Електронски факултет
Александра Медведева 14, Ниш
Семинарски рад
Компресија података
применом Хафмановог кодирања
Ментор: Студенти:
Др Милош Радмановић Тамара Марјановић, 16685
Милош Лазовић, 16670
Ниш, новембар 2020. године
Компресија података применом Хафмановог кодирања
2
2. Статистичке методе
Компресија статистичким методама је заснована на статистици низа, где је број
појављивања сваког симбола или групе симбола израчунат у кораку препроцесирања a
затим се најкраћи кодови додељују симболима који се најчешће понављају како би се
смањила величина резулујућег кода.
Постоје ситуације када није могуће унапред обрадити податке и израчунати
редундансе сваког симбола. Код преноса података уживо, практично је немогуће
предвидети податке који следе, мада и у таквим ситуацијама могуће је применити
одговарајуће статистичке алгоритме. Такви алгоритми процесирају улазни ток
података x
1
, x
2
, … x
n
(симболи припадају коначном скупу симбола/коначној азбуци)
симбол по симбол и изводe декомпресију у две фазе:моделирање и кодирање. Током
фазе моделирања, статистички модел предвиђа вероватноћу дистрибуирања наредног
симбола xn на основу претходних x
1
, x
2
, … x
n-1
, већ процесираних симбола.
Особина статистичких метода је да користе кодове променљиве величине, такође,
познавајући унапред редундансу можемо користити различите технике како бисмо
оптимизовали процес кодирања. Различити алгоритми компресије који се заснивају на
статистичкој редунданси су:
Shannon-Fano-ово кодирање
Huffman-ово кодирање
Аритметичко кодирање
Хaфманова метода донекле је слична Шанон-Фано (Shannon-Fano) методи. Главна
разлика између две методе је у томе што Шанон-Фано конструише своје кодове од
врха до дна (од крајњег левог до крајњег десног бита), док Хaфман прави стабло кода
одоздо према горе (гради кодове здесна налево).
2.1 Основни концепти: ентропија и редунданса
Ентропија представља просечан најмањи број битова потребан за представљање сваког
симбола. Зависи од појединачних вероватноћа
P
i
и највећа је када су све n вероватноће
једнаке.
Шанонова ентропија поставља апсолутну границу најбоље могуће компресије без
губитака било какве комуникације, под извесним ограничењима: ако третирамо поруке
да су кодоване као низ независних случајних променљивих са истом расподелом, прва
Шенонова теорема показује да, у граничном случају, средња дужина најкраће могуће
репрезентације за кодовање порука у датом алфабету је њихова ентропија подељена са
логаритмом броја симбола у циљном алфабету.
Може да се дефинише као:
H =
− ∑ ?
?
???
2
?
?
?
1
Компресија података применом Хафмановог кодирања
3
Прва Шанонова теорема говори да порука од
n
симбола може да се компресује највише
до
n×H
битова, али не и више.
Редунданса се може дефинисати као разлика највеће могуће ентропије и стварне
ентропије:
R =
[ − ∑
?
?
???
2
?
?
?
1
]
− [−
∑
????
2
?] = ???
2
? +
∑
?
?
???
2
?
?
?
1
?
1
, ? =
1
?
Начин за тестирање потпуне компресије је услов да редундантност буде једнака нули:
???
2
? + ∑ ?
?
???
2
?
?
?
1
= 0
Пример:
Размотримо четири симбола а
1
, а
2
, а
3
и а
4
. Вероватноће појављивања симбола и
генерисани кодови су дати у таблици.
Ентропију рачунамо на следећи начин:
E = -( 0.49
×
log2(0.49) + 0.25
×
log2(0.25) + 0.25
×
log2(0.25) + 0.01
×
log2(0.01) ) = 1.57
Просечан најмањи број битова потребан за представљање сваког симбола је 1.57.
Просечна дужина симбола (у битовима) за прву и другу групу додељених кодова
рачунамо на следећи начин
:
G
1
= 1 × 0.49 + 2 × 0.25 + 3 × 0.25 + 3 × 0.01 = 1.77
G
2
= 2 × 0.49 + 2 × 0.25 + 2 × 0.25 + 2 × 0.01 = 2
R
1
= 1.77 - 1.57 = 0.2
R
2
= 2 - 1.57 = 0.43
Табела 1.
Већа редунданса указује на веће одступаље од теоретског максимума могуће
компресије, односно група кодова из прве групе је погоднија.
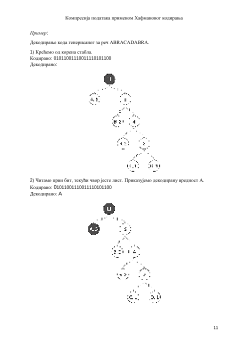
3. Хафманово кодирање
У области комуникација и рачунарске технике,
Хафманово кодирање
представља
алгоритам за кодирање симбола без губитка информација. Иако је Хафманово
кодирање врло ефикасно постоје алгоритми који користе релације између појединих
симбола и на тај начин побољшавају ефикасност алгоритма. Хафманов код се базира
на редунданси по којој се одређени карактери чешће јављају од осталих. Хафманови
кодови редукују број битова који се шаљу, али је код њих неопходно знати вредност
вероватноће појављивања.
Компресија података применом Хафмановог кодирања
5
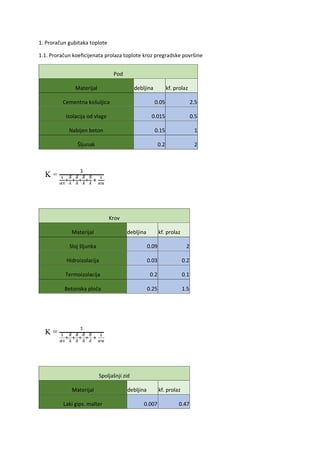
3) c се комбинује са b и оба се замењују комбинованим симболом чији је број
појављивања 25 (тј. учeсталост 0,25)
4)делимично стабло14 се комбинује са d и оба се замењују комбинованим симболом
чији је број појављивања 30 (тј. учeсталост 0,3)
5) делимично стабло 25 се комбинује са делимичним стаблом30 и оба се замењују
комбинованим симболом чији је број појављивања 55 (тј. учeсталост 0,55)
6) a се комбинује са делимичним стаблом 55 и добијамо коначно стабло (чијa је
учeсталост 1!)