OPTIČKI ČITAČ OBELEŽENIH OBRAZACA PREDNOSTI I MANE
Violeta Rašević, Visoka tehnološka škola strukovnih studija Šabac
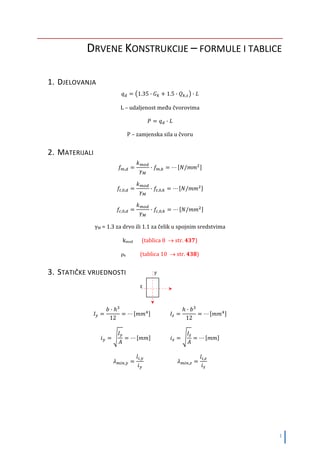
Sadržaj
–
Cilj ovog seminarskog rada je da se opiše
optički čitač obeleženih obrazaca (OMR) , njegovo
fukcionisanje kao i primeri za ove čitače.
Ključne reči
–
Optički čitač, OMR softver...
1. UVOD
U slučajevima kada je trošak pretvaranja podataka iz
izvornog dokumenta u oblik prikladan za ulaz u računar
velik, primenjuje se optički čitač znakova. On čita upisane
obeležene znakove. Ovako se najčešće obrađuju rezultati
raznih testova. Odgovori na postavljena pitanja se
obeležavaju. Dokument se skenira i identifikuje lokacija
obeleženih znakova. Brzina čitanja zavisi o vrsti i veličini
dokumenta, kao i o broju znakova koje treba pročitati, a
prednost je u manjoj pripremi obrazaca za čitanje.
Čitač obeleženih znakova poseduje fotoćeliju koja
usmerava impuls prema obeleženom mestu, koje ima
određeno značenje. Brzina čitanja iznosi oko 200 obrazaca
u minuti. Omogućuje čitanje i rukom pisanih znakova,
pisanih po određenim pravilima. Prikaz slova, pisanih za
optički čitač znakova omogućuje OCR softver (
Optical
Character Recognation
). Optički čitači mogu raditi kao
off-line
i on line ulazne jedinice, kada se unos obavlja na
magnetsku traku. Ovakvi uređaji čitaju alfanumeričke
znakove štampane pisaćom mašinom, te brojeve pisane
rukom po određenim pravilima za pisanje brojeva.
Pročitani znakovi se upoređuju s postojećim znakovima u
memoriji čitača, i ako ih čitač nađe, obavlja se čitanje i
unos podataka.
2. Čitač obeleženih obrazaca (OMR)
OMR (Optical Mark Recognition) algoritmi su
algoritmi za prepoznavanje markera. Pod markerom se
podrazumeva popunjen, prekrižen ili štikliran kružić,
kvadratić ili neka druga unapred definisana oblast na
dokumentu u papirnoj formi. Svaka od tih predefinisanih
oblasti na formi ima neko svoje značenje, a prisustvo ili
odsustvo markera znači afirmaciju ili negaciju tog
značenja. OMR algoritam detektuje prisustvo ili odsustvo
markera i informaciju o tome konvertuje u neki interni
podatak koji se koristi u daljoj obradi. Oblasti na kojima
se marker može pojaviti mogu imati različitu logiku:
jedna samostalna oblast,
više oblasti – moguće je markirati samo jednu
oblast (izbor jedne od vise mogućnosti),
više oblasti – nema restrikcija na markaciju
oblasti (izbor više mogućnosti).
Postoje dve osnovne realizacije OMR algoritama:
softverska rešenja, vrši se analiza digitalizovanih
slika dokumenata,
hardverska rešenja, tokom skeniranja dokumenata
vrši se analiza dokumenata I ekstrakcija podataka,
za razliku od prethodnog ne vrši se memorisanje
skeniranih slika dokumenata.
Dokument na kom se OMR algoritam primenjuje mora
imati unapred definisanu formu u terminima pozicije
oblasti za markiranje. Postoje pristupi koji se ne oslanjaju
na topološke karakteristike, već se oblasti markiranja
identifikuju prepoznavanjem oblika. Ovi pristupi su manje
efikasni i zahtevniji u kavalitetu skeniranja. Forma
dokumenta mora biti koncipirana tako da osoba koja
popunjava dokument može lako pratiti instrukcije za
popunjavanje dokumenta. Sadržaj popunjenog dokumenta
mora biti tačan i čitak. Na ovaj način se smanjuje nivo
mogućih grešaka. OMR algoritam se koristi svugde gde
postoji potreba za ekstrakcijom podataka sa dokumenta u
papirnoj formi, pri čemu osoba koja popunjava dokument
bira markiranjem između ponuđenih vrednosti podataka.
OMR algoritmi se koriste za ekstrakciju podataka sa
raznih anketnih listića, testova sa ponuđenim odgovorima,
glasačkih listića, prepoznavanje markiranih brojeva na
lutrijskim listićima…OMR algoritmi automatizuju
ekstrakciju odgovora sa papirnatih dokumenta i
transforimišu te podatke u elektronske. Zbog velike
primene i činjenice da problem nije u potpunosti rešen, tj.
ne postoji jedno opšte rešenje, ova oblast je izrazito
komercijalna. Primenjeni OMR algoritmi su deo strogo
čuvanih korporativnih tajni.
Slika 1.
Grafički prikaz prebacivanja podataka
3. Istorija ORM softvera
1
Optički prepoznavanje oznaka ( OMR ) je skeniranje
papira da otkriju prisustvo ili odsustvo znaka u unapred
određenom položaj. Optičko prepoznavanje oznaka je
evoluirao od nekoliko drugih tehnologija . U ranom 19.
veku i patenata 20. veka su dobili za mašine koji bi
pomogli slepe. OMR se sada koristi kao ulazni uređaj za
unos podataka . Dve rane forme OMR su papirne trake i
bušenih kartica koji koriste stvarne rupe buše u medijum
umesto olovke ispunjen krugovima na podlozi . Papir
traka je korišćen još u 1857 kao ulazni uređaj za telegrafa.
Punch kartice su stvoreni u 1890 i korišćeni su kao ulaznih
uređaja za računare . Upotreba bušenih kartica u velikoj
meri opao u ranim 1970-ih sa uvođenjem personalnih
računara .
Sa modernom OMR , gde se priznaje prisustvo
olovkom ispunjen u balon, priznavanje se vrši preko
optičkog skenera. Prvi znak je osećaj skener IBM- 805 test
Bodovanje mašina ; ovo čitaju znakove tako reaguje
električnu provodljivost grafitnom olovkom olova
koristeći parove Žičane četke koje skenirane stranice . U
1930 , Ričard Voren na IBM eksperimentisao sa optičkim
bod čulnih sistema za bodovanje testa , kao što je
dokumentovano u SAD patentima 2,150,256 ( podneta
1932 , odobreno u 1939 ) i 2,010,653 ( podneta 1933 ,
odobren 1935 ) . Prvi uspešan optički znak - osećaj skener
je razvijen od strane Everet Franklin Lindkuist kao
dokumentovano u US Patent 3,050,248 ( podneta 1955 ,
odobren 1962 ). Lindkuist su razvili brojne
standardizovane edukativne testove , a potreban bolji test
bodovanja mašinu od tada standardnog IBM- 805 . Prava
na Lindkuist patenata su održani od strane Istraživačkog
centra za merenje do 1968 , kada jeUniverzitet u Ajovi
prodate operaciju Vestinghouse Corporation .U istom
periodu , IBM je takođe razvila uspešnu optički znak -
sense - testa bodovanja mašina , kao što je dokumentovano
u US Patent 2,944,734 ( podneta 1957 , odobren 1960 ).
IBM- ovo komercijalizovan kao IBM 1230 optički čitač
bod postignutih u 1962 . Ovaj iniz sličnih mašina
dozvoljenih IBM-u da migriraju širok spektar aplikacija
razvijenih za svoj trag čulnih mašina do nove optičke
tehnologije. Ove aplikacije uključuju različite upravljanja
zalihama i problematičnim izveštavanja oblicima, od kojih
je većina imala dimenzije standard udario karticu. Dok su
ostali igrači u obrazovnom testiranje areni fokusiran na
prodaju usluga skeniranja , Scantron korporacija,
osnovana 1972 , je imao drugačiji model ; to bi
distribuirati jeftinih skenera školama i napravi profit od
prodaje forme testa. Kao rezultat toga, mnogi ljudi su došli
da se setim svih oblika znak – Sense ( bilo da je osetio
optički ili ne ) kao scantron oblicima . Scantron posluje
kao filijala M & F Vorldvide ( MFV ) [ 17 ] i obezbeđuje
testiranje i procenu sistema i usluga i usluge prikupljanja i
analize podataka u obrazovnim institucijama, preduzećima
i vladi. Godine 1983, Vestinghaus Učenje korporacija je
kupila nacionalnih Computer Sistems (NCS) . Godine
2000 , NCS je kupio Pearson Education, gde OMR
tehnologija formirala jezgro za upravljanje podacima
grupe Pearsonov . U februaru 2008 , M & F Vorldvide
kupio grupu za upravljanje podacima iz Pearson ; grupa je
sada deo Scantron brenda. OMR je korišćen u mnogim
situacijama kao što je navedeno u daljem tekstu . Upotreba
OMR u takvog sistema bio je prelaz između bušenih
kartica i bar kodova i ne koristi se kao mnogo za ovu
svrhu .
4. Upotreba
Upotreba OMR nije ograničena samo na školama ili
prikupljanje podataka agencijama, mnogi preduzeća i
zdravstvene agencije koriste OMR pojednostavile ulazne
podatke procese i smanji unos grešku. OMR, OCR, ICR i
tehnologije sve obezbeđuju sredstva za prikupljanje
podataka iz papirnih obrazaca. OMR se takođe može
uraditi pomoću OMR (diskretna čitanje glavu) skener ili
skener snimanja. U prošlosti i danas , neki sistemi
zahtevaju specijalni OMR papir, mastilo i poseban
poseban ulazni čitač. Ovo ograničava vrste pitanja koja
mogu biti postavljena i ne dozvoljava mnogo varijabilnosti
kada obrazac je bio ulaz . Napredak u OMR sada
omogućava korisnicima da kreiraju i štampaju sopstvene
oblike i koriste skener da pročitate informacije. Korisnik
je u mogućnosti da organizuje pitanja u formatu koji
odgovara njihovim potrebama , dok još uvek u stanju da
lako ulazni podaci. OMR sistemi pristupaju tačnost sto
odsto i samo uzeti .005 sekundi u proseku da prizna
maraka. Korisnici mogu da koriste kvadrate , krugove ,
elipse i heksagona za zonu marke . Softver se zatim može
podesiti da prepoznaju ispunjen u mehurima.
5. Dizajniranje svoje strane
Dizajnirajte svoj običaj OMR šablon odgovor
list. OMR Softver dizajn Za razliku od mnogih drugih
OMR softverskih paketa, FormReturn obuhvata vizuelni
odgovor listova predloška urednika. Kao što dizajn i
dodajte pitanja na stranici, vi se takođe postavljanje
definiciju imena polja i vrednosti. Jer mnogi drugi OMR
softverske pakete nemaju integrisani vizuelni editor, oni
zahtevaju da prvo dizajnirate obrazac, odštampajte ga,
skenira odštampane stranice i onda definišite stranicu iz
skenirane slike. FormReturn to radi u jednom koraku
umesto četiri. To štedi i dizajn šablona i definiciju kao
isto, za višekratnu upotrebu fajlu. Objavljivanje
novonastale predložak uzima snimak šablona koji ste
kreirali i čuva ga na FormReturn bazu podataka .
Izdavačka takođe stavlja barkod na svim stranama kako bi
se omogućilo da automatski identifikuje FormReturn
svaku stranicu koja se kasnije skeniranu in Each barkod
jeidentifikator strana u FormReturn bazu podataka.
Prilikom izdavanja, stranice može bitijedinstvena stranica
( ili više stranica ) za tuženog , koji identifikuje kako i
serije tuženom za stranice (Obrazac ID publikacije ) .
Takođe može da objavi jednu stranicu za serije koje ne
identifikuju jedinstveno tuženog ukoliko ne postoji ključ
polje ( kao što je studentski ID ) na stranici za njih da
označi kao identifikator (ključ polje miri objavljivanje).
Forma ID publikacije takođe omogućavaju vam da
unapred štampanje detalje primalaca na stranici , kao što
su ime primaoca . Oni takođe mogu da vam omogućiti da
2