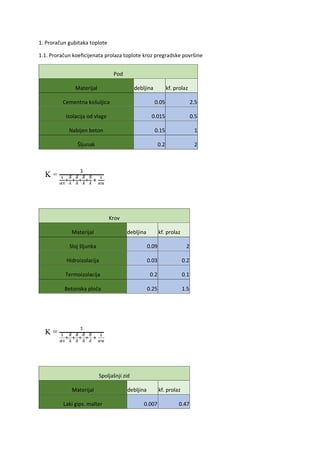
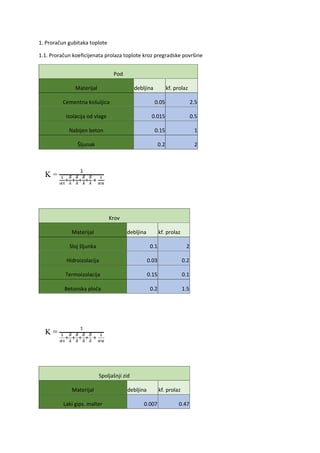
Teorija informacija i kodova
Prvi čas
1.1. Osnovni elementi teorije vjerovatnoće
Na samom početku, ukratko ćemo predstaviti osnovne elemente teorije vjerovatnoće, koji će biti
korišćeni u kursu. Napomenimo da ćemo ovdje već pomenuti neke pojmove kao što su
signal
i
informacija
i koji će biti definisani u narednoj lekciji. Pretpostavimo da u električnom kolu jedino
stanje koje se može pojaviti u nekom čvoru je 5V. To stanje onda nije neodređeno i ako apriori
znamo da je u toj tački napon 5V mjerenje ne moramo ni obaviti. U rječniku teorije informacija
kaže se da ovo stanje ne nosi informaciju.
Ako postoji mogućnost da u pomenutoj tački postoji vrijednost 0V i 5V postoji potreba da se izvrši
mjerenje i da se "ukine neodređenost" o vrijednosti stanja. Sada vrijednosti 0V možemo pridružiti
vrijednost 0 i vrijednost 5V pridružiti vrijednost 1 u binarnoj aritmetici. Za ovu operaciju se kaže da
smo kodirali stanje (poruku).
Dalje, posmatrajmo mogućnost da imamo trideset mogućih naponskih stanja 0V, 1V, 2V, ... 29V
kojima možemo pridružiti slova naše abecede A, B, C, ... Ž. Sada zamislimo da nam neko
mijenjajući stanje u tački kola prenosi poruku. Mi tu poruku možemo tumačiti mjerenjem napona u
pojedinim trenucima. Ova operacija se uslovno može zvati dekodiranje.
Da bi se način "prenosa" optimizovao (poboljšao) neophodno je odrediti prirodu poruke koja se
prenosi. Znači, mi očekujemo neku poruku nepoznate sadržine iz skupa svih poruka koje se na
našem jeziku mogu izgovoriti. Da bi tačno kvantifikovali mogućnost pojavljivanja nekog slova
koristimo pojam vjerovatnoće. Tako možemo reći da je vjerovatnoća pojavljivanja slova A u
ukupnom skupu slova u našem jeziku neka vrijednost. Očigledno je ta vrijednost veća nego
pojavljivanje slova Š. Da bi način mjerenja (odnosno prenosa informacija) podesili pravilno, trebalo
bi da nam mjerna skala oko vrijednosti napona koja daje slovo A, bude preciznija nego ona oko
slova Š. Isto se dešava kod prenosa informacija. Dakle, poznavanje vjerovatnoće pojavljivanja
nekog slova u poruci opredjeljuje performanse sistema. Sistem koji govori o porukama koje su
unaprijed nepoznate sadržine je "stohastički" ili slučajan. Suprotno od ovoga su deterministički
sistemi. Deterministički sistemi ne nose poruke i informacije, ali su lakši za analizu pa se stoga i u
mnogim oblastima koje se bave porukama koriste kao model. Teorija informacija i kodova međutim
polazi od slučajnih poruka sa određenom vjerovatnoćom pojavljivanja određenog simbola.
Drugi veoma značajan razlog za uvođenje pojmova teorije vjerovatnoće u teoriju informacija je
postojanje određenih vrsta smetnji koje se pri slanju, prenosu, prijemu i razumjevanju poruke mogu
dogoditi. Sve ove smetnje se na nekom nivou mogu opisati determinističkim zakonima. Međutim,
za dovoljno preciznu analizu dovoljne su procjene procesa koji dovode do smetnji. Takve procjene
ćemo nazivati šumovima. Važno je napomenuti da neke vrste šumova potiču od termičkog kretanja
elektrona, druge su izazvane atmosferskim procesima ili ljudskim aktivnostima. Međutim, mi u
ovom kursu nećemo razmatrati šum na fizičkom nivou već samo kao model.
Posmatrajmo sada sljedeći slučajni događaj: izbor jednog elementa iz konačnog skupa
X
koji se
sastoji od elemenata
x
i
X
,
i
=1,2,...,
N
. Ponavlja se veliki broj "izbora" iz skupa
X
. Neka je svaki
x
i
element "izvučen"
k
i
puta. Tada se može reći da je procjena vjerovatnoće pojavljivanja nekog
elementa iz skupa
X
jednaka:
1
gdje je:
k
1
+
k
2
+...+
k
N
=
K
. Ako je
K
veoma veliki broj (praktično beskonačan) nije više riječ o procjeni
vjerovatnoće pojavljivanja nekog elementa već o vjerovatnoći. Uvijek je sporno koliko je dobra
procjena vjerovatnoće događaja. Naime, za skup slova našeg jezika bi potpuno valjana procjena
obuhvatila sve što je ikada rečeno i napisano na našem jeziku. Čak ni takva procjena ne može nam
govoriti o kvalitetu mjerenja (određivanja neke poruke) jer npr. u poruci može biti izostavljen neki
često ponavljani karakter. U daljem tekstu mi ćemo podrazumjevati da su nam vjerovatnoće (a ne
procjene) apriori poznate. U nekim slučajevima ćemo se vratiti na problem procjenjivanja
vjerovatnoća. Srednja ili očekivana vrijednost koja opisuje događaj se određuje kao:
gdje je
f
(
x
i
) neka funkcionalna zavisnost od elemenata skupa
X
. Ako su elementi skupa
X
zapravo
numerički kvantifikovani (brojevi) tada se srednja vrijednost definiše kao:
Druga važna karakteristika koja se koristi zapisivanje slučajnih procesa je varijansa:
gdje je
srednja kvadratna vrijednost. Srednja vrijednost predstavlja mjeru najvjerovatnijeg
događaja dok varijansa predstavlja mjeru odstupanja od tog događaja.
Zapamtite. Suma vjerovatnoća svih događaja je 1. Vjerovatnoća nemogućeg događaja je 0.
Vjerovatnoća da slučajna promjenljiva uzme neke vrijednosti u skupu
Y
koji je podskup skupa
X
je
jednaka:
Mi ćemo informacije posmatrati skoro isključivo kao diskretne slučajne procese (slučajne procese
koji mogu uzeti vrijednost iz konačnog skupa vrijednosti). Pored ovakvih postoje i kontinualne
slučajne promjenljive, koje sa određenom vjerovatnoćom mogu uzeti neku vrijednost iz
kontinualnog intervala. U tom slučaju nema smisla govoriti o vjerovatnoći da događaj uzme
vrijednost 2, jer događaj može uzeti i vrijednost 2.01, 2.0000001, itd, odnosno vjerovatnoća
"uzimanja" jedne diskretne vrijednosti iz posmatranog skupa može se smatrati jednakom nula.
Stoga se uvodi pojam funkcije raspodjele. Ako je
slučajna promjenjiva, koja može uzeti bilo koju
vrijednost na intervalu od -
do
, tada se funkcija raspodjele definiše kao vjerovatnoća da događaj
uzme neku vrijednosti koja je manja od vrijednosti
x
:
Očigledno važe slijedeće relacije
i
kao i činjenica da je funkcija raspodjele
neopadajuća funkcija (kako vrijednost argumenta
x
raste, tako ova funkcija raste ili uzima
prethodnu vrijednost). Ova činjenica se može matematički zapisati kao
.
Druga izuzetno značajna funkcija koja se definiše kod kontinualnih slučajnih promjenljivih je
funkcija gustine vjerovatnoće:
2
Ako su
A
i
B
nezavisni tada važi
odnosno
.
Događaj “dogodili se i
A
i
B
” se često obilježava kao
AB.
Uočimo dalje da važi:
odnosno
Ako se u nekom trenutku može prenositi set simbola
B
i
,
i
=1,...,
N
, tada je vjerovatnoća događaja
A
jednaka:
Pa se Bayesovo pravilo može svesti na:
i opisuje aposteriori vjerovatnoću (vjerovatnoću ako već znamo da se dogodio događaj
A
kolika je
vjerovatnoća da ga je uzrokovao događaj
B
j
).
1.2. Višedimenzione slučajne promjenljive
Funkcija združene gustine raspodjele (združena raspodjele) slučajnih promjenljivih
i
se definiše
kao vjerovatnoća događaja {
x
y
} i označava se kao
P
(
x
;
y
)
. Marginalne funkcije se definišu kao
i
. Funkcija gustine raspodjele se definiše kao:
Za diskretnu dvodimenzionu slučajnu promjenljivu funkcija gustine raspodjele se definiše kao:
. Marginalne funkcije gustine raspodjele se dobijaju kao:
1.3. Slučajni procesi
Slučajni proces
(
t
,
s
) je funkcija koja preslikava prostor događaja u familiju vremenskih funkcija.
Ovo je proširenje pojma slučajne promjenljive, jer svakom od mogućih događaja (stanja ili ishoda)
umjesto broja pridružuje odgovarajuća vremenska funkcija. Skup svih mogućih vremenskih
funkcija se naziva
ansambl
, a pojedine funkcije su realizacije ili članovi ansambla.
Funkcija raspodjele slučajnog procesa
s
(
t
1
)=
s
1
se označava sa
.
Slučajan proces je stacionaran ako njegova raspodjela ne zavisi od pomjeraja duž vremenske ose:
Slučajni proces je stacionaran u širem smislu ako srednja vrijednost i varijansa procesa ne zavise od
vremenskog trenutka:
4
gdje je
autokorelaciona funkcija.
Očekivana vrijednost procesa predstavlja vremensku funkciju koja pokazuje koliko pojedine
realizacije iz ansambla imaju srednju vrijednost u ovom trenutku. Autokorelaciona funkcija
predstavlja srednju vrijednost proizvoda signala u dva različita vremenska trenutka.
Pored ovih veličina može se uvesti i srednja vrijednost slučajnog procesa unutar njegovog trajanja
za datu realizaciju:
Vremenska autokorelaciona funkcija
se definiše kao:
Srednja vrijednost po vremenu za generalizovanu autokorelaciju se označava kao:
Ako su sve srednje vrijednosti računate po ansamblu jednake svim srednjim vrijednostima
računatim po vremenu, proces se naziva ergodičnim. Svaki ergodični proces je stacionaran. Naime,
srednja vrijednost po vremenu ne zavisi od posmatranog vremenskog trenutka. Ako je proces
ergodičan to znači da ni srednja vrijednost po ansamblu (koja je jednaka srednjoj vrijednosti po
vremenu) ne zavisi od vremena. Ovo je osobina koja važi za stacionarne procese. Međutim,
stacionarnost ne implicira ergodičnost.
1.4. Spektralne karakteristike slučajnih procesa
Spektralna gustina snage slučajnog procesa
x
(
t
) se definiše kao:
gdje je:
Snaga slučajnog signala je jednaka:
Kako je spektralna gustina parna realna funkcija važi:
5
Ergodičan
Stacionaran
u širem
smislu
Stacionaran u
užem smislu
Odnosi između pojedinih
familija slučajnih procesa

1.6. Model sistema za prenos infomracija
Osnovni komunikacioni model za prenos informacija se može opisati sljedećim dijagramom. U
opštem slučaju izvor poruka može da proizvodi četiri tipa poruka: analogne; diskretne; kontinualne
sa diskretnim vrijednostima amplitude; digitalne.
Osnovni problem prilikom prenosa informacija je da se na nekoj tački tačno ili približno tačno
reproducira poruka odabrana u nekoj drugoj tački (C. Shannon 1948.god).
Mi ćemo posmatrati izvor digitalnih ili diskretnih podataka. Koder izvora teži da eliminiše koliko je
god moguće, redudanciju između podataka. Redudancija je nepotrebno ponavljanje informacija koja
je česta i u svakodnevnom životu. Npr. danas, 15.X.2004, srijeda, pada kiša. Ako je ova rečenica
izgovorena na dati datum onda je 15.X.2004 i srijeda redudantno sa riječju danas. Uklanjanje
redundancije se vrši u cilju kompresije podataka (smanjivanja broja podataka koji je neophodno
prenijeti kanalom). Koder kanala dodaje malu količinu redudancije u podatke da bi obezbjedio
mogućnost detekcije i korekcije grešaka iz podataka. Kanal je medijum preko kojeg se prenose
poruke. To može biti bilo koji put kojim poruke se mogu transportovati uključujući i magnetne
medije za smještaj poruka, generičke kanale, radio veze, radio relejne linkove, kompjutersku mreži,
satelitsku komunikacije, itd. Dekoder kanala vrši korekciju i detekciju grešaka, dekoder izvora vrši
operacije koje su neophodne da se dobija poruka u obliku prihvatljivom za korisnika.
Model sistema za prenos informacija može da uključi i neke druge blokova. Neki sistemi sadrže
blok koji predstavlja ograničenja koja su nametnuta tom kanalu, blok koji omogućuje kriptografiju i
dekripciju, blok koji vrši kompresiju sa gubicima. Ove teme se mogu ubrojati u one koje pokriva
teorija informacija i kodova, ali izlaze iz okvira ovog predmeta. Neke elemente ovih dodatnih
sistema ćete učiti iz nekih drugih predmeta. Od naredne lekcije ćemo učiti jedno od najvažnijih
pitanja teorije informacija, a to je kako mjeriti količinu informacije. Naredno pitanje je koliko i
kako možemo vršiti kompresiju. Dalje, kako možemo izbjeći greške koje se dešavaju u prenosu?
Koliko brzo možemo prenositi informacije u kanalu? itd. Ovo su samo neka od pitanja u teoriji
inforamcija i kodova, kojih ćemo se držati. Naravno, neka od ovih pitanja nijesu do kraja riješena i
predstavljaju i dalje važan teorijski problem, ali mi ćemo se zadržati na osnovnim rješenjima i dati
vam neophodno predznanje da vi možete sami da idete dalje kroz ovu ponekad komplikovanu
oblast. Posebno treba obratiti pažnu na činjenicu da sistemi postaju sve složeniji i ne mogu biti
razmatrani na intuitivan - empirijski način, već moraju biti posmatrano egzaktno matematički i
algoritamski.
Teorija informacija se može posmatrati kao fundament informacione revolucije koja je počela
krajem prošlog vijeka. Ako je kraj devetnaestog vijeka obilježila industrijska revolucija zasnovna
na zakonima statističke mehanike postojeća informatička revolucija je zasnovana na zakonima
teorije informacija. Fundamenti ove teorije su postavljeni od strane jednog čvojeka - Clauda
Shannona, koji je definisao sve fundamentalne zakone u ovoj teoriji počevši od 1948. godine. Neki
od fundamentalnih principa i teorijskih limita koje je on postavio osnova su ove naučne discipline.
Teorija je prednjačila za informatičkom revolucijom više desetina godina, što nije bio slučaj sa
industrijskom revolucijom. Učinak Shannona se stoga može mjeriti samo sa učinkom Anštajna u
fizici. Drugo važno ime u ovoj oblasti je ruski matematičar Kolmogorov koji je dao značajnu
matematičku podlogu. Na žalost, rezultati Kolmogorova su poznati na zapadu tek početkom
sedamdesetih godina. Drugi razlog zbog čega ovi rezultati nijesu direktno primjenjeni u teoriji
7