0,45=0,55
Standardnu grešku računamo na sljedeći način:
σ
^
p
=
√
pq
n
−
1
=
√
0,2475
299
=
√
0,000828
Koeficijent pouzdanosti „z“ za 4,040% signifikantnosti iznosi 2,05.
Prvi test:
z=
p
−
p
0
σ
^
p
=-
1,035
σ
^
p

148
Primjer 1:
Postoji tvrdnja da je više od ¾ mladih regiona zainteresovano za izgradnju jednog
rekreativnog objekta.Izabran je uzorak od 300 mladih, od ukupnog broja njih je 240
zainteresovano za izgradnju tog centra.Provjerićemo tvrdnju na nivou 2,5% signifikantnosti.
Hipoteza glasi:
H
0
p
≤
0,75
H
1
p
¿
0,75
Broj elemenata u uzorku n=300
Broj zainteresovanih u uzorku m=240
Proporcija zainteresovanih u uzorku: p=
m
n
=
240
300
=0,8
Proporcija nezainteresovanih u uzorku :
Q=1-p = 1-0,8=0,2
Standardna greška procjene proporcije osnovnog skupa:
σ
^
p
=
√
pq
n
−
1
=
√
0,8
x
0,2
300
−
1
=
√
0,000535
Koeficijent pouzdanosti za 2,5%signifikantnosti u testu na jednu granicu iznosi 1,96
Gornja granica prihvatanja nul hipoteze:
p
0
+
¿
z
σ
^
p
0,75+1,96x0,023
0,75+0,045
0,795
Proporcija izračunata u uzorku, veća je od gornje granice prihvatanja nul hipoteze, pa nul
hipotezu odbacujemo kao lažnu.Prema tome je više od ¾ mladih zainteresovano za izgradnju
tog centra.
5.0.7.Testiranje hipoteza o jednakosti proporcija dvaju osnovnih skupova
.
Testiranje hipoteze o jednakosti proporcija dva osnovna skupa sprovodi se na isti način kao i
testiranje hipoteze o jednakosti aritmetičkih sredina dva osnovna skupa.
Hipoteze za test su:
149
H
0
......
p
1
-
p
2
=0
H
1
......
p
1
-
p
2
≠
0
Donja i gornja granica prihvatanja nul hipoteze je:
0
± z σ
p
1
−
¿
p
2
¿
Standardna greška razlike proporcija data je izrazom:
σ
p
1
−
¿
p
2
¿
=
√
^
p
^
q
(
1
n
1
+
1
n
2
)
;
^
p
=
m
1
+
m
2
n
1
+
n
2
=
n
1
^
p
1
+
n
2
^
p
2
n
1
+
n
2
^
q
=1-
^
p
Iz prvog osnovnog skupa izabraćemo uzorak veličine
n
1
.Prebojimo koliko ima od izabranih
elemenata obilježje koje nas zanima.Taj broj u prvom uzorku označavamo sa
m
1.
Stavimo u
odnos
m
1
prema
n
1
i izračunati proporciju
^
p
1
u prvom uzorku.I sve ćemo to ponoviti i na
drugom odnovnoms skupu.te ćemo vrijednosti uvrstiti u formulu za standardnu grešku
proporcija
σ
p
1
−
¿
p
2
¿
.
Vrijednost standardne greške množimo sa vrijednosti z =
p
1
−
p
2
σ
p
1
−
¿
p
2
¿
i izračunatu
gornju i donju granicu intervala prihvatanja nul hipoteze.Ako se razlika među proporcijama
uzoraka uklapa u područje prihvatanja nul hipoteze, prihvatićemo je kao moguću, u
suprotnom ćemo je odbaciti kao lažnu.
Primjer 1:Možemo ustanoviti da su proporcije muških studenata na Pravnom i Ekonomskom
fakultetu jednake.na Pravnom smo izabrali za uzorak 150 studenata.U tom uzorku smo
izabrali 69 muškaraca.na Ekonomskom fakultetu izabrali smo uzorak 184 studenta.među
njima je bilo 97 muškaraca.
Provjeićemo trvrdnju na nivou 3,4%signifikantnosti.Nul i alternativna hipoteza glasi:
H
0
......
p
1
-
p
2
=0
H
1
......
p
1
-
p
2
≠
0
Po nul hipotezi su proporcije muških studenata na dva fakulteta jednake.po alternativnoj
hipotezi su ove proporcije različite:
Proporcija muškaraca na Pravnom fakultetu:
p
1
=
m
1
n
1
=
69
150
=0,46
Proporcija muškaraca na Ekonomskom fakultetu:
p
2
=
m
2
n
2
=
97
184
=0527

151
p
1
=
m
1
n
1
;
p
2
=
m
1
n
1
.............
p
k
=
m
k
n
k
Procjenjenu proporciju osnovnog skupa za primjenu
χ
2
testa označavamo sa
^
p
.Ona nam je
potrebna za računanje očekivanih (teoretskih izračunatih) vrijednosti.
^
p
=
n
1
p
1
.
⋯ ⋯
+
n
k
p
k
n
1
+
⋯ ⋯
n
k
=
m
1
⋯ ⋯
m
k
n
1
+
⋯ ⋯
n
k
Procjenjena prosječna proporcija osnovnog skupa izračunava se kao vagana aritmetička
sredina proporcija uzorka.
Kada znamo prosječnu proporciju uzoraka ili procjenjenu proporciju osnovnog skupa ,
možemo izračunati koliki broj elemenata možemo očekivati u uzorku za slučaj da je nul
hipoteza moguća.Očekivane ili izračunate frekvencije označavamo sa
e
i .
e
1
=
n
1
^
p
;
⋯ ⋯
e
k
=
e
k
^
p
Testom se ispituje razlike između opaženih(originalnih) i očekivanih (izračunati)
frekvencija.Ako su razlike male , smatramo ih slučajnim., ako su razlike velike , smatramo ih
značajnim.
Da li su razlike male ili velike odgovara nam izračunata vrijednost
χ
2
.
χ
2
=
∑
i
=
1
k
¿¿¿
gdje je:
m
i
-originalne , opažene frekvencije
e
i
-izračunate, očekivane frekvencije
k-
broj osnovnih skupova
S obzirom da suma originalnih vrijednosti mora biti jednaka sumi očekivanih vrijednosti,
gubi se jedan stepen slobode pa se test provodi sa k-1 stepeni slobode.
Akoje izračunata vrijednost
χ
2
testa veća od tablične vrijednosti , nul hipoteza se odbacuje
kao lažna i obrnuto, ako je izračunata vrijednost
χ
2
manja od tablične vrijednosti, nul hipotezu
prihvatamo kao moguću.
Primjer 1:
Treba da provjerimo da li se proporcija neispravnih proizvoda kreće ravnomjerno
kroz sve dane u sedmici.svakog radnog dana izabrali smo za uzorak određen broj proizvoda,
kontrolisali kvalitet i dobili sljedeće.
152
Dani
sedm.
Broj
kontro.
proizvoda
Neisp.
proizvoda
Proporcija u
uzorku
Očekivana
propor
n
i
m
i
^
p
i
e
i
m
1
−
¿
e
i
¿
¿
¿ ¿
Poned
Utora
Srijed
Četvrt
Petak
Subot
156
173
188
166
178
195
12
15
14
16
19
22
0,0769
0,0867
0,0745
0,0964
0,1067
0,1128
14,48
16,05
17,45
15,40
16,52
18,10
-2,58
-1,08
-3,45
0,60
2,48
3,90
6,1504
1,1025
11,9025
0,3600
6,1504
15,2100
0,425
0,069
0,682
0,023
0,375
0,840
1056
98
98
0
-
2,411
Prosječna proporcija neispravnih proizvoda u svim danima u sedmici je:
^
p
i
=
m
1
⋯ ⋯
m
k
n
1
+
⋯ ⋯
n
k
=
2293
3134
=
0,732
Izračunata vrijednost
χ
2
iznosi 2,411.U tablicama
χ
2
za 5 stepena slobode i 2,5%
signifikantnosti nalazimo broj 12,832.izračunata vrijednost se uklapa u tabličnu(ne prelazi),
nul hipoteza da je proporcija škart proizvodnje jednaka u svim danima sedmice prihvatamo
kao moguću na nivou 2,5% signifikantnosti.pri upoterebi
χ
2
ni jedna očekivana frekvencija ne
smije biti manja od 5, ako ima 1 stepen slobode.
5.0.9. Testiranje hipoteze da distribucija osnovnog skupa ima određeni oblik
Pretpostavimo određen oblik distribucije osnovnog skupa..Pri procjeni karakteristika
osnovnog skupa pomoću uzorka moramo ponekad pretpostaviti da osnovni skup ima oblik
normalne distribucije.U tom slučaju tu hipotezu i testiramo.
Iz osnovnog skupa izaberemo uzorak sa „
n“
elemenata, Distribucij afrekvencija uzoraka daje
opažene vrijednosti
m
i
Moramo izračunati kakve bi bile frekvencije uzoraka kada bi
distribucija uzorka imala oblik pretpostavljene distribucije u osnovnom skupu.To su
očekivane vrijednosti(
e
i
).Iz opaženih i očekivanih vrijednosti frekvencija možemo izračunati
χ
2
.
Pomoću tabele F odredimo tabličnu vrijednost
χ
2
za broj stepena slobode koji pripada
određenoj pretpostavljenoj distribuciji.
Primjer 1:
Kvalifikaciona struktura zaposlenih u regiji je jednaka strukturi navedenoj u tabeli.
Kvalif
Struktura
Zaposlen
Struktura
u uzorku
Očekivana
proporcija
n
i
m
i
e
i
m
1
−
¿
e
i
¿
¿
¿ ¿
VSS
SSS
16%
18%
30
50
40
45
-10
5
100
25
2,50
0,56

154
Te vrijednosti računamo pomoću izraza:
e
ij
=
m
i ∙
m
j
n
tako izračunate vrijednosti „očekivane „su frekvencije
e
ij
.Izračunati
χ
2
možemo:
χ
2
=
∑
i
=
1
r
∑
j
=
1
c
¿¿¿¿
Da bi mogli odrediti tablični
χ
2
, moramo odrediti nivo signifikantnosti na kojoj ćemo testirati
i odrediti broj stepena slobode.U tabeli koja ima
r
redova i
c
kolona , pa je broj polja
r
∙ c
,
to
znači toliko je očekivanih frekvencija.
Ukoliko od ukupnog broja
r
∙ c
polja odbijemo jedan stepen slobode za datu veličinu uzorka, jer
zbir očekivanih frekvencija mora biti jednak zbiru originalnih frekvencija, dobićemo traženi
broj stepena slobode:
(r-1)(c-1).
Primjer 1:
Možemo istražiti da li postoji zavisnost između starosti i kvalifikacione strukture
zaposlenih u nekoj radnoj organizaciji.Izabrali smo uzorak od 400 zaposlenih, grupisali ih
prema obilježju kvalifikacija i dobi, i dobili sljedeće:
Godine
života
Kvalifikacije
Ukupno
NKV i PKV
KV
VKV
Ostali
20-30
30-40
40-60
10
20
10
20
30
30
45
90
25
45
60
15
120
200
80
Ukupno
40
80
160
120
400
Očekivane frekvencije
e
ij
prve kolone:
40
x
120
400
=
12
40
x
200
400
=
20
40
x
80
400
=8
Očekivane frekvencije druge kolone:
80
x
120
400
=24
80
x
200
400
=40
80
x
80
400
=16
Kada smo izračunali očekivane vrijednosti računamo razliku između odgovarajućih
originalnih i očekivanih frekvencija
m
ij
−
¿
e
ij
¿
155
Godine
života
Kvalifikacije
Ukupno
NKV i PKV
KV
VKV
Ostali
20-30
30-40
40-60
-2
0
-2
-4
-10
14
-3
10
-7
9
0
-9
0
0
0
Ukupno
0
0
0
0
0
Kvadriramo izračunate razlike
¿
.
Godine
života
Kvalifikacije
NKV i PKV
KV
VKV
Ostali
20-30
30-40
40-60
4
0
4
16
100
196
9
100
49
81
0
81
I konačno računamo
χ
2
=
∑
i
=
1
r
∑
j
=
1
c
¿¿¿¿
Godine
života
Kvalifikacije
Ukupno
NKV i PKV
KV
VKV
Ostali
20-30
30-40
40-60
0,33
0
0,5
0,67
2,50
12,25
0,19
1,25
1,53
2,25
0,00
3,38
3,44
3,75
17,66
Ukupno
0,83
15,42
2,97
5,63
24,85
Broj stepena slobode za 3 reda i 4 kolone:
(r-1)(c-1)=(3-1)(4-1)=2x3=6
Tablična vrijednost za
χ
2
za 6 stepena slobode i 5% signifikantnosti je 12,6, pošto je
izračunata vrijednost veća od tablične, nul hipotezu odbacujemo kao lažnu.postoji zavisnost
između obilježja, kvalifikacija je zavisna od starosti i obrnuto.Kolika je jaka ta zavisnost.Na
to pitanje će nam odgovoriti
koeficijent kontigense
i računa se po sljedećoj formuli:
C=
√
χ
2
χ
2
+
n
Ako nema zavisnosti među obilježjima, koeficijent kontigense je nula.Najveća vrijednost
ovog koeficijenta zavisi od broja kolona u tabeli kontingense, ali nikada nije veća od